6. Hbase协处理器
6.1 协处理器简介
HBase作为列数据库,最经常被人诟病的特性包括:
1.无法轻易建立“二级索引”
2.难以执行求和、计数、排序等操作
比如,在旧版本的(<0.92)Hbase中,统计数据表的总行数,需要使用Counter方法,执行一次 MapReduce Job才能得到。虽然HBase在数据存储层中集成了MapReduce,能够有效用于数据表的分布式计算。
然而在很多情况下,做一些简単的相加或者聚合计算的时候,如果直接将计算过程放置在server端,能够减少通讯开销,从而掀得很好的性能提升。于是, HBase在0.92之后引入了协处理器(coprocessors),实现一些激动人心的新特性:
能够轻易建立二次索引、复杂过滤器(谓词下推)以及访问控制等。
HBase协处理器的灵感来自子 Jeff Dean 09年的演讲( P66-67),它根据该演讲实现了类似于 bigtable 的协处理器,包括以下特性:
1 )每个表服务器的任意子表都可以运行代码
2)客户端的高层调用接口(客户端能够直接访问数据表的行地址, 多行读写会自动分片成多
3)提供一个非常灵活的、可用于建立分布式服务的数据模型
4)能够自动化扩展、负裁均衡、应用请求路由
HBase的协处理器灵感来白bigtable,但是实现细节不尽相同, HBase建立了一个框架,它为用户提供类库和运行时环境,使得他们的代码能够在HBase region server和masterr 上处理
协处理器分两种类型:
系统协处理器可以全局导入region server上的所有数据表
表协处理器使用户可以指定一张表使用协处理器
协处理器框架为了更好支持其行为的灵活性, 提供了两个不同方面的插件:
一个是观察者(observer) ,类似于关系数据库的触发器;
另一个是终端(endpoint),动态的终端有点像存储过程。
observer
观察者的设计意图是允许用户通过插入代码来重载协处理器框架的upcall方法, 而具体的事件触发的callback方法由HBase的核心代码来执行。协处理器框架处理所有的callback调用细节, 协处理器自身只需要插入添加或者改变的功能。
以HBase0.92版本为例, 它提供了三种观察者接口:
RegionObserver—提供客户端的数据操纵事件钩子: Get、 Put、 Delete、 Scan等。
WALObserver— 提供WAL相关操作钩子。
MasterObserver —提供DDL一类型的操作钩子。如创建、 删除、修改数据表等。
这些接口可以同时使用在同一个地方, 按照不同优先级顺序执行.用户可以任意基于协处理器实现复杂的HBase功能层。 HBase有很多种事件可以触发观察者方法,这些事件与方法从HBase0.92版本起,都会集成在HBaseAPl中。不过这些APl可能会由子各种原因有所改动, 不同版本的接口改动比较大。
observer模型
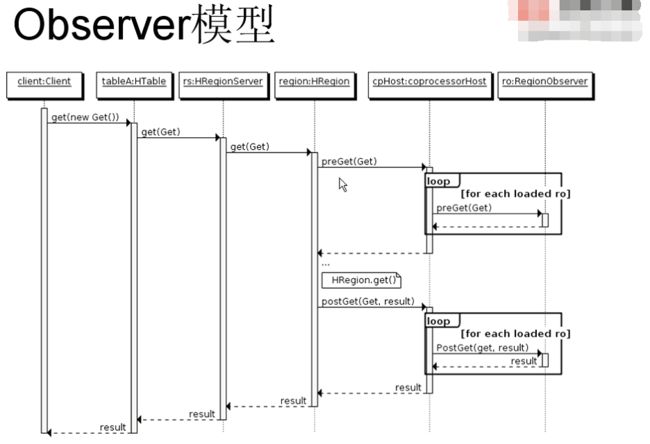
终端是动态RPC插件的接口,它的实现代码被安装在服务器端,从而能够通过HBase RPC唤醒。客户端类库提供了非常方便的方法来调用这些动态接口,它们可以在任意时候调用一个终端,它们的实现代码会被目标region远程执行,结果会返回到终端.用户可以结合使用这些强大的插件接口,为HBase添加全新的特性.
终端的使用,如下面流程所示:
- 定义一个新的protocol接口, 必须继承CoprocessorProtocol.
