每天5分钟玩转docker容器——读书笔记
这两天草草的过了一遍cloudman的《每天5分钟玩转容器技术》,巩固了一下docker的知识,并且学习到了不少新内容,对于docker的理解更加的深入了一些,特此记录一下在学习过程中比较在意的内容,以供以后翻阅。
容器runtime:runtime 是容器真正运行的地方。runtime 需要跟操作系统 kernel 紧密协作,为容器提供运行环境。
可以类比java,Java 程序就好比是容器,JVM 则好比是 runtime。JVM 为 Java 程序提供运行环境。同样的道理,容器只有在 runtime 中才能运行。

lxc、runc 和 rkt 是目前主流的三种容器 runtime。
容器管理工具:容器管理工具对内与 runtime 交互,对外为用户提供 interface,比如 CLI。

runc 的管理工具是 docker engine。docker engine 包含后台 deamon 和 cli 两个部分。我们通常提到 Docker,一般就是指的 docker engine。
容器定义工具:容器定义工具允许用户定义容器的内容和属性,这样容器就能够被保存,共享和重建。

docker image 是 docker 容器的模板,runtime 依据 docker image 创建容器。
dockerfile 是包含若干命令的文本文件,可以通过这些命令创建出 docker image。
容器编排引擎:所谓编排(orchestration),通常包括容器管理、调度、集群定义和服务发现等。通过容器编排引擎,容器被有机的组合成微服务应用,实现业务需求。

容器支持技术:被用于支持基于容器的基础设施。
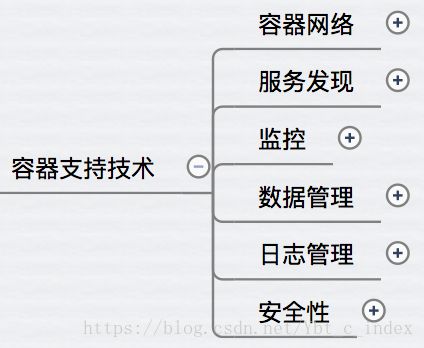
容器网络
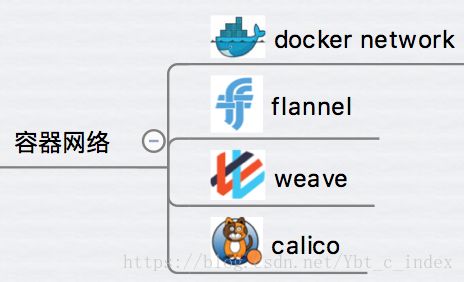
服务发现
动态变化是微服务应用的一大特点。当负载增加时,集群会自动创建新的容器;负载减小,多余的容器会被销毁。容器也会根据 host 的资源使用情况在不同 host 中迁移,容器的 IP 和端口也会随之发生变化。在这种动态的环境下,必须要有一种机制让 client 能够知道如何访问容器提供的服务。这就是服务发现技术要完成的工作。
服务发现会保存容器集群中所有微服务最新的信息,比如 IP 和端口,并对外提供 API,提供服务查询功能。
什么是容器?
