《Unity Shader 与 计算机图形学》第一章
《Unity Shader 与 计算机图形学》第一章
问题:
入
图形学
大坑这么久,看了不少书,却发现一个严重的问题。大部分时间在知其然不知其所以然。没有一篇文章从GPU讲到游戏引擎再到游戏。
这种自底向上的架构性的东西对于图形学程序员来说可谓至关重要 我初学的时候就无时不刻在为GPU怎么参与图形运算
shader是干吗的? 管线是个什么鬼? 那些牛逼闪闪的demo效果为什么的那么好?
所以:
这个系列三篇文章将从GPU工作到绘图过程~从一个史诗级unity 官方demo的shader技术~最终清楚地描述
GPU/OPEN GL/D3D/Shader/管线/渲染器/实时渲染算法/等等一大堆名词之间的关系,最终,我们将分析unity和unreal的画质究竟为什么会有差异,并以一个工程来证明,unity的画质也可以很好。
提示:
本系列文章分为
硬件
编程入门
工程实践
因为硬件部分比较枯燥和陌生。所以如果对于硬件没有兴趣可以直接关注后续文章。本系列从2106年12月开始月更 在2017年2月之前更新完三篇
最底层——GPU/硬件原理
硬件的工作原理其实简单理解起来用一个视频就能说明
Mythbusters Demo GPU versus CPU
但是基于明确的说明 我们还是用Nvdia的文档来了解一下GPU的不同之处和工作机制

这是现代典型GPU和CPU的不同之处 我们看到真正的计算单元也就是绿色的部分
GPU采用来大量的计算核心也就是Nvdia口中的Cuda核心来进行高数据密度的运算
#铺垫:
先来了解计算机内部这些运算器控制器都是用来干嘛的~
1.ALU:Arithmetic Logic Unit 算数逻辑单元
大部分ALU都可以完成以下运算∶
整数算术运算(加、减,有时还包括乘和除,不过成本较高)
位逻辑运算(与、或、非、异或)
移位运算(将一个字向左或向右移位或浮动特定位,而无符号延伸),移位可被认为是乘以2或除以 2。
Alu可以说是计算机处理器的核心部件之一
2.Cache:
通常人们所说的Cache就是指缓存SRAM。 SRAM叫静态内存,“静态”指的是当我们将一笔数据写入SRAM后,除非重新写入新数据或关闭电源,否则写入的数据保持不变。
由于CPU的速度比内存和硬盘的速度要快得多,所以在存取数据时会使CPU等待,影响计算机的速度。SRAM的存取速度比其它内存和硬盘都要快,所以它被用作电脑的高速缓存(Cache)。
对于一个典型的CPU来说

Alu部分会很强大 可以在很少的时钟周期内完成算数计算
对于一个64bit双精度的CPU来说 浮点加法和乘法只需要1-3个时钟周期
而相比动辄2GHZ 10^9 的cpu来说对于逻辑和算数运算的处理能力就非常强了
大的cache也将延时降低很多 结合了现在的各种高级调节技术比如超线程 多核 等技术CPU对于复杂逻辑的运算能力得到了极大提升
对于典型的GPU来说

