TensorFlow高层封装-Slim,Keras,Estimator
现在比较流行的tensorflow高层封装主要有4个,分别是Slim,TFLearn,Keras,Estimator.
使用tf.slim在MNIST数据集上实现LeNet-5模型
import tensorflow as tf
import tensorflow.contrib.slim as slim
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
def LeNet(input):
input = tf.reshape(input,[-1,28,28,1])
net = slim.conv2d(input,32,[5,5],stride=1,padding='SAME',scope='conv1')
net = slim.max_pool2d(net,2,stride=2,padding='VALID',scope='pool2')
net = slim.conv2d(net,64,[5,5],stride=1,padding='SAME',scope='conv3')
net = slim.max_pool2d(net,2,stride=2,padding='VALID',scope='pool4')
net = slim.flatten(net,scope='flatten')
net = slim.fully_connected(net,500,scope='fc5')
net = slim.fully_connected(net,10,scope='output')
return net
def train(mnist):
x = tf.placeholder(tf.float32,[None,784],name='x')
y_ = tf.placeholder(tf.float32,[None,10],name='y')
y = LeNet(x)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(y_,1))
loss = tf.reduce_mean(cross_entropy)
precision = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y,1),tf.argmax(y_,1)),tf.float32))
train_step = tf.train.GradientDescentOptimizer(0.003).minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(10000):
xs,ys = mnist.train.next_batch(100)
_,loss_val,accuracy = sess.run([train_step,loss,precision],feed_dict={x:xs,y_:ys})
if i % 100 == 0:
print('step : {},loss : {},accuracy : {}'.format(i,loss_val,accuracy))
def main(argv=None):
mnist = input_data.read_data_sets('MNIST_data',one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()
###使用keras在MNIST数据集上实现LeNet-5模型
步骤:定义一个Sequential类->通过add函数添加网络层->定义好网络结构->通过compile函数指定优化函数,损失函数,监控指标等->通过fit函数开始训练模型
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense,Flatten,Conv2D,MaxPooling2D
from keras import backend as K
import numpy as np
num_class = 10
img_size = 28
#若被墙,可以先下载好压缩包,使用下面的方法
# path = './mnist.npz'
# f = np.load(path)
# train_x, train_y = f['x_train'], f['y_train']
# test_x, test_y = f['x_test'], f['y_test']
# f.close()
#从mnist中加载数据
(train_x,train_y),(test_x,test_y) = mnist.load_data()
#根据图像编码的格式设置输入层的格式
if K.image_data_format() == 'channels_first':
train_x = train_x.reshape(train_x.shape[0],1,img_size,img_size)
test_x = test_x.reshape(test_x.shape[0],1,img_size,img_size)
input_shape = (1,img_size,img_size)
else:
train_x = train_x.reshape(train_x.shape[0], img_size, img_size,1)
test_x = test_x.reshape(test_x.shape[0], img_size, img_size,1)
input_shape = (img_size, img_size, 1)
#将像素转化为0-1之间的实数
train_x = train_x.astype('fl oat32')
test_x = test_x.astype('float32')
train_x /= 255.0
test_x /= 255.0
#将标签转化为one-hot类型
train_y = keras.utils.to_categorical(train_y,num_class)
test_y = keras.utils.to_categorical(test_y,num_class)
#定义模型,只需要将每一层add进模型即可
model = Sequential()
model.add(Conv2D(32,(5,5),activation='relu',input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64,(5,5),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(500,activation='relu'))
model.add(Dense(num_class,activation='softmax'))
#定义损失函数,优化函数,评测方法
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.SGD(),
metrics=['accuracy']
)
#训练模型,给定训练集和验证集
model.fit(train_x,train_y,batch_size=128,epochs=20,validation_data=(test_x,test_y))
#测试模型,给定测试集,获得测试数据
score = model.evaluate(test_x,test_y)
print('loss:',score[0])
print('accracy:',score[1])
使用keras实现RNN情感分析
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense,Embedding,LSTM
from keras.datasets import imdb
import keras
import numpy as np
import tensorflow as tf
max_features = 20000
max_len = 80
batch_size = 32
#若被墙,可以先将压缩包下载到本地,使用下面的方法读取数据
# path = './imdb.npz'
# f = np.load(path)
# train_x, train_y = f['x_train'], f['y_train']
# test_x, test_y = f['x_test'], f['y_test']
# f.close()
#x.shape=(25000,),表示25000个列表,每个列表含若干个数字,如[23,5423,321,33]