容器是一种轻量级、可移植、自包含的软件打包技术,使应用程序可以在几乎任何地方以相同的方式运行。
容器由两部分组成:
- 应用程序本身
- 依赖:比如应用程序需要的库或其他软件
容器在Host操作系统的用户空间中运行,与操作系统的其他进程隔离。这一点显著区别于虚拟机。
Docker架构:
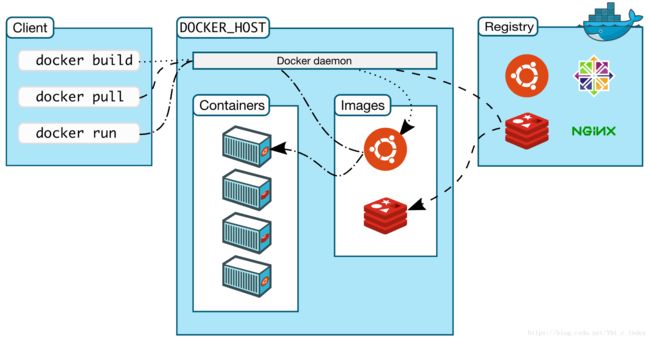
Docker 采用的是 Client/Server 架构。客户端向服务器发送请求,服务器负责构建、运行和分发容器。客户端和服务器可以运行在同一个 Host 上,客户端也可以通过 socket 或 REST API 与远程的服务器通信。
Docker客户端:最常用的 Docker 客户端是 docker 命令。通过 docker 我们可以方便地在 Host 上构建和运行容器。
Docker服务器:Docker daemon 是服务器组件,运行在 Docker host 上,负责创建、运行、监控容器,构建、存储镜像。默认配置下,Docker daemon 只能响应来自本地 Host 的客户端请求。如果要允许远程客户端请求,需要在配置文件中打开 TCP 监听。
Docker镜像:可将 Docker 镜像看着只读模板,通过它可以创建 Docker 容器。我们可以将镜像的内容和创建步骤描述在一个文本文件中,这个文件被称作 Dockerfile,通过执行 docker build 命令可以构建出 Docker 镜像。
Docker容器:Docker 容器就是 Docker 镜像的运行实例。用户可以通过 CLI(docker)或是 API 启动、停止、移动或删除容器。可以这么认为,对于应用软件,镜像是软件生命周期的构建和打包阶段,而容器则是启动和运行阶段。
base镜像:们希望镜像能提供一个基本的操作系统环境,用户可以根据需要安装和配置软件。这样的镜像我们称作 base 镜像:
- 不依赖其他镜像从scratch构建
- 其他镜像可以作为基础进行扩展
所以能称作 base 镜像的通常都是各种 Linux 发行版的 Docker 镜像比如 Ubuntu, Debian, CentOS 等。
Linux 操作系统由内核空间和用户空间组成。
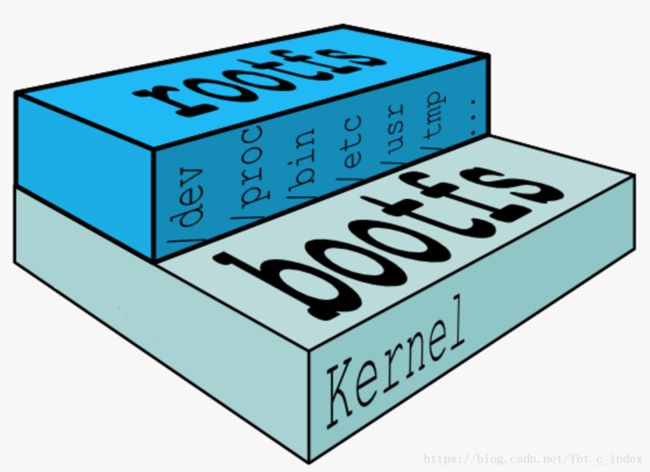
Linux 刚启动时会加载 bootfs 文件系统,之后 bootfs 会被卸载掉。用户空间的文件系统是 rootfs包含我们熟悉的 /dev, /proc, /bin 等目录。
对于 base 镜像来说底层直接用 Host 的 kernel自己只需要提供 rootfs 就行了。
base 镜像提供的是最小安装的 Linux 发行版。
不同 Linux 发行版的区别主要就是 rootfs。
比如 Ubuntu 14.04 使用 upstart 管理服务 , apt 管理软件包;而 CentOS 7 使用 systemd 和 yum。
所有容器都共用 host 的 kernel在容器中没办法对 kernel 升级。
新镜像是从 base 镜像一层一层叠加生成的。每安装一个软件,就在现有镜像的基础上增加一层。
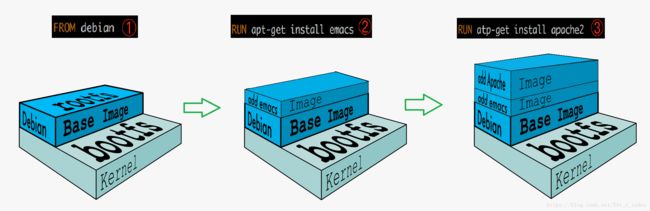
这种分层结构的最大好处就是:共享资源