ALU的数量会非常大 功能会更少 能耗很低 cache就会很小
这样带来的好处就是针对大吞吐量的需要简单计算的数据来说 处理效率就高了非常多。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。
GPU的控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
GPU的虽然有dram延时,却有非常多的ALU和非常多线程. 为啦平衡内存延时的问题,我们可以中充分利用多的ALU的特性达到一个非常大的吞吐量的效果。尽可能多的分配多的线程.通常来看GPU ALU会有非常重的pipeline就是因为这样。
对比结构
我们可以先得出一个简单结论,那就是。针对今天的显卡来说。更适合做高并行,高数据密度,简单逻辑的运算。
然而
在硬件上更进一步的架构中在这里Nvdia和AMD这两大家的方案技术路线不同 因此我们需要对比一下
###在之前下面这段有几个概念说明:
1.4D向量和4+1
3D物件的成像過程中,VS(Vertex Shader,顶点着色引擎)&PS(Pixel Shader,像素著色引擎)最主要的作用就是运算坐标(XYZW)@(RGBA)。此时数据的基本单位是scalar(标量),1个单位的变量操作,为1D标量简称1D。
而跟标量相對的就是vector(向量),向量是由多個标量构成。例如每個周期可执行4個向量平行运算,就称为4D向量架构。若GPU指令发射口只有1个,卻可執行4個数据的平行运算,这就是SIMD架构。
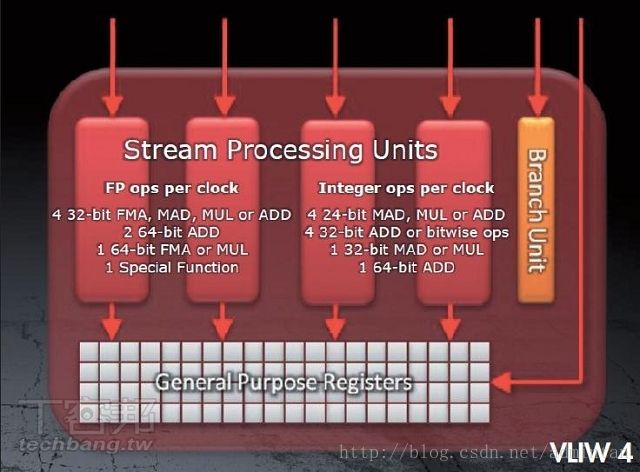
后来这个架构变成了4+1结构
2.运算单元计算机制
以GPU的矩阵加法为例:
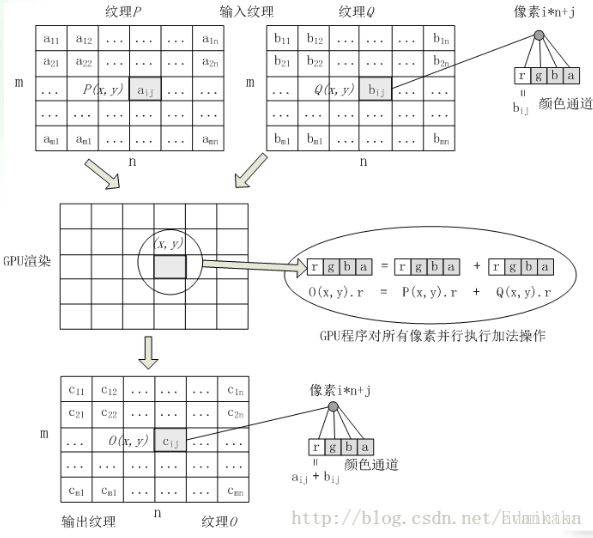
NVIDIA
标注的是Stream Processing(流处理器)数量,
NVIDIA的流处理器每个都具有完整的ALU(可以理解为数学、逻辑等运算)。NVIDIA从G80以后采用全标量设计,所有运算全都转为标量计算。但是这么做一旦遇到4D矢量运算时,就需要4次运算才能完成,所以NVIDIA显卡的Shader频率几乎比核心频率高一倍,就是为了弥补这个缺点。
NV的流处理器都具有完整的ALU功能,所以每个流处理器消耗的晶体管数量较多,成本较高。在加上现在的CUDA功能所以晶体管数量大幅多于AMD-ATI。
### AMD/ATI
标注的是Stream Processing Units(统一渲染单元)数量,也可以叫流处理器单元。
AMD-ATI从RV670以后,流处理器是5个固定的统一渲染单元为一组,4D矢量+1D标量组合。其中4个只能进行MADD(乘加)运算,1个可以进行超运算(函数等运算)。因为是5个固定为一组,不能拆分,所以遇到纯标量运算时就会有4个SPU处于闲置状态而无法加入其它SP组合协助运算。但换句话说如果分配得当让每个SPU都充分工作,那么AMD显卡的效率可是非常高的。这也是玩家公认A卡驱动提升性能比N卡要高,但也就是这个原因导致A卡驱动设计难度非常高,游戏想要为A卡优化的难度也一样很高。
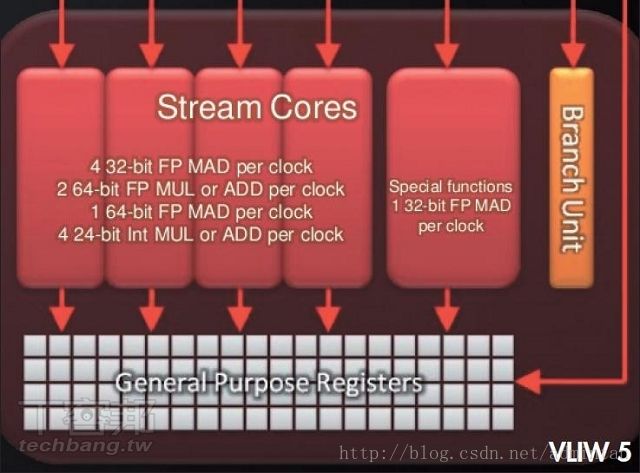
由于咱们主要讲软件 ALU CU这种数字逻辑部分的知识就不深入了 知道了硬件的区别
下面来看看他们的计算原理
先来普及一个比较无关概念——波阵面(Wavefront)
波在传递过程中有振动相位 就像三角函数sin有波峰有波谷
当我们取波峰为标准相位 那么在一个波阵面上 就出现了sin的波峰构成的点
当我们在三维中考量这个问题 则出现类似于下面这种画面

