在Windows平台安装Hadoop&&idea调试spark程序
使用idea可以方便的编译scala程序,只是在windows环境下,安装hadoop不太方便。
本文搜集了网上给的教程,整理出一些能解决问题的方法。
实验环境
- windows10;
- idea2019.1.3
- scala-sdk-2.11.0
- jdk1.8.0_201
- hadoop-2.7.1
- spark2.4.3
下载安装包
由于hadoop依赖于jdk,所以需要先安装配置jdk,具体下载地址如下:
jdk1.8.0_201
提取码:0vge
不知道orcle现在抽什么风呢,是怕别的语言对java产生影响还是咋地?下载jdk要注册,而且特别慢,太烦了。我将之前下载的存在了百度网盘,有需要的同学请自行下载。
hadoop-2.7.1
通过镜像下载自己需要的版本,速度挺快的。
自行安装jdk,记住安装目录。解压hadoop,可能需要管理员权限。
替换文件
原版的Hadoop不支持Windows系统,我们需要修改一些配置方便在Windows上运行.
下载hadooponwindows-master.zip并解压。
复制解压开的bin文件和etc文件到hadoop-2.7.3文件中,并替换原有的bin和etc文件
安装配置
配置环境hadoop,java变量
hadoop环境变量配置
- 右键单击我的电脑 –>属性 –>高级环境变量配置 –>环境变量 –> 单击新建HADOOP_HOME,如下图:
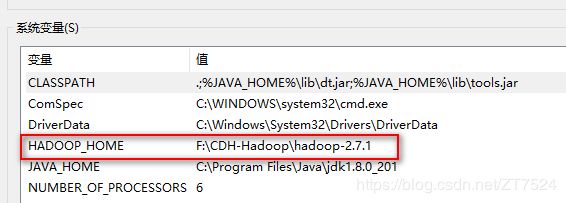
- 接着编辑环境变量
Path,双击后"新建”,后者“编辑文本”,如下所示: 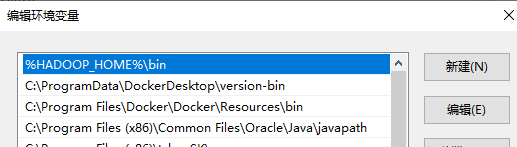
java环境变量配置
请自行百度
配置hadoop
- 1.编辑
F:\CDH-Hadoop\hadoop-2.7.1\etc\hadoop下的core-site.xml文件,将下列文本粘贴进去,并保存;
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
configuration>
- 编辑
F:\CDH-Hadoop\hadoop-2.7.1\etc\hadoop目录下的mapred-site.xml(没有就将mapred-site.xml.template重命名为mapred-site.xml)文件,粘贴一下内容并保存;
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
3.编辑F:\CDH-Hadoop\hadoop-2.7.1\etc\hadoop目录下的hdfs-site.xml文件,粘贴以下内容并保存。请自行创建data目录,在这里我是在HADOOP_HOME目录下创建了此目录;
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/F:/CDH-Hadoop/hadoop-2.7.1/data/namenodevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/F:/CDH-Hadoop/hadoop-2.7.1/data/datanodevalue>
property>
configuration>
- 编辑
F:\CDH-Hadoop\hadoop-2.7.1\etc\hadoop目录下的yarn-site.xml文件,粘贴以下内容并保存;
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
configuration>
- 编辑
F:\CDH-Hadoop\hadoop-2.7.1\etc\hadoop目录下的hadoop-env.cmd文件,将JAVA_HOME用 @rem注释掉,编辑为JAVA_HOME的路径,然后保存.
@rem set JAVA_HOME=%JAVA_HOME%
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_201
**注意:**如果路径中有Program Files,则将Program Files改为PROGRA~1
运行结果
- 运行cmd窗口,执行
hdfs namenode -format; - 运行cmd窗口,切换到hadoop的sbin目录,执行
start-all.cmd; - 运行
JPS,查看运行的服务;
23568 RemoteMavenS
32576 ResourceMana
35920 Jps
12420
23828
21896 NailgunRunne
33032 NodeManager
29388 NameNode
33708 DataNode
35340 Launcher
web 查看
1.资源管理GUI:http://localhost:8088/
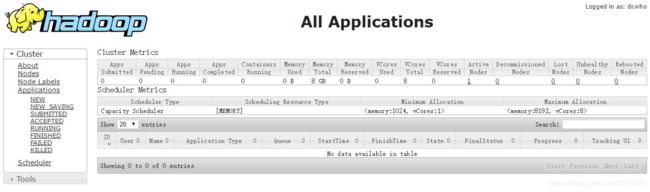
2. 节点管理GUI:http://localhost:50070/;
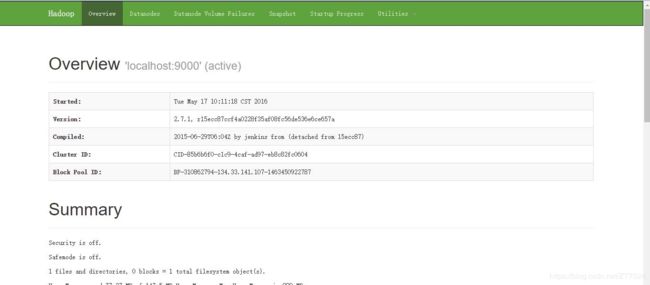
在idea中测试
配置好相关环境后,输入以下代码:
import org.apache.spark.sql.SparkSession
object Word {
def main(args: Array[String]): Unit = {
val logFile = "file:///D:\\Users\\dell\\IdeaProjects\\scalaTest\\data\\word.txt" // Should be some file on your system
val spark = SparkSession.builder.appName("Simple Application").getOrCreate()
val logData = spark.read.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
// println("hello world!")
spark.stop()
}
}
注意: 其中val logFile = "file:///D:\\Users\\dell\\IdeaProjects\\scalaTest\\data\\word.txt" 读取的是本地文件系统。
读取hdfs文件,以下三种方式等效。但是在windows环境下,好像只有第一种才能成功读取。
("hdfs://localhost:9000/user/hadoop/word.txt")
("/user/hadoop/word.txt")
("word.txt")
- 运行结果
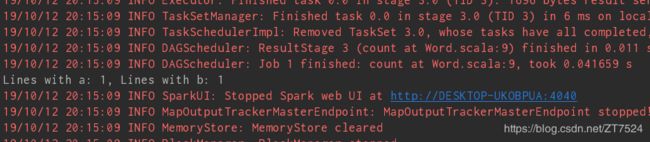
一些报错
A master URL must be set in your configuration错误
解决方案
主要参考文档
- 在Windows平台安装Hadoop(不借助cygwin)
- 【大数据】10分钟搞定Windows环境下hadoop安装和配置
谈风月之余谈技术,欢迎关注我的微信公众号
