上上德盛面试题,java软件开发工程师
Java面试题全集(上中下)
https://blog.csdn.net/jackfrued/article/details/44921941
https://blog.csdn.net/jackfrued/article/details/44931137
https://blog.csdn.net/wangxiang1292/article/details/79027875
Java常见面试题整理【1】
https://blog.csdn.net/m0_37955444/article/details/78878030
中公培训网站面试题,前后翻一翻网站内容
http://www.offcn.com/it/2017/0330/7643.html
fail-fast简介
当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。
http://www.cnblogs.com/skywang12345/p/3308762.html
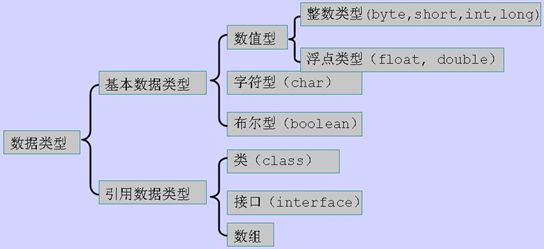
1.java支持的数据类型有哪些?什么是自动拆装箱?
基本数据类型,布尔型boolean,字符型char, 整数类型byte,int,short ,long,浮点类型float,double
引用类型:类,接口,数组
java为每种基本类型都提供了对应的封装类型,分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean。引用类型是一种对象类型,它的值是指向内存空间的引用,就是地址。
自动装箱: java自动将原始类型转化为引用类型的过程,自动装箱时编译器会调用valueOf方法
自动拆箱: java自动将引用类型转化为原始类型的过程,自动拆箱时编译器会调用intValue(),doubleValue()这类的方法
2.什么是值传递和引用传递
对象被值传递,意味着传递了对象的一个副本。因此,就算是改变了对象副本,也不会影响源对象的值。
对象被引用传递,意味着传递的并不是实际的对象,而是对象的引用。因此,外部对引用对象所做的改变会反映到所有的对象上。
对象的属性可以在被调用过程中被改变,但对对象引用的改变是不会影响到调用者的。
值传递:传递的是实际参数的一个副本,这个值可能是基本类型,也可能是引用类型的地址.
引用传递:传递的是实际参数的地址的一个副本.
在java中,只有值传递.
3.创建线程有几种不同的方式,你喜欢哪一种?为什么
参考 https://blog.csdn.net/dz_hexiang/article/details/78069736
https://www.cnblogs.com/songshu120/p/7966314.html
答案:3种方法,其中前两中是常用的方法,推荐第二种方法
1).继承Thread类,重写run()方法,实例化该类,调用线程start()方法
2)实现Runnable接口,并实现该接口的run()的方法
具体步骤:
(1)自定义类,并实现Runnable接口,重写实现run()方法
(2)创建Runnable实现类的实例,并用这个实例作为Thread的target来创建Thread对象
创建Thread子类实例:用实现Runnable接口的对象作为参数创建Thread对象
(3)然后调用线程start()方法
3).应用程序可以使用Executor框架来创建线程池
实现Runnable接口这种方式更受欢迎,因为这不需要继承Thread类。在应用设计中已经继承了别的对象的情况下,这需要多继承(而Java不支持多继承),只能实现接口。同时,线程池也是非常高效的,很容易实现和使用。
4.在监视器内部是如何做到线程同步的?程序应该做到哪种级别的同步
在java虚拟机中,每个对象(object和class)通过某种逻辑关联监视器,每个监视器和一个对象引用相关联,为了实现监视器的互斥功能,每个对象都关联着一把锁
一旦方法或者代码块被synchronized修饰,那么这个部分就放入了监视器的监视区域,确保一次只能有一个线程执行该部分的代码,线程在获取锁之前不允许执行该部分的代码
监视器和锁在Java虚拟机中是一块使用的。监视器监视一块同步代码块,确保一次只有一个线程执行同步代码块。每一个监视器都和一个对象引用相关联。线程在获取锁之前不允许执行同步代码。
5.如何确保N个线程可以访问N个资源同时又不导致死锁?