容器 Copy-on-Write 特性:只有当需要修改时才复制一份数据,这种特性被称作 Copy-on-Write。
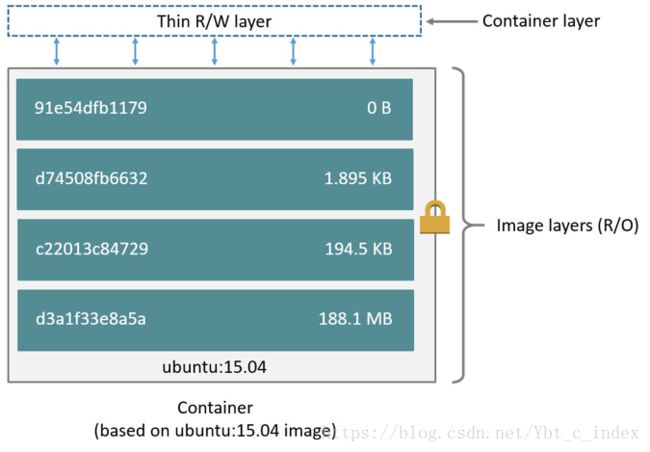
当容器启动时,一个新的可写层被加载到镜像的顶部。这一层通常被称作“容器层”,“容器层”之下的都叫“镜像层”。
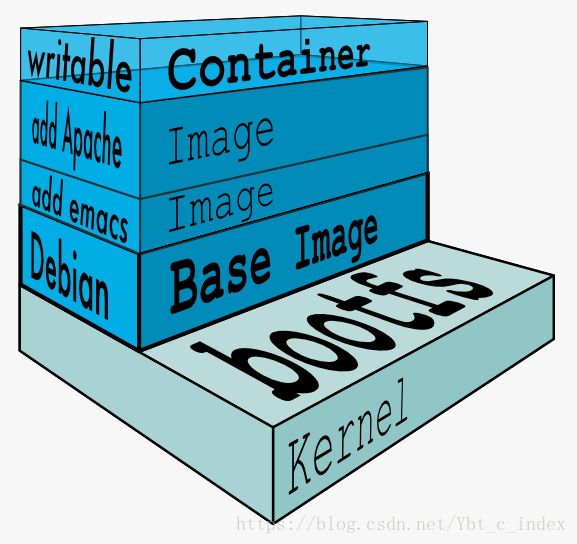
所有对容器的改动 - 无论添加、删除、还是修改文件都只会发生在容器层中。
只有容器层是可写的,容器层下面的所有镜像层都是只读的。
镜像层数量可能会很多,所有镜像层会联合在一起组成一个统一的文件系统。如果不同层中有一个相同路径的文件,比如 /a,上层的 /a 会覆盖下层的 /a,也就是说用户只能访问到上层中的文件 /a。在容器层中,用户看到的是一个叠加之后的文件系统。
- 添加文件:在容器中创建文件时,新文件被添加到容器层中。
- 读取文件:在容器中读取某个文件时,Docker 会从上往下依次在各镜像层中查找此文件。一旦找到,立即将其复制到容器层,然后打开并读入内存。
- 修改文件:在容器中修改已存在的文件时,Docker 会从上往下依次在各镜像层中查找此文件。一旦找到,立即将其复制到容器层,然后修改之。
- 删除文件:在容器中删除文件时,Docker 也是从上往下依次在镜像层中查找此文件。找到后,会在容器层中记录下此删除操作。
可见,容器层保存的是镜像变化的部分,不会对镜像本身进行任何修改。
容器层记录对镜像的修改,所有镜像层都是只读的,不会被容器修改,所以镜像可以被多个容器共享。
使用docker commits命令来创建新镜像(通过进入老镜像进行修改来构建新镜像) 不推荐
即便是用 Dockerfile(推荐方法)构建镜像,底层也是 docker commit 一层一层构建新镜像的。
docker build命令可以通过-f参数指定Dockerfile的位置。
镜像的构建过程:首先 Docker 将 build context 中的所有文件发送给 Docker daemon。build context 为镜像构建提供所需要的文件或目录。Dockerfile 中的 ADD、COPY 等命令可以将 build context 中的文件添加到镜像。
所以,使用 build context 就得小心了,不要将多余文件放到 build context,特别不要把 /、/usr 作为 build context,否则构建过程会相当缓慢甚至失败。
镜像的缓存:Docker 会缓存已有镜像的镜像层,构建新镜像时,如果某镜像层已经存在,就直接使用,无需重新创建。
但是注意:Dockerfile中每一个指令都会创建一个镜像层,上层是依赖于下层的。无论什么时候,只要某一层发生变化,其上面所有层的缓存都会失效。也就是说,如果我们改变Dockerfile 指令的执行顺序,或者修改或添加指令,都会使缓存失效。
调试Dockerfile:通过运行最新的镜像定位指令失败的原因。
Dockerfile的书写:点这;还有这
镜像tag的社区方案
假设我们现在发布了一个镜像 myimage,版本为 v1.9.1。那么我们可以给镜像打上四个 tag:1.9.1、1.9、1 和 latest。
这种 tag 方案使镜像的版本很直观,用户在选择非常灵活:
- myimage:1 始终指向 1 这个分支中最新的镜像。