#每个数字代表一个单词,那么一组数字就代表一句话,
#数字大小代表单词出现的频率的排名,如数字1代表出现频率最高的单词
#max_featurs表示选取前20000个出现频率最高的单词,即单词的种类为20000个
#y.shape=(25000,),只含0和1,表示积极和消极
(train_x,train_y),(test_x,test_y) = imdb.load_data(num_words=max_features)
#maxlen表示每句话最多的单词数目,若超过maxlen,则剩下的单词将会截断,若少于maxlen,则用0来填充
#shape=[25000,80]
train_x = sequence.pad_sequences(train_x,maxlen=max_len)
test_x = sequence.pad_sequences(test_x,maxlen=max_len)
model = Sequential()
#Embedding将每个数字(单词)编码成一个大小为128的向量,其中input_dim是单词的种类数目
#输入shape=[25000,80],输出shape=[25000,80,128]
model.add(Embedding(input_dim=max_features,output_dim=128))
#输入shape=[25000,80,128],输出shape=[25000,80,128]
model.add(LSTM(128,dropout=0.2,recurrent_dropout=0.2))
#输入shape=[25000,80,128],输出shape=[25000,80,1]
model.add(Dense(1,activation='sigmoid'))
model.compile(
loss=keras.losses.binary_crossentropy,
optimizer=keras.optimizers.Adam(),
metrics=['accuracy']
)
model.fit(train_x,train_y,
batch_size=batch_size,
epochs=15,
validation_data=(test_x,test_y)
)
score = model.evaluate(test_x,test_y,batch_size=batch_size)
print('loss:',score[0])
print('accuracy',score[1])
Keras更加灵活的定义模型
import keras
from keras.layers import Input,Dense
from keras.models import Model
#除add方法外,还可一层一层定义并连接起来
#Input类似于placeholder,但不需要指定batch的大小
inputs = Input(shape=(784,))
x= Dense(500,activation='relu')(inputs)
predictions = Dense(10,activation='softmax')(x)
#定义好后输入到参数inputs和outputs中即可
model = Model(inputs=inputs,outputs=predictions)
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.SGD(),
metrics=['accuracy']
)
model.fit(trainX,trainY,
batch_size=128,
epochs=20,
validation_data=(testX,testY)
)
定义以下模型:
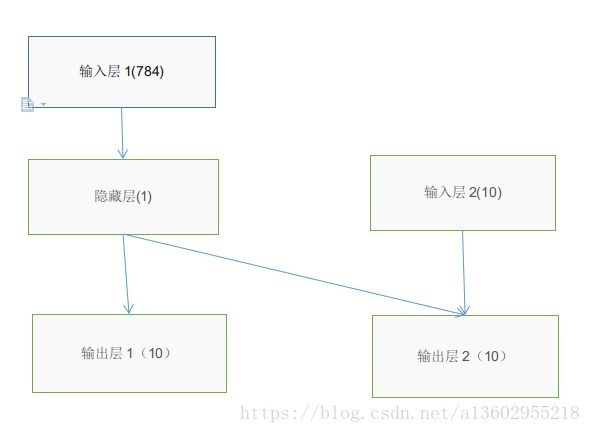
import keras
from keras.datasets import mnist
from keras.layers import Input,Dense
from keras.models import Model
(train_x,train_y),(test_x,test_y) = mnist.load_data()
input1 = Input(shape=(784,),name='input1')
input2 = Input(shape=(10,),name='input2')
x = Dense(1,activation='relu')(input1)
output1 = Dense(10,activation='softmax',name='output1')(x)
y = keras.layers.concatenate([x,input2])
output2 = Dense(10,activation='softmax',name='output2')(y)
#定义好多个input和output,并传入inputs和output2参数中
model = Model(inputs=[input1,input2],outputs=[output1,output2])
#loss_weights即每个output的loss的权重
model.compile(
loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.SGD(),
loss_weights=[1.,.1],
metrics=['accuracy']
)
#使用字典的方式为输入输出传入参数
model.fit(
x={'input1':train_x,'input2':train_y},
y={'output1':train_y,'output2':train_y},
batch_size=128,
epochs=20,
validation_data=([test_x,test_y],[test_y,test_y])
)
Estimator基本用法
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#日志输出到屏幕
tf.logging.set_verbosity(tf.logging.INFO)
mnist = input_data.read_data_sets('MNIST_data',one_hot=False)
#定义模型,这里定义一个全连接神经网络
#feature_columns是输入,是一个列表,最后会将列表中所有输入拼接在一起作为神经网络的输入
#hidden_units是神经网络的结构
#model_dir用于tensorboard可视化
estimator = tf.estimator.DNNClassifier(
feature_columns=[tf.feature_column.numeric_column('image',shape=[784])],
hidden_units=[500],
n_classes=10,
optimizer=tf.train.AdamOptimizer(),
model_dir='./log'
)
#定义输入以及相关训练步骤
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={'image':mnist.train.images},
y=mnist.train.labels.astype(np.int32),
num_epochs=None,
batch_size=128,
shuffle=True
)
#开始训练
estimator.train(input_fn=train_input_fn,steps=10000)
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={'image':mnist.test.images},
y=mnist.train.test.astype(np.int32),
num_epochs=None,
batch_size=128,
shuffle=True
)
#评估模型
accuracy = estimator.evaluate(input_fn=test_input_fn)['accuracy']
print(accuracy)