使用多线程的时候,一种非常简单的避免死锁的方式就是:指定获取锁的顺序,并强制线程按照指定的顺序获取锁。因此,如果所有的线程都是以同样的顺序加锁和释放锁,就不会出现死锁了。
多线程产生死锁的四个必要条件:
互斥条件:一个资源每次只能被一个进程使用。
保持和请求条件:一个进程因请求资源而阻塞时,对已获得资源保持不放。
不可剥夺调教:进程已获得资源,在未使用完成前,不能被剥夺。
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
只要破坏其中任意一个条件,就可以避免死锁,其中最简单的就是破环循环等待条件。按同一顺序访问对象,加载锁,释放锁
死锁:两个进程都在等待对方执行完毕才能继续往下执行的时候就发生了死锁。结果就是两个进程都陷入了无限的等待中。
两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象
一个简单的死锁例子,写个死锁的代码,彻底理解死锁,
https://www.cnblogs.com/baizhanshi/p/5437933.html
分析死锁的原因以及解决方法(https://www.cnblogs.com/jing99/p/5947841.html)
6.为什么集合类没有实现Cloneable和Serializable接口
答:克隆(cloning)或者序列化(serialization)的语义和含义是跟具体的实现相关的。因此应该由集合类的具体实现类来决定如何被克隆或者序列化
如何存储和维护这些对象是由具体实现来决定的。因为集合的具体形式多种多样,例如list允许重复,set则不允许。而克隆(clone)和序列化(serializable)只对于具体的实体,对象有意义
如果collection继承了clone和serializable,那么所有的集合实现都会实现这两个接口,而如果某个实现它不需要被克隆,甚至不允许它序列化(序列化有风险),那么就与collection矛盾了。
(1)什么是克隆?
克隆是把一个对象里面的属性值,复制给另一个对象。而不是对象引用的复制
(2)实现Serializable序列化的作用
1.将对象的状态保存在存储媒体中一边可以在以后重写创建出完全相同的副本
2.按值将对象从一个应用程序域法相另一个应用程序域
7.Iterator和listIterator的区别
1)、Iterator是ListIterator的父接口。
2)、Iterator是单列集合(Collection)公共取出容器中元素的方式。
对于List,Set都通用。
而ListIterator是List集合的特有取出元素方式。
3)、Iterator中具备的功能只有hashNext(),next(),remove();
ListIterator中具备着对被遍历的元素进行增删改查的方法,可以对元素进行逆向遍历。
之所以如此,是因为ListIterator遍历的元素所在的容器都有索引。
8.hashcode和equals方法的重要性体现在什么地方
Java中的HashMap使用hashCode()和equals()方法来确定键值对的索引,当根据键获取值的时候也会用到这两个方法。如果没有正确的实现这两个方法,两个不同的键可能会有相同的hash值,因此,可能会被集合认为是相等的。而且,这两个方法也用来发现重复元素。所以这两个方法的实现对HashMap的精确性和正确性是至关重要的。
9。数组array和列表arraylist有什么区别?什么时候应该使用Array而不是ArrayList?
Array可以包含基本类型和对象类型,ArrayList只能包含对象类型。
Array大小是固定的,ArrayList的大小是动态变化的。
ArrayList提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等。
对于基本类型数据,集合使用自动装箱来减少编码工作量。但是,当处理固定大小的基本数据类型的时候,这种方式相对比较慢,这时使用Array就会比较有效率。可以在教程网站秒秒学上看看,上面Java课程讲解得挺好的。
Array数组在存放的时候一定是同种类型的元素,ArrayList不是,因为他可以存放object
例子: int[] a= new int[5]
数量长度固定,类型一致的时候需要用array,因为他效率比较高
基于效率和类型检验,应尽可能使用Array,无法确定数组大小时才使用ArrayList!
