Hive 索引
hive里的索引是什么?
索引是标准的数据库技术,hive 0.7版本之后支持索引。Hive提供有限的索引功能,这不像传统的关系型数据库那样有“键(key)”的概念,用户可以在某些列上创建索引来加速某些操作,给一个表创建的索引数据被保存在另外的表中。 Hive的索引功能现在还相对较晚,提供的选项还较少。但是,索引被设计为可使用内置的可插拔的java代码来定制,用户可以扩展这个功能来满足自己的需求。 当然不是说有的查询都会受惠于Hive索引。用户可以使用EXPLAIN语法来分析HiveQL语句是否可以使用索引来提升用户查询的性能。像RDBMS中的索引一样,需要评估索引创建的是否合理,毕竟,索引需要更多的磁盘空间,并且创建维护索引也会有一定的代价。 用户必须要权衡从索引得到的好处和代价。
Hive的索引目的是什么?
Hive的索引目的是提高Hive表指定列的查询速度。
没有索引时,类似'WHERE tab1.col1 = 10' 的查询,Hive会加载整张表或分区,然后处理所有的rows。但是如果在字段col1上面存在索引时,那么只会加载和处理文件的一部分。与其他传统数据库一样,增加索引在提升查询速度时,会消耗额外资源去创建索引和需要更多的磁盘空间存储索引。
Hive 0.7.0版本中,加入了索引。Hive 0.8.0版本中增加了bitmap索引。
如何在hive里创建索引?
说明:索引测试表是user,索引是user_index。
步骤一:先创建索引测试表
create table user( id int, name string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
步骤二:往索引测试表里导入数据
LOAD DATA LOCAL INPATH '/export1/tmp/wyp/row.txt' OVERWRITE INTO TABLE user;
步骤三:给索引测试表,创建索引之前测试
SELECT * FROM user where id =500000;
默认会去,加载整张表或分区,然后处理所有的rows。
Total MapReduce jobs = 1
Launching Job 1 out of 1
.......
Ended Job = job_1384246387966_0247
MapReduce Jobs Launched:
Job 0: Map: 2 Cumulative CPU: 5.63 sec
HDFS Read: 361084006 HDFS Write: 357 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 630 msec
OK
500000 wyp.
Time taken: 14.107 seconds, Fetched: 1 row(s)
可以看出,一共用了14.107s。
步骤四:对索引测试表,创建索引,即这里是在表的属性id上,创建索引
hive > CREATE INDEX user_index ON TABLE user(id) //索引一定是建立在某个属性或某些属性上的 > AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' > WITH deferred REBUILD > IN TABLE user_index_table;
或者
CREATE INDEX user_index ON TABLE user(id) AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' WITH deferred REBUILD IN TABLE user_index_table;
这样就对索引测试表user创建好了一个索引。索引名字为user_index。创建索引后的表命名为, user_index_table。
步骤五: 填充索引测试表的索引数据
ALTER INDEX user_index on user REBUILD;
步骤六:查看下创建索引后的表的内容
hive> SELECT * FROM user_index_table LIMIT 5;
0 hdfs://mycluster/user/hive/warehouse/table02/000000_0 [0]
1 hdfs://mycluster/user/hive/warehouse/table02/000000_0 [352]
2 hdfs://mycluster/user/hive/warehouse/table02/000000_0 [704]
3 hdfs://mycluster/user/hive/warehouse/table02/000000_0 [1056]
4 hdfs://mycluster/user/hive/warehouse/table02/000000_0 [1408]
Time taken: 0.244 seconds, Fetched: 5 row(s)
步骤七:对创建索引后的user再进行测试
hive> select * from user where id =500000;
在表user的字段id上面存在索引时,那么只会加载和处理文件的一部分。
Total MapReduce jobs = 1
Launching Job 1 out of 1
...
MapReduce Total cumulative CPU time: 5 seconds 630 msec
Ended Job = job_1384246387966_0247
MapReduce Jobs Launched:
Job 0: Map: 2 Cumulative CPU: 5.63 sec
HDFS Read: 361084006 HDFS Write: 357 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 630 msec
OK
500000 wyp.
Time taken: 13.042 seconds, Fetched: 1 row(s)
可以看出,明显加快了些。
扩展
若在Hive创建索引还存在bug:如果表格的模式信息来自SerDe,Hive将不能创建索引:
hive> CREATE INDEX employees_index > ON TABLE employees (country) > AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' > WITH DEFERRED REBUILD > IDXPROPERTIES ('creator' = 'me','created_at' = 'some_time') > IN TABLE employees_index_table > COMMENT 'Employees indexed by country and name.';
FAILED: Error in metadata: java.lang.RuntimeException: \
Check the index columns, they should appear in the table being indexed.
FAILED: Execution Error, return code 1 from \
org.apache.hadoop.hive.ql.exec.DDLTask
这个bug发生在Hive0.10.0、0.10.1、0.11.0,在Hive0.12.0已经修复了,详情请参见:https://issues.apache.org/jira/browse/HIVE-4251
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键。
Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapReduce任务中需要读取的数据块的数量。
在可以预见到分区数据非常庞大的情况下,索引常常是优于分区的。
博主我推荐各位博文们通过查阅Hive文档对Hive表的索引进行更深入的了解。
需要时刻记住的是,Hive并不像事物数据库那样针对个别的行来执行查询、更新、删除等操作。这些操作依赖高效的索引来实现高性能。
Hive是一种批处理工具,通常用在多任务节点的场景下,快速地扫描大规模数据。关系型数据库则适用于典型的单机运行、I/O密集型的场景。
Hive通过并行化来实现性能,因此Hive更适用于全表扫描这样的操作,而不是像使用关系型数据库一样操作。
为什么要创建索引?