- 实现终端接口, 该实现会被导入region环境执行
- 继承抽象类BaseEndPiontCoprocessor
- 在客户端,终端可以被两个新的HBase Client API调用。
- 单个region:
HTableInterface.coprocessorProxy(Class protocol,byte[] row)。
- regions区域:
HTableInterface.coprocessorExec(Class protocol,byte[] startKey,byte[] endKey,Batch.Call
EndPiont
有三个方法对EndPiont进行设置:
A.启动全局aggreation,能过操纵所有的表上的数据。通过修改hbase-site.xml这个文件来实现,只需要添加如下代码:
hbase.coprocessor.user.region.classes
org.apache.hadoop,coprocessor.RowCountEndPiont
(注:完成之后需要重启hbase集群)
B.启用表aggregation,只对特定的表生效。通过Hbase Shell来实现:
1)disable指定表。
hbase > disable 'mytable'
2)添加aggregation
hbase > alter 'mytable',METHOD=>'table_att','coprocessor'=>'|org.apache.hadoop.hbase.coprocessor.RowCountEndPiont||'
3)重启指定表
hbase > enable 'mytable'
C.API调用
HTableDescriptor htd = new HTableDescriptor("testTable")
htd.setValue("COPROCESSOR$1",path.toString+"|"+RowCountEndPiont.class.getCanonicalName()+"|"+Coprocessor.Priority.USER);几点说明
1.协处理器配置的加载顺序:先加载配置文件中定义的协处理器、后加载表描述符中的协处理器
2.COPROCESSOR$中的number定义了加载的顺序
3.协处理器的加载格式 
这里的三个竖线‘1|2 |3 |4’划分了4个区域,各代表的含义:
1:协处理器所调用jar文件的路径
2:执行协处理器的类
3:协处理器的执行优先级顺序,如果不写的话,代表默认的值
4:传递给协处理器的参数
学以致用1–添加自定义的EndPiont协处理器:
找一个现成的Observer测试一下:
在$HBASE_HOME/hbase-server/src/main/java/org/apache/hadoop/hbase/coprocessor目录下,有很多协处理器的Java类
我们查看一下 
在这个目录下,放置的都是Observer和EndPiont等实现类
RegionObserver是一个接口,如果想要自定义一个Observer协处理器,那么就应该实现RegionObserver这个接口。
我们可以看到,这个接口中的函数有:preOpen、postOpen、perGet、postGet、preBulkLoadHFile、postBulkLoadHFile等方法 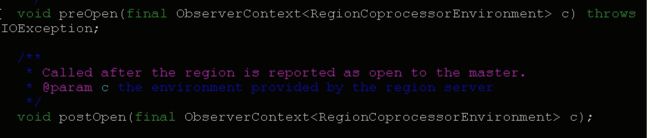
Observer类似于触发器,在某些特定操作的前后触发它定义的钩子函数,比如preGet(Get)、postGet(Get)等方法。
相比Observer,使用Endpiont更加灵活,因为它类似于存储过程,在需要调用的时候就可以通过代码调用
通过官方例子RowCountEndPiont.java认识EndPiont
这里简要介绍一下hbase源码中提供的例子RowCountEndPiont.java的使用方法: 
这个类实现的方法是对某个表进行 -‘行统计’
首先使用linux查找命令
RowCountEndPiont.java位于$HBASE_HOME/hbase-server/hbase-examples/src/main/java/org/apache/hadoop/hbase/coprocessor/example/目录下。
在Server端:
RowCountEndPiont类 继承了 ExampleProtos.RowCountService 实现了 Coprocessor和CoprocessorService两个接口
重写getService()方法和getRowCount()方法
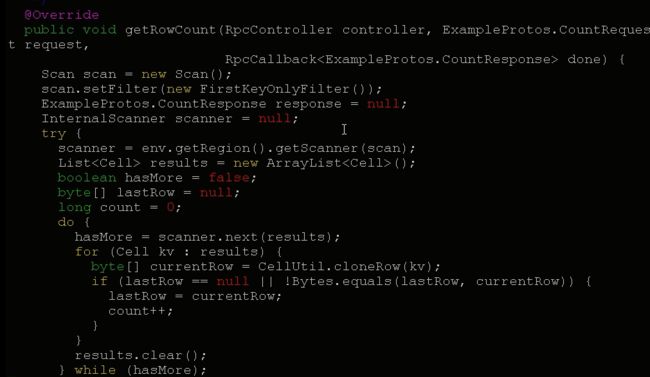
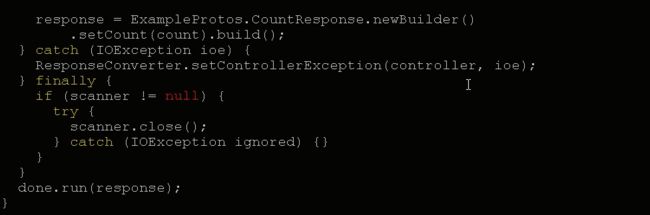
接下来,我们看看客户端是怎么实现的?