- myimage:1.9 始终指向 1.9.x 中最新的镜像。
- myimage:latest 始终指向所有版本中最新的镜像。
- 如果想使用特定版本,可以选择 myimage:1.9.1、myimage:1.9.2 或 myimage:2.0.0。
搭建本地Registry:Here。
容器在 docker host 中实际上是一个进程,docker stop 命令本质上是向该进程发送一个 SIGTERM 信号。如果想快速停止容器,可使用 docker kill 命令,其作用是向容器进程发送 SIGKILL 信号。
--restart=always 意味着无论容器因何种原因退出(包括正常退出),就立即重启。该参数的形式还可以是 --restart=on-failure:3,意思是如果启动进程退出代码非0,则重启容器,最多重启3次。
有时我们只是希望暂时让容器暂停工作一段时间,比如要对容器的文件系统打个快照,或者 dcoker host 需要使用 CPU,这时可以执行 docker pause。处于暂停状态的容器不会占用 CPU 资源,直到通过 docker unpause 恢复运行。
使用 docker 一段时间后,host 上可能会有大量已经退出了的容器。这些容器依然会占用 host 的文件系统资源,如果确认不会再重启此类容器,可以通过 docker rm 删除。
如果希望批量删除所有已经退出的容器,可以执行如下命令:
docker rm -v $(docker ps -aq -f status=exited)顺便说一句:docker rm 是删除容器,而 docker rmi 是删除镜像。
与操作系统类似,容器可使用的内存包括两部分:物理内存和swap。通过-m 或 --memory:设置内存的使用限额;--memory-swap:设置 内存+swap 的使用限额。
通过 cpu share 可以设置容器使用 CPU 的优先级。
底层实现技术
cgroup 和 namespace 是最重要的两种技术。cgroup 实现资源限额, namespace 实现资源隔离。
cgroup 全称 Control Group。Linux 操作系统通过 cgroup 可以设置进程使用 CPU、内存 和 IO 资源的限额。
namespace 管理着 host 中全局唯一的资源,并可以让每个容器都觉得只有自己在使用它。换句话说,namespace 实现了容器间资源的隔离。
Linux 使用了六种 namespace,分别对应六种资源:Mount、UTS、IPC、PID、Network 和 User。
Mount namespace让容器看上去拥有整个文件系统。UTS namespace让容器有自己的 hostname。 默认情况下,容器的 hostname 是它的短ID,可以通过-h或--hostname参数设置。IPC namespace让容器拥有自己的共享内存和信号量(semaphore)来实现进程间通信,而不会与 host 和其他容器的 IPC 混在一起。- 容器中进程的 PID 不同于 host 中对应进程的 PID,容器中 PID=1 的进程当然也不是 host 的 init 进程。也就是说:容器拥有自己独立的一套 PID,这就是
PID namespace提供的功能。 Network namespace让容器拥有自己独立的网卡、IP、路由等资源。User namespace让容器能够管理自己的用户,host 不能看到容器中创建的用户。
