目录
- 概览
- 插入数据
- 更新数据
- 删除数据
- 查询数据
概览
MySQL数据操作: DML
在MySQL管理软件中,可以通过SQL语句中的DML语言来实现数据的操作,包括
- 使用INSERT实现数据的插入
- UPDATE实现数据的更新
- 使用DELETE实现数据的删除
- 使用SELECT查询数据以及。
插入数据insert
1. 插入完整数据(顺序插入)
语法一:
INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES(值1,值2,值3…值n);
语法二:
INSERT INTO 表名 VALUES (值1,值2,值3…值n);
2. 指定字段插入数据
语法:
INSERT INTO 表名(字段1,字段2,字段3…) VALUES (值1,值2,值3…);
3. 插入多条记录
语法:
INSERT INTO 表名 VALUES
(值1,值2,值3…值n),
(值1,值2,值3…值n),
(值1,值2,值3…值n);
4. 插入查询结果
语法:
INSERT INTO 表名(字段1,字段2,字段3…字段n)
SELECT (字段1,字段2,字段3…字段n) FROM 表2
WHERE …;
更新数据update
语法:
UPDATE 表名 SET
字段1=值1,
字段2=值2,
WHERE CONDITION;
示例:
UPDATE mysql.user SET password=password(‘123’)
where user=’root’ and host=’localhost’;
删除数据delete
语法:
DELETE FROM 表名
WHERE CONITION;
示例:
DELETE FROM mysql.user
WHERE password=’’;
练习:
更新MySQL root用户密码为mysql123
删除除从本地登录的root用户以外的所有用户
查询数据search
单表查询
单表查询的语句及关键字执行的优先级
- 单表查询语法
SELECT DISTINCT 字段1,字段2... FROM 表名
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数
- 关键字执行的优先级
from
where
group by
select
distinct
having
order by
limit
1.找到表:from
2.拿着where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
4.执行select(去重)
5.将分组的结果进行having过滤
6.将结果按条件排序:order by
7.限制结果的显示条数
简单查询
company.employee
员工id id int
姓名 emp_name varchar
性别 sex enum
年龄 age int
入职日期 hire_date date
岗位 post varchar
职位描述 post_comment varchar
薪水 salary double
办公室 office int
部门编号 depart_id int
#创建表
create table employee(
id int not null unique auto_increment,
emp_name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
#查看表结构
mysql> desc employee;
+--------------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| emp_name | varchar(20) | NO | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(3) unsigned | NO | | 28 | |
| hire_date | date | NO | | NULL | |
| post | varchar(50) | YES | | NULL | |
| post_comment | varchar(100) | YES | | NULL | |
| salary | double(15,2) | YES | | NULL | |
| office | int(11) | YES | | NULL | |
| depart_id | int(11) | YES | | NULL | |
+--------------+-----------------------+------+-----+---------+----------------+
#插入记录
#三个部门:教学,销售,运营
insert into employee(emp_name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部
('alex','male',78,'20150302','teacher',1000000.31,401,1),
('wupeiqi','male',81,'20130305','teacher',8300,401,1),
('yuanhao','male',73,'20140701','teacher',3500,401,1),
('liwenzhou','male',28,'20121101','teacher',2100,401,1),
('jingliyang','female',18,'20110211','teacher',9000,401,1),
('jinxin','male',18,'19000301','teacher',30000,401,1),
('成龙','male',48,'20101111','teacher',10000,401,1),
('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),
('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;
#ps:如果在windows系统中,插入中文字符,select的结果为空白,可以将所有字符编码统一设置成gbk
准备表和记录
#简单查询
SELECT id,emp_name,sex,age,hire_date,post,post_comment,salary,office,depart_id
FROM employee;