同样的,在example/目录下,我们找到TestRowCountEndPiont.java,是客户端测试代码。
public void testEndpoint() throws Throwable {
HTable table = new HTable(CONF, TEST_TABLE);
// insert some test rows
for (int i=0; i<5; i++) {
byte[] iBytes = Bytes.toBytes(i);
Put p = new Put(iBytes);
p.add(TEST_FAMILY, TEST_COLUMN, iBytes);
table.put(p);
}
final ExampleProtos.CountRequest request = ExampleProtos.CountRequest.getDefaultInstance();
Map<byte[],Long> results = table.coprocessorService(ExampleProtos.RowCountService.class,
null, null,
new Batch.Call() {
public Long call(ExampleProtos.RowCountService counter) throws IOException {
ServerRpcController controller = new ServerRpcController();
BlockingRpcCallback rpcCallback =
new BlockingRpcCallback();
counter.getRowCount(controller, request, rpcCallback);
ExampleProtos.CountResponse response = rpcCallback.get();
if (controller.failedOnException()) {
throw controller.getFailedOn();
}
return (response != null && response.hasCount()) ? response.getCount() : 0;
}
});
// should be one region with results
assertEquals(1, results.size());
Iterator iter = results.values().iterator();
Long val = iter.next();
assertNotNull(val);
assertEquals(5l, val.longValue());
}
测试:
我们对一张表students加载 EndPiont 协处理器:
注:一定要照着规矩来,3个步骤一个都不能少!不然hbase集群极易崩溃
1.首先disable表students
> disable ‘students’2.加载协处理器
>alter ’students’, ’coprocessor’=>’|org.apache.hadoop.hbase.coprocessor.example.RowCountEndpoint||’
3.enable表
> enable ‘students’通过浏览器查看一下协处理器有没有加载成功: 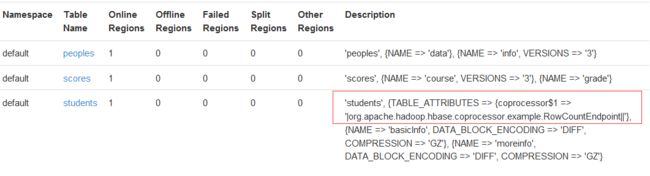
4.接下来编写java客户端测试代码:
这个代码是仿照官方给出的例子代码,后面统计做了些小的改动
package com.hbase.coprosessor;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.coprocessor.Batch;
import org.apache.hadoop.hbase.coprocessor.example.generated.ExampleProtos;
import org.apache.hadoop.hbase.ipc.BlockingRpcCallback;
import org.apache.hadoop.hbase.ipc.ServerRpcController;
import com.google.protobuf.ServiceException;
public class CoprocessorRowCount {
public static void main(String[] args) throws ServiceException, Throwable {
//获取连接
Configuration conf = HBaseConfiguration.create();
//设置连接到zookeeper集群
conf.set("hbase.zookeeper.quorum", "itcast05:2181, itcast06:2181, itcast07:2181");
//创建一个HTable对象,用于对'students'表进行操作
HTable table = new HTable(conf, "students");
final ExampleProtos.CountRequest request = ExampleProtos.CountRequest.getDefaultInstance();
Map<byte[],Long> results = table.coprocessorService(ExampleProtos.RowCountService.class,
null, null,
//回调函数
new Batch.Call() {
public Long call(ExampleProtos.RowCountService counter) throws IOException {
ServerRpcController controller = new ServerRpcController();
BlockingRpcCallback rpcCallback =
new BlockingRpcCallback();
//getRowCount真正是在server端进行实现的
counter.getRowCount(controller, request, rpcCallback);
ExampleProtos.CountResponse response = rpcCallback.get();
if (controller.failedOnException()) {
throw controller.getFailedOn();
}
return (response != null && response.hasCount()) ? response.getCount() : 0;
}
});
/**
* 统计表对应的所有Region的行数
*/
long sum = 0; //累加表的行数
int count = 0; //统计region的个数
for(Long l : results.values()){
sum += l;
count++;
}
//输出行统计数
System.out.println("row count = " + sum );
//输出region的统计数
System.out.println("region count = " + count);
}
}
先看看students表中的内容:
hbase(main):007:0> scan 'students'
ROW COLUMN+CELL
Jack column=basicInfo:age, timestamp=1469016354122, value=15
Jack column=moreinfo:tel, timestamp=1469016354378, value=555
Jim column=basicInfo:age, timestamp=1468998811470, value=28
Jim column=moreinfo:tel, timestamp=1468998811470, value=119
Jones column=basicInfo:age, timestamp=1469016354466, value=20
Jones column=moreinfo:tel, timestamp=1469016356173, value=666
Tom column=basicInfo:age, timestamp=1468998811470, value=27
Tom column=moreinfo:tel, timestamp=1468998811470, value=110
Tony column=basicInfo:age, timestamp=1469016428778, value=16
Tony column=moreinfo:tel, timestamp=1469016429653, value=999
5 row(s) in 4.2800 seconds测试代码的运行结果:
row count = 5
region count = 1很明显的看出,这样的统计结果是正确的
小结:
相对于MapReduce,使用hbase中的协处理器用来对表进行统计,效率是高很多的,因为统计工作是完全在server端执行的,client只是接收了最终的统计结果;
而MapReduce需要将数据读到客户端,然后在客户端进行汇总,会相当慢!!