因此在一个波阵面中 其可能相互有关联关系 也就是根绝这个一区域可以推出下一区域
但也可能没有关联关系我们可以想象将两块石头扔进水中 向远散去的波 并不受另一个石头的影响
所以我们假定一个运算序列

假设有A~O共15个Wavefront,顺序是由A到O,且部分Wavefront存在相依性。其中C必须依赖B,也就是Wavefront C要等到Wavefront B运算完毕之後,才能算Wavefront C。类似B+2=4,B+C=6,必須先求得B m 的解才能解第二個方程式。其余E和F、F和G、L和K都是相同情況。
直接跳过落后架构VLIW4 其在多个周期出现了使用率低下的问题造成浪费
现在的4+1 VLIW5架构指令过程如下
周期1 BC相互依存 则:
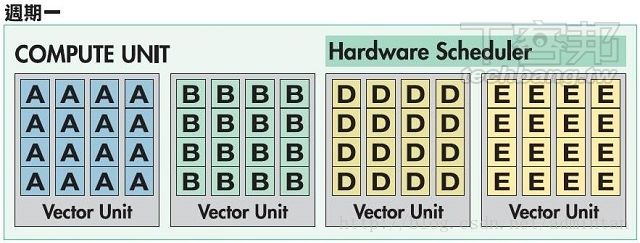
周期二:GF相互依存 则:

周齐三: LK互相依存 则:
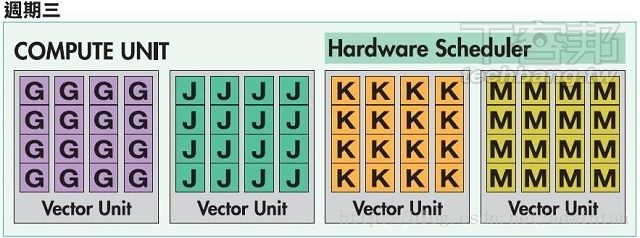
最后一个周期运算完毕
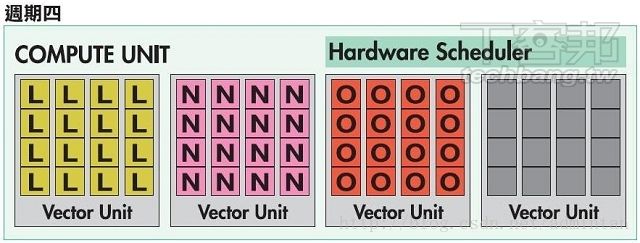
在4+1架构中某些场景的利用率被大大提高
讲完了硬件的架构和处理原理 下面我们该对硬件层级的处理流程进行一个了解
当然 如果从管线角度去讲的话就没有任何意义了 因为基本上对于一个整个系统都未知来说还是不是很好去理解的 所以先来看看图形在硬件中的转换流程
更高层-硬件流程
第一步 数据存储转换
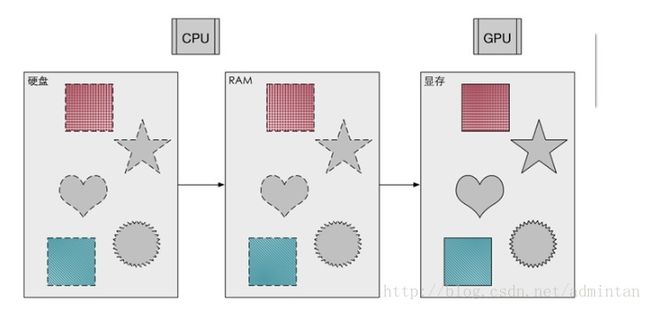
资源信息和指令信息由硬盘经过CPU调度 传输到内存中转,再传输进显存中备用

由图中的典型的带宽可见 GPU和显存之间的内部带宽 要比单纯的系统总线贷款要高很多
所以典型情况下渲染资源和渲染指令都被加载进显存 所以GPU在渲染过程中 只需向显存调度渲染指令避免了和系统总线频繁IO
第二步 进入渲染预备状态

此时GPU的显存越大则普遍来说依靠CPU的加载额外渲染指令的需要就越少 显存中的信息一般包括:
显存和内存一样用于存储GPU处理过后的数据,在显存中有几种不同的储存区域,用于储存不同阶段需要的数据。
1、顶点缓冲区:用于储存从内存中传递过来的顶点数据。
2、索引缓冲区:用于储存每个顶点的索引值,我们可以根据索引来使用相应的顶点
3、纹理缓冲区:用于储存从内存中传递过来的纹理数据
4、深度缓冲区:用于存储每个像素的深度信息
5、模板缓冲区:用于存储像素的模板值,且模板缓冲区域深度缓冲区公用一片内存。
6、颜色缓冲区:用于储存像素的颜色数据
待这部分后我们就可以了解下面的东西了 后续步骤将在之后介绍
软件,第一步
不管是三维模型 还是二维UI他们都是有个极其相似的数据结构的以3DS格式为例 :
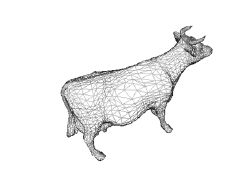
都是以三角面为基础
如果经过软件解析的话出现的数据结构就是点和索引信息
具体的理解这个从点线面的构建过程:
一个点的列表