Hive的索引目的是提高Hive表指定列的查询速度。
没有索引时,类似'WHERE tab1.col1 = 10' 的查询,Hive会加载整张表或分区,然后处理所有的rows,
但是如果在字段col1上面存在索引时,那么只会加载和处理文件的一部分。
与其他传统数据库一样,增加索引在提升查询速度时,会消耗额外资源去创建索引和需要更多的磁盘空间存储索引。
Hive 0.7.0版本中,加入了索引。Hive 0.8.0版本中增加了bitmap索引。
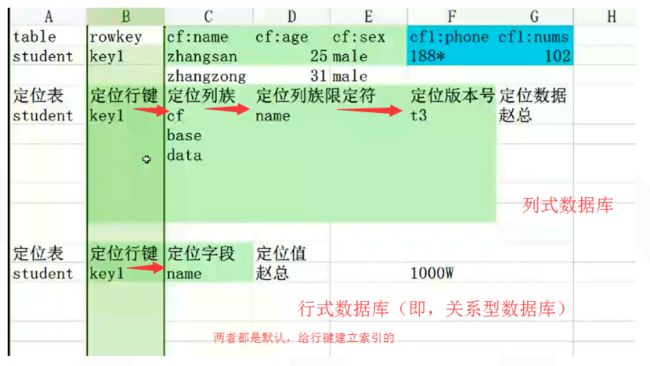
Hive里的2维坐标系统(第一步定位行键 -> 第二步定位列修饰符)
HBase里的4维坐标系统(第一步定位行键 -> 第二步定位列簇 -> 第三步定位列修饰符 -> 第四步定位时间戳)
HBase里的4维坐标系统(第一步定位行键 -> 第二步定位列簇 -> 第三步定位列修饰符 -> 第四步定位时间戳)
行键,相当于第一步级索引。
列簇,相当于第二步级索引。
列修饰符,相当于第三步级索引。
时间戳,相当于第四步级索引。
预习案例
说明:
原表是user
创建索引后的表是user_index_table
索引是user_index
先创建原表
create table user(
id int,
name string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
往原表里导入数据
LOAD DATA LOCAL INPATH '/export1/tmp/wyp/row.txt' OVERWRITE INTO TABLE user;
给原表做个测试
SELECT * FROM user where id =500000;
Total MapReduce CPU Time Spent: 5 seconds 630 msec
OK
500000 wyp.
Time taken: 14.107 seconds, Fetched: 1 row(s)
可以看出,一共用了14.107s。
在原表user上创建索引user_index,得到创建索引后的表user_index_table
CREATE INDEX user_index ON TABLE user(id) AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' WITH deferred REBUILD IN TABLE user_index_table;
或者如下写都是一样的,建议如下写
hive > create index user_index on table user(id)
> as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
> with deferred rebuild
> IN TABLE user_index_table;
给原表user更新数据
ALTER INDEX user_index on user REBUILD;
删除索引
DROP INDEX user_index on user;
查看索引
SHOW INDEX on user;
创建表和索引案例
步骤一:创建索引测试表
CREATE TABLE index_test(
id INT,
name STRING
)
PARTITIONED BY (dt STRING)
ROW FORMAT DELIMITED FILEDS TERMINATED BY ',';
说明:
创建一个索引测试表 index_test,dt作为分区属性,
“ROW FORMAT DELIMITED FILEDS TERMINATED BY ','” 表示用逗号分割字符串,默认为‘\001’。
步骤二:创建临时索引表
create table index_tmp(
id INT,
name STRING,
dt STRING
)
ROW FORMAT DELIMITED FILEDS TERMINATED BY ',';
说明:临时索引表是table index_tmp
步骤三:加载数据到临时索引表中
load data local inpath '/home/hadoop/djt/test.txt' into table index_tmp;
步骤四:设置 Hive 的索引属性来优化索引查询
set hive.exec.dynamic.partition.mode=nonstrict;----设置所有列为 dynamic partition
set hive.exec.dynamic.partition=true;----使用动态分区
步骤五:查询临时索引表中的数据,插入到索引测试表中。
insert overwrite table index_test partition(dt) select id,name,dt from index_tmp;
步骤六:使用 索引测试表,在属性 id 上创建一个索引
create index index1_index_test on table index_test(id) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' WITH DEFERERD REBUILD;
建议如下写
create index index1_index_test on table index_test(id)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
WITH DEFERERD REBUILD;
索引是index1_index_test
索引测试表是 index_test
在索引测试表的属性id上创建的索引
步骤七:填充索引测试表的索引数据
alter index index1_index_test on index_test rebuild;
步骤八:查看索引测试表的创建的索引
show index on index_test
步骤九:查看索引测试表的分区信息
show partitions index_test;
步骤十:查看索引测试表的索引数据
$ hadoop fs -ls /usr/hive/warehouse/default_index_test_index1_index_test_
步骤十一:删除索引测试表的索引
drop index index1_index_test on index_test;
show index on index_test;
步骤十二:索引测试表的索引数据也被删除
$ hadoop fs -ls /usr/hive/warehouse/default_index_test_index1_index_test_
no such file or directory
步骤十三:修改配置文件信息
hive.optimize.index.filter 和 hive.optimize.index.groupby 参数默认是 false。
使用索引的时候必须把这两个参数开启,才能起到作用。
hive.optimize.index.filter.compact.minsize 参数
为输入一个紧凑的索引将被自动采用最小尺寸、默认5368709120(以字节为单位)。