HashMap的工作原理
https://blog.csdn.net/ty564457881/article/details/78206049
10.comparable和comparator接口是干什么的,列出他们的区别
Comparable & Comparator 都是用来实现集合中元素的比较、排序的,只是 Comparable 是在集合内部定义的方法实现的排序,Comparator 是在集合外部实现的排序,
所以,如想实现排序,就需要在集合外定义 Comparator 接口的方法或在集合内实现 Comparable 接口的方法。 Comparator位于包java.util下,而Comparable位于包 java.lang下
Java提供了只包含一个compareTo()方法的Comparable接口。这个方法可以个给两个对象排序。具体来说,它返回负数,0,正数来表明输入对象小于,等于,大于已经存在的对象。
11.hashset和treeSet的区别
1、TreeSet 是二叉树实现的,Treeset中的数据是自动排好序的,不允许放入null值。
2、HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。
12。java中exception和error有什么区别
Exception 和 Error 都是继承了 Throwable 类
Exception 是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。
Error 是指在正常情况下,不大可能出现的情况,绝大部分的 Error 都会导致程序(比如 JVM 自身)处于非正常的、不可恢复状态。既然是非正常情况,不需要捕获,常见的比如 OutOfMemoryError 之类,都是 Error 的子类。
13。finally和finalize方法有什么区别
被final修饰的类,就意味着不能再派生出新的子类,不能作为父类而被子类继承
finally是在异常处理时提供finally块来执行任何清除操作。不管有没有异常被抛出、捕获,finally块都会被执行。
- class.forname有什么作用
Class.forName(xxx.xx.xx)返回的是一个类。要求JVM查找并加载指定的类,也就是说JVM会执行该类的静态代码段。
Class.forName(“”)返回的是类。
Class.forName(“”).newInstance()返回的是object 。
15.数据库连接池是什么意思
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。
16。RMI体系结构分哪几层
存根和骨架层(Stub and Skeleton layer):这一层对程序员是透明的,主要负责拦截客户端发出的方法调用请求,然后把请求重定向给远程的RMI服务。
远程引用层(Remote Reference Layer):第二层用来解析客户端对服务端远程对象的引用。这一层解析并管理客户端对服务端远程对象的引用。连接是点到点的。
传输层(Transport layer):这一层负责连接参与服务的两个JVM。这一层是建立在网络上机器间的TCP/IP连接之上的。它提供了基本的连接服务,还有一些防火墙穿透策略。
17.说一下servlet的体系结构
servlet的工作原理:
servlet的体系结构:

Servlet 规范就是基于这几个类运转的,与 Servlet 主动关联的是三个类,分别是 ServletConfig、ServletRequest 和 ServletResponse。
这三个类都是通过容器传递给 Servlet 的,其中 ServletConfig 是在 Servlet 初始化时就传给 Servlet 了,而后两个是在请求达到时调用 Servlet 时传递过来的。
Servlet 的运行模式是一个典型的“握手型的交互式”运行模式。
servlet生命周期
【servlet学习一】:servlet体系结构和工作原理
https://blog.csdn.net/u012572815/article/details/78039041
18。什么是cookies?cookies和session的区别?
Cookie是由 Web服务器创建并保存在用户浏览器上的小文本文件,它以key/value的形式保存用户的相关信息,这些数据通常会经过加密处理。当用户链接到服务器 , Web站点可以访问Cookie信息。
服务器返回的cookie会存储在response 的Header里面
cookies和session的区别
不同的是,cookie是存储在本地浏览器,而session存储在服务器。
cookies:是针对每一个网站的信息,每一个网站只对应一个,其它网站不能访问,这个文件是保存在客户端的,每次你打相应网站,浏览器会查找这个网站的cookies,如果有就会将这个文件起发送出去。cookies文件的内容大致包函这些信息如用户名,密码,设置等,也可以是web服务器按照一定算法产生的只有Web服务器可以理解的数据,这些数据发送给客户端,客户端带着这些数据访问该网站才能被该网站识别。
session:是针对每一个用户的,只有客户机访问,程序就会为这个客户新增一个session。session里主要保存的是用户的登录信息,操作信息等。这个session在用户访问结束后会被自动消失(如果超时也会)。