《Deep Neural Networks for YouTube Recommendations》学习笔记
文章脉络清晰,主要包括六个部分:YouTube使用DNN的背景、整体推荐系统框架、候选集生成(candidate generation)、排序(ranking)、总结、感谢,其中候选集生成和排序是推荐系统框架的重要组成部分。
1.整体推荐系统框架
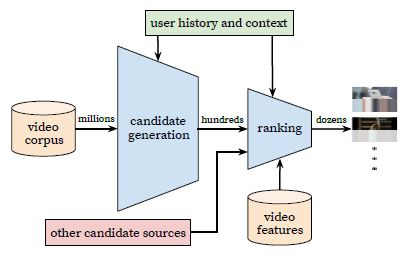
不得不说一下,好的paper总是那样,看下图片,大概意思就可以明白很多了
(1)首先关注图片中下几个单词millions、hundreds、dozens:表示数据量的级别,全部的video corpus大概是millions级别,经过candidate generation之后大概是hundreds级别,经过ranking之后大概是dozens级别
(2)candidate generation的输入包括millions video corpus、user history and context ,旨在快速高效地筛选部分视频集合
(3)ranking的输入包括hundreds video corpus、user history and context、other candidate sources、video features,旨在得到高精度的TOP N
2.候选集生成
(1)一个思考方式的转变
我们把推荐问题建模成一个“超大规模多分类”问题。即在时刻t,为用户U(上下文信息C)在视频库V中精准的预测出视频i的类别(每个具体的视频视为一个类别,i即为一个类别),用数学公式表达如下:

很显然上式为一个softmax多分类器的形式。向量![]() 是user, context>信息的高纬“embedding”,而向量
是user, context>信息的高纬“embedding”,而向量![]() 则是视频 j 的embedding向量。所以DNN的目标就是在用户信息和上下文信息为输入条件下学习用户的embedding向量u。
则是视频 j 的embedding向量。所以DNN的目标就是在用户信息和上下文信息为输入条件下学习用户的embedding向量u。
(2)Deep candidate generation model architecture

用户观看历史数据、搜索数据,做一个embedding,加上age、gender特征作为DNN的输入,接下来是几层的全连接层(激活函数是ReLU),训练阶段使用cross-entropy作为优化损失函数,线上阶段根据user vector和video vector通过an approximate nearest neighbor lookup得到TOP N作为输出,也是ranking阶段的输入
(3)标签和输入文本的选择

上图中,实心黑点表示输入,空心点表示标签。论文中表示,在进行A/B Test的时候,发现(b)这种选择标签和输入比(a)好
个人理解,这也是符号常识的,毕竟人的兴趣是随着时间推移而发生变化的。
3.排序
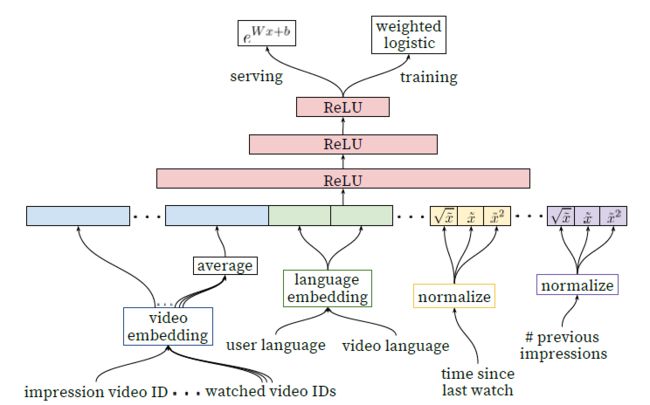
对类别特征(包括单值和多值的)进行Embedding,对连续特征进行Normalizing,训练阶段最后一层是加权的逻辑斯蒂回归,预测阶段直接根据学习到的W得到输出结果。
4.不定长变为定长Embedding
这块纯属个人理解,如果有错,还望指出
每一个人观看video的id list长度是不一样的,这种情形跟一条文本长度不一样需要做情感分析这种任务类似
由于这篇文章没有开源,有些细节还是需要自己摸索,下面是keras example中lstm_imdb的相关代码,仅供参考学习
from __future__ import print_function
import numpy as np
np.random.seed(1337) # for reproducibility
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Dropout, Embedding, LSTM, Bidirectional
from keras.datasets import imdb
max_features = 20000
maxlen = 100 # cut texts after this number of words (among top max_features most common words)
batch_size = 32
print('Loading data...')
(X_train, y_train), (X_test, y_test) = imdb.load_data(nb_words=max_features)
print(len(X_train), 'train sequences')
print(len(X_test), 'test sequences')
print("Pad sequences (samples x time)")
X_train = sequence.pad_sequences(X_train, maxlen=maxlen)
X_test = sequence.pad_sequences(X_test, maxlen=maxlen)
print('X_train shape:', X_train.shape)
print('X_test shape:', X_test.shape)
y_train = np.array(y_train)
y_test = np.array(y_test)
model = Sequential()
model.add(Embedding(max_features, 128, input_length=maxlen))
model.add(Bidirectional(LSTM(64)))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
# try using different optimizers and different optimizer configs
model.compile('adam', 'binary_crossentropy', metrics=['accuracy'])
print('Train...')
model.fit(X_train, y_train,
batch_size=batch_size,
nb_epoch=4,
validation_data=[X_test, y_test])
参考文献
(1)Deep Neural Networks for YouTube Recommendations
(2)keras github
推荐阅读
(1)用深度学习(DNN)构建推荐系统 - Deep Neural Networks for YouTube Recommendations论文精读