根据索引信息链接点

根据索引信息构成面和块:
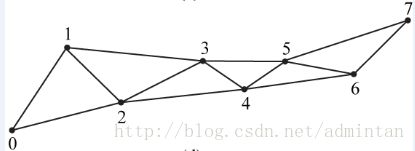
所有片面组成了模型的所有信息
举个例子帮助理解:
对于下图,9个顶点及拓扑类型Triangle List,对应索引:[0,1,2, 0,2,3, 0,3,4, 0,4,5, 0,5,6, 0,6,7, 0,7,8]。
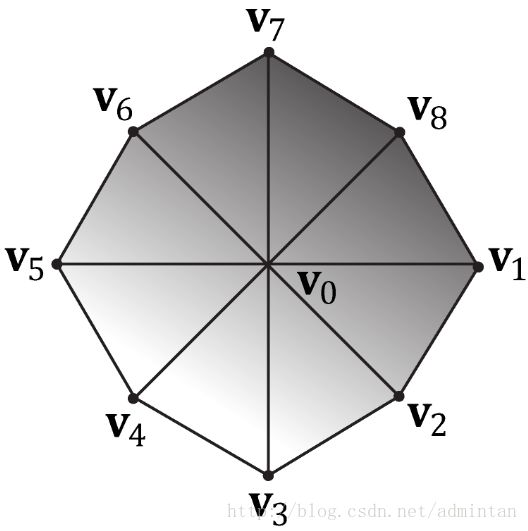
所以 整个三维场景的数据基础 都是以这种数据结构为框架 之前的内容中说过了 点信息索引信息都被加载进了 显存 中备用
而
模型不光有框架而已 包括颜色,贴图 等信息 也被加载如显存
软件,第二步 ——顶点着色器,坐标转换(几何阶段)
变换阶段:
此阶段是完全可编程的;
这个阶段的输入就是单个的顶点(顶点也是并行处理的)先来了解下变换阶段的概念
1. 模型空间:Model Space,也叫Local Space
直观的讲,这个坐标系一般以模型中心为原点,所有的模型在建模的时候给定的模型顶点坐标都以这个坐标系为基准,用户最开始所指定的顶点坐标也是位于该空间。
给出模型空间的好处在于方便建模,以及单个模型的重重利用。因为一个物体可被放置到场景的多个地方,这时每个物体的顶点坐标显然是不一样的,但可以共享同一个模型。
2. 世界空间:World Space
这个坐标系即3D场景给各个物体指定坐标的基准。、世界坐标系为整个游戏场景中的参考坐标系,是一个固定不变的坐标系,所有的模型的坐标都可以在世界坐标系中表示,模型在世界坐标系中可以执行位移变换,旋转变换,缩放变换等操作,但此时参考的坐标系是以世界坐标系为参考坐标系。在世界坐标系中还需要执行的是光照的计算、物体材质计算等工作。
3. 视角空间:View Space
这个坐标是以照相机为基准的,以照相机位置为原点,照相机朝向z轴正方向,右边为x轴正方向,上边为y轴正方向。之所以设置这个坐标系,主要是为了主便接下来的投影及裁剪操作。如果直接在世界空间下进行,由于照相机位置、朝向灵活多变,计算将会十分复杂。有了视角空间,一切计算以原点为基准,会大大方便计算。
4. 投影、裁剪空间:Projection Clip Space
这个空间即世界空间的物体被投影到相应的投影面上之后,继而进行裁剪操作所在的空间。
用户指定的所有顶点都是基于模型空间的,在Vertex Shader阶段,每个顶点要依次经历所有这些空间,最终转换为屏幕上对应的二维坐标,不同空间之间的切换称为“空间变换”,实现空间变换的基本工作即矩阵。一下表明了裁剪过程,eye space坐标转换到project and clip space坐标的过程其实就是一个投影、剪裁、映射的过程。因为在不规则的视锥体内剪裁是一件非常困难的事,所以前人们将剪裁安排到一个单位立方体中进行,这个立方体被称为规范立方体(CCV),CVV的近平面(对应视锥体的近平面)的x、y坐标对应屏幕像素坐标(左下角0、0),z代表画面像素深度。所以这个转换过程事实上由三步组成:
(1),用透视变换矩阵把顶点从视锥体变换到CVV中;
(2),在CVV内进行剪裁;
(3),屏幕映射:将经过前两步得到的坐标映射到屏幕坐标系上。

定点位置和法向量通常以模型坐标系或者世界空间坐标系表示。进行透视,顶点光照和纹理计算,动画角色计算蒙皮顶点着色器可以通过修改顶点位置来产生程序动画。
截至现在为止 我们得到了视角内的所有顶点数据
经过上面介绍过的
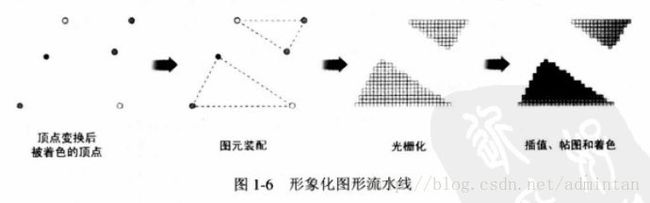
再经过第一步介绍的点和索引结构 还原出点线面 想象一下 现在的场景内 只有模型的线框
拿到了供渲染顶点数据之后流程大概如下所示

