Deep TextSpotter: An End-to-End Trainable Scene Text Localization and Recognition Framework
Deep TextSpotter: An End-to-End Trainable Scene Text Localization and Recognition Framework
结果:state-of-the-art accuracy in the end-to-end text recognition on two standard datasets – ICDAR 2013 and ICDAR 2015,并且速度快了10倍,达到10 fps.
目前存在的问题:之前普遍是把检测模型和单独的识别模型连接在一起。
本模型:检测和识别在单一学习框架训练。本文展示了可以通过先进的目标检测算法经过拓展之后用于文本检测和识别。
很多文本检测方法是基于一般的目标检测方法然后拓展而来的。
we use YOLOv2 architecture [22] for its lower complexity, we use the bilinear sampling to produce tensors of variable width to deal with character sequence recognition and we employ a different (and significantly faster) classification stage.
使用YOLOv2的原因:YOLOv2更精确,并且比标准的VGG-16 architecture的复杂度低很多。场景图像中的文本可能很小,所以分辨率要高才行,否则很多小的不可读。
本文移除了YOLOv2的全连接层。模型最终的大小是W/32× H/32×1024。
与Faster R-CNN [23] 和 YOLOv2 [22]一样使用了 Region Proposal Network (RPN)来生成区域建议,但是添加了rθ,在最后一个卷积层的每个位置都预测k个旋转的边界框。对于每个边界框r,我们预测6个特征 - 其位置rx,ry,其尺寸rw,rh,其旋转rθ及其得分rp。
训练阶段输入图像尺寸:352, 416, 480, 544, 608,每20batches改变一次。A positive sample is the region with the highest intersection over union with the ground truth, the other intersecting regions are negatives.
这里使用bilinear sampling替代faster rcnn中的Roi pooling,将原图中w × h × C的region映射到固定高度的张量,wH/h×H × C tensor (H = 32)
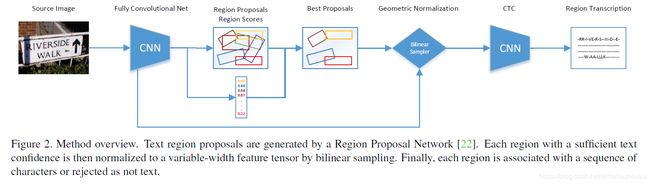
识别阶段:检测到的区域经过映射之后变为高度固定为32的region,
识别阶段输入W × 32 region, CTC output W/4× |Aˆ| as the most probable class at given column ,其中Aˆ是所有英文字符,包括特殊符号。一个region中的所有字符都使用同一个分类器来分每个字符。
在三个标准数据集上评估精度,
ICDAR2013时,每个图像被resize到544x544,ICDAR2015resize到608x608,110ms/幅,模型对于Blurred and noisy text (top), vertical text (top) and small text (bottom)文本的识别效果不好。对小文本检测识别效果不好,可能是因为训练集上没有。
训练:detection CNN using the SynthText dataset,recognition CNN is pre-trained on the Synthetic Word dataset,最后train both networks simultaneously for 3 epochs on a combined dataset consisting of the SynthText dataset, the Synthetic Word dataset, the ICDAR 2013 Training dataset [13] (229 scene images captured by a professional camera) and the ICDAR 2015 Training。
本文的实验结果表面the state-of-the-art object detection methods [22, 23] can be extended for text detection and recognition。结果还表明,联合训练更好。
未来的工作包括扩展训练集,使其具有更逼真的效果,单个字符和数字。