学以致用2–添加自定义的Observer协处理器:
1.首先来写一个协处理器的处理代码 RegionObeserverTest .java:
package com.hbase.coprosessor;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.util.Bytes;
public class RegionObeserverTest extends BaseRegionObserver {
private static byte[] fixed_rowkey = Bytes.toBytes("Jack");
/**
* 如果rowkey检索到Jack,篡改jack信息后输出,其他非Jack的行原样输出
*/
@Override
public void preGet(ObserverContext c,
Get get, List result) throws IOException {
//比较rowkey是否和自己定义的“Jack”匹配
if(Bytes.equals(get.getRow(), fixed_rowkey)){
//构造一组返回数值: key-"Jack" family-"time" qualifier-"time" value-当前时间戳
KeyValue kv = new KeyValue(get.getRow(),Bytes.toBytes("time"),Bytes.toBytes("time")
,Bytes.toBytes(System.currentTimeMillis()));
result.add(kv);
}
}
}
2.加载这个协处理器之前,先移除之前上一个例子中的Coprocessor:
在hbase shell 中执行如下的命令:
在表描述信息中看到,’students’表的协处理器配置信息如下:
{TABLE_ATTRIBUTES => {coprocessor$1 => '|org.apache.hadoop.hbase.coproc
essor.example.RowCountEndpoint||'} 输入如下的命令移除这个协处理器
> alter 'students',METHOD =>'table_att_unset',NAME => 'coprocessor$1'这里输入协处理器的名称 coprocessor$1 ,只要匹配就能成功删除。
3.上传刚才导出的jar文件到hdfs上:
> hadoop fs -put myCoprocessor.jar /
4.加载新的协处理器
> disable 'students'
> alter 'students', 'coprocessor'=>'hdfs://ns1/myCoprocessor.jar|com.hbase.coprocessor.RegionObserverTest||'
> enable 'students'
5.查看是否加载成功 
6.使用客户端读取table ‘students’
由于自定义的Observer协处理器是在Get方法执行时触发的,所以在client端,我们需要通过get(RowKey)方法来获取表中的值
hbase(main):010:0> get 'students','Jack'
COLUMN CELL
time:time timestamp=9223372036854775807, value=\x00\x00\x01V!\xE9$
basicInfo:age timestamp=1469016354122, value=15
moreinfo:tel timestamp=1469016354378, value=555
3 row(s) in 0.8950 seconds
与"Jack"匹配的行,在输出前多了一条信息,这条信息就是是在自定义Observer时指定的
hbase(main):011:0> get 'students','Tom'
COLUMN CELL
basicInfo:age timestamp=1468998811470, value=27
moreinfo:tel timestamp=1468998811470, value=110
2 row(s) in 0.0830 seconds
与"Jack"不匹配的行,按照原样输出使用java实现get方法的代码如下:
public Result getData(String tableName,String rowKey){
try {
HTableInterface table = hConn.getTable(tableName);
Get get = new Get(Bytes.toBytes(rowKey));
return table.get(get);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public void format(Result result){
String rowkey = Bytes.toString(result.getRow());
KeyValue[] kvs = result.raw();
for(KeyValue kv:kvs){
String family = Bytes.toString(kv.getFamily());
String qualifier = Bytes.toString(kv.getQualifier());
String value = Bytes.toString(kv.getValue());
System.out.println("rowkey->"+rowkey+" Family->"+family
+" qualifier->"+qualifier+" value->"+value);
}
}
main 方法中
初始化连接
Result result = conn.getData("students", "Jack");
conn.format(result);
Result result1 = conn.getData("students", "Tom");
conn.format(result1);运行结果:
rowkey->Jack Family->time qualifier->time value->\x00\x00\x01V!\xE9$
rowkey->Jack Family->basicInfo qualifier->age value->15
rowkey->Jack Family->moreinfo qualifier->tel value->555
rowkey->Tom Family->basicInfo qualifier->age value->27
rowkey->Tom Family->moreinfo qualifier->tel value->110当检索 ‘Jack’的时候,信息被成功篡改,后续输出Jack的原数据(如果不想输出原数据,可以在定义Observer的时候, result.add(kv);一句后面加入c.bypass(); 来跳过这些信息的输出)
非 ‘Jack’行原样输出