关于训练时Loss值不变的情况分析
今天在搭建简单模型训练花数据的时候发现loss,始终为一个数。
loss:实际输出值和标签值之间的误差距离。在分类任务中,如何评判输出和期望之间的接近?
交叉熵:刻画了两个概率分布之间的距离。是分类问题中应用比较广的一种损失函数。
反向更新权重:有了损失函数,知道了实际输出和真实值之间的距离,用梯度求导更新权重。
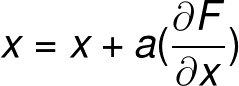
学习率:公式中的a就是学习率,表示的是每次权重更新的大小。
学习率设置:当学习率设置过大,x会在谷间震动,并没有更新。可以设置随着步伐增加,减小学习率。
import tensorflow as tf
import cv2 as cv
import numpy as np
filepath="/home/zw/数据集/flower_photos.tfrecords"
filequeue=tf.train.string_input_producer([filepath],shuffle=False)
reader=tf.TFRecordReader()
_,example=reader.read(filequeue)
features=tf.parse_single_example(
example,
features={
'image':tf.FixedLenFeature([],tf.string),
'label':tf.FixedLenFeature([],tf.int64),
})
image=features['image']
decode_image=tf.decode_raw(image,tf.uint8)
decode_image=tf.reshape(decode_image,[600,600,3])
img = tf.cast(decode_image, tf.float32) * (1. / 255) - 0.5
label = tf.cast(features['label'], tf.int64)
img_batch,labels_batch=tf.train.shuffle_batch([img,label],batch_size=20,capacity=160,min_after_dequeue=100)
with tf.variable_scope('conv1') as scop1:
w1=tf.get_variable('w1',[3,3,3,8],dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1,dtype=tf.float32))
b1=tf.get_variable('b1',shape=[8],dtype=tf.float32,initializer=tf.constant_initializer(0.1,dtype=tf.float32))
conv1=tf.nn.conv2d(img_batch,w1,strides=[1,2,2,1],padding='SAME')
pre_activate1=tf.nn.bias_add(conv1,b1)
relu1=tf.nn.relu(pre_activate1)
with tf.variable_scope('pooling5') as scop4:
pooling5=tf.nn.max_pool(relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
with tf.variable_scope('fc1') as scop5:
dim=pooling5.get_shape().as_list()
nodes=dim[1]*dim[2]*dim[3]
reshape = tf.reshape(pooling5, [dim[0],nodes])
wfc1=tf.get_variable('wfc1',shape=[nodes,1000],dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1,dtype=tf.float32))
bfc1=tf.get_variable('bfc1',shape=[1000],dtype=tf.float32,initializer=tf.constant_initializer(0.1,dtype=tf.float32))
fc1=tf.nn.relu(tf.matmul(reshape,wfc1)+bfc1)
with tf.variable_scope('fc3') as scop6:
wfc3=tf.get_variable('wfc3',[1000,5],dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1))
bfc3=tf.get_variable('bfc3',[5],dtype=tf.float32,initializer=tf.constant_initializer(0.1,dtype=tf.float32))
fc3=tf.nn.relu(tf.matmul(fc1,wfc3)+bfc3)
print(fc3)
with tf.variable_scope('loss') as scop7:
cross_entropy=tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels_batch,logits=fc3,name='xentropy_pre_example')
loss=tf.reduce_mean(cross_entropy)
with tf.variable_scope('optimizer') as scop8:
optimizer=tf.train.AdamOptimizer(learning_rate=0.00000001)
#global_step=tf.Variable(0,name='global_step',trainable=False)
train_op=optimizer.minimize(cross_entropy)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(sess=sess,coord=coord)
for i in range(2000):
lossed,trained=sess.run([loss,train_op],)
print(lossed)
coord.request_stop()
coord.join(threads)