在unity中 过程可以更精确的表述为:
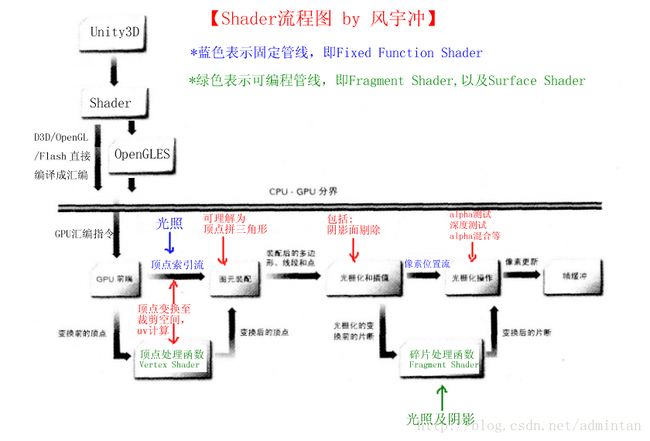
**在移动设备上Unity才会有将Shader解析成OpenGLES这一步 **
我们可以看到V_shader和F_shader有着不同的工作范围。shader被编译为GPU汇编指令进行定点/光照/阴影等运算。而OPENGL和D3D都有嵌入shader的函数
在
DX的版本中
3DXCompileShaderFromResource();
openGL中
static char *shaderLoadSource(const char *filePath)
{
const size_t blockSize=512;
FILE *fp;
char buf[blockSize];
char *source=NULL;
size_t tmp,sourceLength=0;
fp=fopen(filePath,"r");
if(!fp){
fprintf(stderr,"shaderLoadSource():Unable to open %s for reading\n",filePath);
return NULL;
}
while((tmp=fread(buf,1,blockSize,fp))>0)
{
char *newSource=(char *)malloc(sourceLength+tmp+1);
if(!newSource){
fprintf(stderr,"shaderLoadSource():malloc failed\n");
if(source){
free(source);
}
return NULL;
}
if(source){
memcpy(newSource,source,sourceLength);
free(source);
}
memcpy(newSource+sourceLength,buf,tmp);
source=newSource;
sourceLength+=tmp;
}
fclose(fp);
if(source){
source[sourceLength]='\0';
}
return source;
}
static GLuint shaderCompileFromFile(GLenum type,const char *filePath)
{
char *source;
GLuint shader;
GLint length,result;
source=shaderLoadSource(filePath);
if(!source){
return 0;
}
shader=glCreateShader(type);
length=strlen(source);
glShaderSource(shader,1,(const char**)&source,&length);
glCompileShader(shader);
free(source);
glGetShaderiv(shader,GL_COMPILE_STATUS,&result);
if(result==GL_FALSE){
char *log;
glGetShaderiv(shader,GL_INFO_LOG_LENGTH,&length);
log=(char *)malloc(length);
glGetShaderInfoLog(shader,length,&result,log);
fprintf(stderr,"shaderCompileFromFile(): Unable to compile %s: %s\n",filePath,log);
free(log);
glDeleteShader(shader);
return 0;
}
return shader;
}
void shaderAttachFromFile(GLuint program,GLenum type,const char *filePath)
{
GLuint shader=shaderCompileFromFile(type,filePath);
if(shader!=0){
glAttachShader(program,shader);
glDeleteShader(shader);
}
}
所以我们终于可以看清楚shader是怎样工作 下一篇开始 我们将具体介绍Shader从入门到完成一些效果的过程
总结
##如果我们以一个已知概念模型来总结这个工作过程
一个工厂中
shader property中的 材质 纹理 颜色 光照 等等就像是工厂中的原材料
###硬件本身就是工人