Dockers提供几种原生网络,Docker安装时会自动在host上创建三个网络,分别为none、host、bridge。默认为bridge网络。
关于bridge的较详细介绍:Click Here。
除了 none, host, bridge 这三个自动创建的网络,用户也可以根据业务需要创建 user-defined 网络。Docker 提供三种 user-defined 网络驱动:bridge, overlay 和 macvlan。
容器之间可通过 IP,Docker DNS Server 或 joined 容器三种方式通信。
容器默认就能访问外部世界,这里指的是容器网络外的网络环境。
实现的原理是做了一次NAT,如下图:
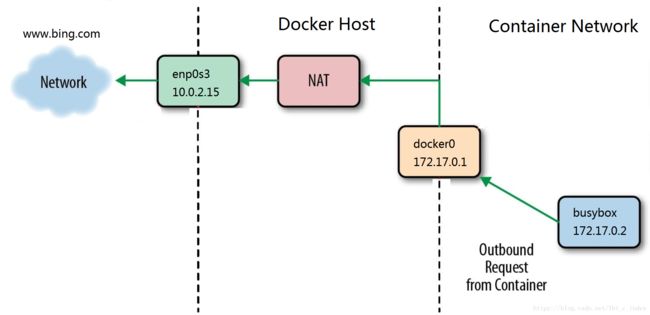
- busybox 发送 ping 包:172.17.0.2 > www.bing.com。
- docker0 收到包,发现是发送到外网的,交给 NAT 处理。
- NAT 将源地址换成 enp0s3 的 IP:10.0.2.15 > www.bing.com。
- ping 包从 enp0s3 发送出去,到达 www.bing.com。
而外部网络访问容器则是通过:端口映射。
每一个映射的端口,host 都会启动一个 docker-proxy 进程来处理访问容器的流量:

以 0.0.0.0:32773->80/tcp 为例分析整个过程:
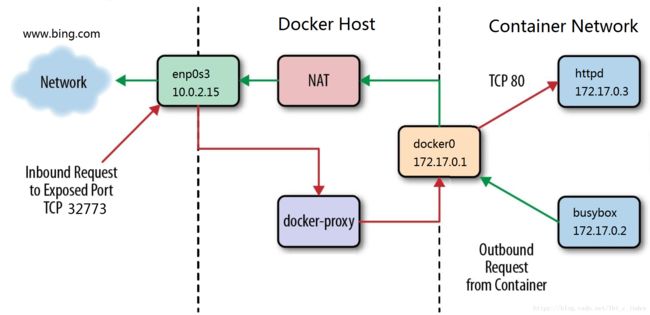
- docker-proxy 监听 host 的 32773 端口。
- 当 curl 访问 10.0.2.15:32773 时,docker-proxy 转发给容器 172.17.0.2:80。
- httpd 容器响应请求并返回结果。
Docker 为容器提供了两种存放数据的资源:
- 由 storage driver 管理的镜像层和容器层。
- Data Volume。
storage driver
分层结构使镜像和容器的创建、共享以及分发变得非常高效,而这些都要归功于 Docker storage driver。正是 storage driver 实现了多层数据的堆叠并为用户提供一个单一的合并之后的统一视图。
Docker 支持多种 storage driver,有 AUFS、Device Mapper、Btrfs、OverlayFS、VFS 和 ZFS。
优先使用 Linux 发行版默认的 storage driver。
对于某些容器,直接将数据放在由 storage driver 维护的层中是很好的选择,比如那些无状态的应用。无状态意味着容器没有需要持久化的数据,随时可以从镜像直接创建。
但对于另一类应用这种方式就不合适了,它们有持久化数据的需求,容器启动时需要加载已有的数据,容器销毁时希望保留产生的新数据,也就是说,这类容器是有状态的。这就要用到 Docker 的另一种存储机制:Data Volume。
Data Volume 本质上是 Docker Host 文件系统中的目录或文件,能够直接被 mount 到容器的文件系统中。Data Volume 有以下特点:
- Data Volume 是目录或文件,而非没有格式化的磁盘(块设备)。
- 容器可以读写 volume 中的数据。
- volume 数据可以被永久的保存,即使使用它的容器已经销毁。
docker 提供了两种类型的 volume:bind mount 和 docker managed volume。
bind mount:Here
docker managed volume:Here
两者的不同点:

共享数据我们可以使用volume container或data-packed volume container。
备份、恢复、迁移和销毁Data Volume:Click Here
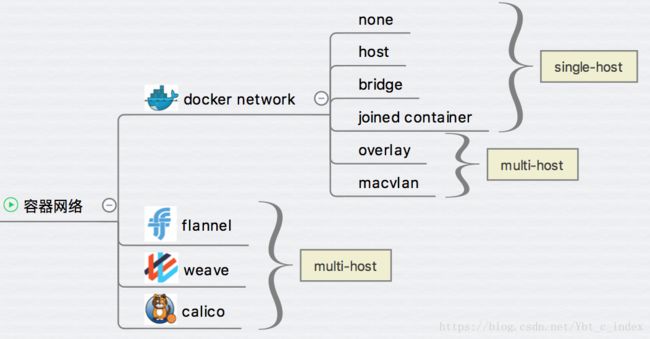
跨主机网络:Here
- docker 原生的 overlay 和 macvlan。
- 第三方方案:常用的包括 flannel、weave 和 calico。
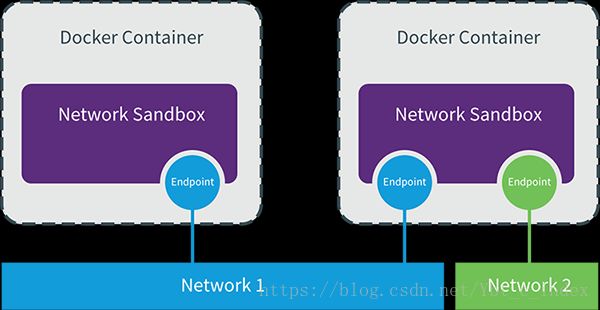
libnetwork 是 docker 容器网络库,最核心的内容是其定义的 Container Network Model (CNM),这个模型对容器网络进行了抽象,由以下三类组件组成:
- Sandbox 是容器的网络栈,包含容器的 interface、路由表和 DNS 设置。 Linux Network Namespace 是 Sandbox 的标准实现。Sandbox 可以包含来自不同 Network 的 Endpoint。
- Endpoint 的作用是将 Sandbox 接入 Network。Endpoint 的典型实现是 veth pair,后面我们会举例。一个 Endpoint 只能属于一个网络,也只能属于一个 Sandbox。
- Network 包含一组 Endpoint,同一 Network 的 Endpoint 可以直接通信。Network 的实现可以是 Linux Bridge、VLAN 等。
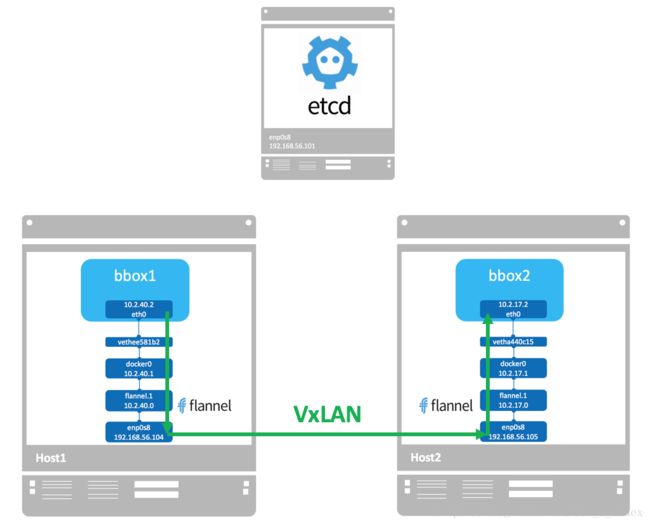
flannel 是 CoreOS 开发的容器网络解决方案。flannel 为每个 host 分配一个 subnet,容器从此 subnet 中分配 IP,这些 IP 可以在 host 间路由,容器间无需 NAT 和 port mapping 就可以跨主机通信。
每个 subnet 都是从一个更大的 IP 池中划分的,flannel 会在每个主机上运行一个叫 flanneld 的 agent,其职责就是从池子中分配 subnet。为了在各个主机间共享信息,flannel 用 etcd(与 consul 类似的 key-value 分布式数据库)存放网络配置、已分配的 subnet、host 的 IP 等信息。
使用flannel来进行跨主机通信的数据流向:
从业务数据的角度看,容器可以分为两类:无状态(stateless)容器和有状态(stateful)容器。
无状态是指容器在运行过程中不需要保存数据,每次访问的结果不依赖上一次访问,比如提供静态页面的 web 服务器。
有状态是指容器需要保存数据,而且数据会发生变化,访问的结果依赖之前请求的处理结果,最典型的就是数据库服务器。
简单来讲,状态(state)就是数据,如果容器需要处理并存储数据,它就是有状态的,反之则无状态。