Hive语法(一)
HiveQL与关系型数据库的SQL 略有不同,但支持了绝大多数的语句如DDL、DML 以及常见的聚合函数、连接查询、条件查询。HIVE不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。
(一)表操作
建表规则:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], …)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], …)]
[CLUSTERED BY (col_name, col_name, …)
[SORTED BY (col_name [ASC|DESC], …)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
①CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXIST 选项来忽略这个异常。
②EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)。
③LIKE 允许用户复制现有的表结构,但是不复制数据。
④COMMENT可以为表与字段增加描述
⑤ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES
(property_name=property_value, property_name=property_value, …)]
ROW FORMAT DELIMITED 指定用户创建表加载数据时,支持的列分隔符。
用户在建表的时候可以自定义 SerDe (序列化 )或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive 通过 SerDe 确定表的具体的列的数据。
⑥STORED AS
SEQUENCEFILE
| TEXTFILE
| RCFILE
| INPUTFORMAT input_format_classname
OUTPUTFORMAT output_format_classname
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCE 。
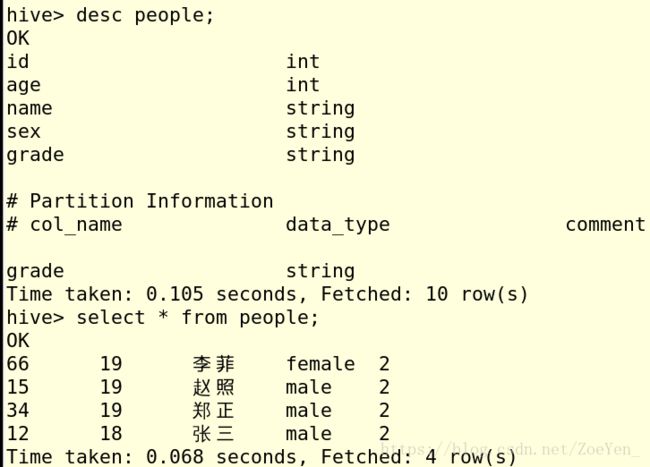
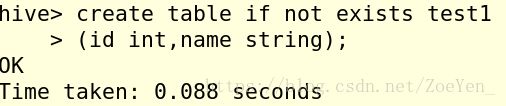
1.创建一个内部表student1

2.创建一个外部表teacher2

3.删除表
先创建一个test表
删除

4.改变表结构

5.改变表名

6.创建和已知表结构相同的表

7.加载数据
(1)加载本地数据
在本地创建一个student.txt文件,内容如下:

加载数据到student1表中
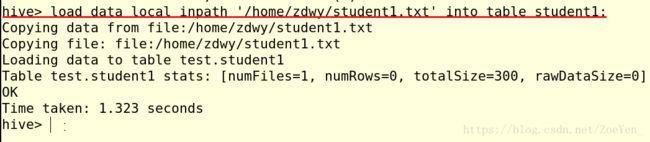
查看一下

(2)加载hdfs文件数据
将本地文件上传到hdfs文件系统

将hdfs文件数据导入表中

查看结果

8.表插入数据
(1)单表插入
创建一个和student1相似的表,查看该表的结构

将表student1的内容插入到新表中,并查看


(2)多表插入
创建两个新表

多表插入

查看结果

9.表内容查询
(1)查表的所有内容

(2)where条件查询
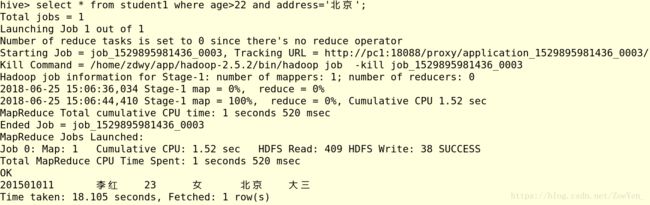
(3)查表的某个字段

(4)all和distinct关键字

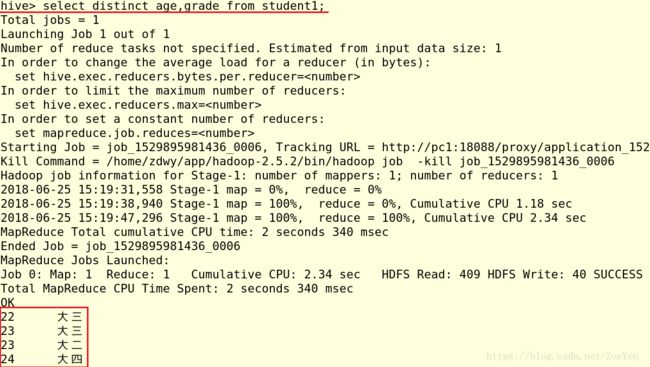
(5)limit关键字

10.group by 分组查询
创建一个表group_test,并且导入数据


计算表的行数

创建一个新表,将性别去重后的数据导入新表

insert overwrite table group_gender_sum select group_test.gender,count(distinct group_test.uid) from group_test group by group_test.gender;11.order by 排序查询

使用 ORDER BY 查询的时候,为了优化查询的速度,使用 hive.mapred.mode 属性,在 hive.mapred.mode=strict 模式下必须指定limit 。
12.sort by
不用limit限制
(二)视图操作
1.创建一个测试表。
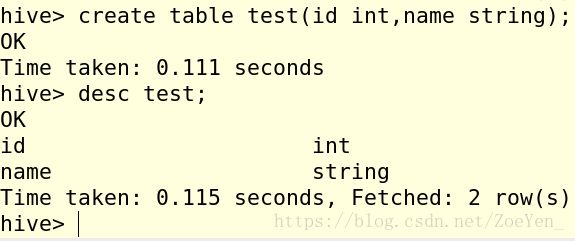
2.基于test表创建一个视图

(三)索引操作
1.创建索引

2.操作索引

3.创建一个索引测试表

4.创建一个临时索引表

5.加载本地数据到临时索引表

设置 Hive 的索引属性来优化索引查询
hive> set hive.exec.dynamic.partition.mode=nonstrict;----设置所有列为 dynamic partition
hive> set hive.exec.dynamic.partition=true;----使用动态分区6.查询index_tmp 表中的数据,插入 table_test 表中。

7.使用 index_test 表,在属性 id 上创建一个索引 index1_index_test 。
![]()
8.填充索引数据

9.查看创建的索引

10.查看分区信息。
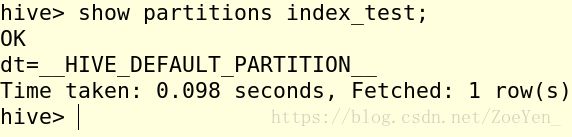
11.查看索引数据。

12.删除索引。

13.索引数据也被删除。

(三)分区操作
1.建分区表

这里出现了错误,由于在新建表的时候,并没有创建分区列address,所以只有在存在分区列的表上执行增加分区的操作,才会成功。
先创建分区列字段

使用分区

创建好分区,在对应的hdfs文件系统中可以找到新创建的分区。
2.插入数据
从student表中选取列插入分区表中
insert overwrite table partition_test partition(stat_date='2015-01-18',province='jiangsu') select member_id,name from partition_test_input where stat_date='2015-01-18' and province='jiangsu';(四)桶操作
Hive 中 table 可以拆分成 Partition table 和 桶(BUCKET),桶操作是通过 Partition 的 CLUSTERED BY 实现的,BUCKET 中的数据可以通过 SORT BY 排序。
BUCKET 主要作用如下。
1)数据 sampling(抽样);
2)提升某些查询操作效率,例如 Map-Side Join。

设置环境变量自动控制上一轮 Reduce 的数量从而适配 BUCKET 的个数

1.创建分桶表stu,并设置环境变量。
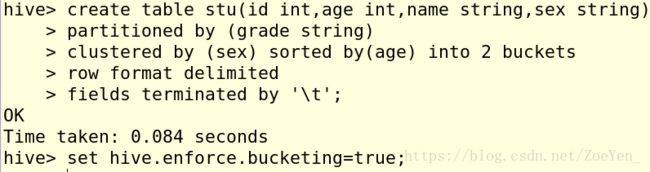
2.插入数据

3.查看