SELECT * FROM employee;
SELECT emp_name,salary FROM employee;
#避免重复DISTINCT
SELECT DISTINCT post FROM employee;
#通过四则运算查询
SELECT emp_name, salary*12 FROM employee;
SELECT emp_name, salary*12 AS Annual_salary FROM employee;
SELECT emp_name, salary*12 Annual_salary FROM employee;
#定义显示格式
CONCAT() 函数用于连接字符串
SELECT CONCAT('姓名: ',emp_name,' 年薪: ', salary*12) AS Annual_salary
FROM employee;
CONCAT_WS() 第一个参数为分隔符
SELECT CONCAT_WS(':',emp_name,salary*12) AS Annual_salary
FROM employee;
结合CASE语句:
SELECT
(
CASE
WHEN emp_name = 'jingliyang' THEN
emp_name
WHEN emp_name = 'alex' THEN
CONCAT(emp_name,'_BIGSB')
ELSE
concat(emp_name, 'SB')
END
) as new_name
FROM
employee;
小练习:
1 查出所有员工的名字,薪资,格式为 <名字:egon> <薪资:3000> 2 查出所有的岗位(去掉重复) 3 查出所有员工名字,以及他们的年薪,年薪的字段名为annual_year
select concat('<名字:',emp_name,'> ','<薪资:',salary,'>') from employee;
select distinct depart_id from employee;
select emp_name,salary*12 annual_salary from employee;
where约束
where字句中可以使用:
1. 比较运算符:> < >= <= <> !=
2. between 80 and 100 值在80到100之间
3. in(80,90,100) 值是80或90或100
4. like 'e%'
通配符可以是%或_,
%表示任意多字符
_表示一个字符
5. 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
#1:单条件查询
SELECT emp_name FROM employee
WHERE post='sale';
#2:多条件查询
SELECT emp_name,salary FROM employee
WHERE post='teacher' AND salary>10000;
#3:关键字BETWEEN AND
SELECT emp_name,salary FROM employee
WHERE salary BETWEEN 10000 AND 20000;
SELECT emp_name,salary FROM employee
WHERE salary NOT BETWEEN 10000 AND 20000;
#4:关键字IS NULL(判断某个字段是否为NULL不能用等号,需要用IS)
SELECT emp_name,post_comment FROM employee
WHERE post_comment IS NULL;
SELECT emp_name,post_comment FROM employee
WHERE post_comment IS NOT NULL;
SELECT emp_name,post_comment FROM employee
WHERE post_comment=''; 注意''是空字符串,不是null
ps:
执行
update employee set post_comment='' where id=2;
再用上条查看,就会有结果了
#5:关键字IN集合查询
SELECT emp_name,salary FROM employee
WHERE salary=3000 OR salary=3500 OR salary=4000 OR salary=9000 ;
SELECT emp_name,salary FROM employee
WHERE salary IN (3000,3500,4000,9000) ;
SELECT emp_name,salary FROM employee
WHERE salary NOT IN (3000,3500,4000,9000) ;
#6:关键字LIKE模糊查询
通配符’%’
SELECT * FROM employee
WHERE emp_name LIKE 'eg%';
通配符’_’
SELECT * FROM employee
WHERE emp_name LIKE 'al__';
小练习:
1. 查看岗位是teacher的员工姓名、年龄
2. 查看岗位是teacher且年龄大于30岁的员工姓名、年龄
3. 查看岗位是teacher且薪资在9000-1000范围内的员工姓名、年龄、薪资
4. 查看岗位描述不为NULL的员工信息
5. 查看岗位是teacher且薪资是10000或9000或30000的员工姓名、年龄、薪资
6. 查看岗位是teacher且薪资不是10000或9000或30000的员工姓名、年龄、薪资
7. 查看岗位是teacher且名字是jin开头的员工姓名、年薪
select emp_name,age from employee where post = 'teacher';
select emp_name,age from employee where post='teacher' and age > 30;
select emp_name,age,salary from employee where post='teacher' and salary between 9000 and 10000;
select * from employee where post_comment is not null;
select emp_name,age,salary from employee where post='teacher' and salary in (10000,9000,30000);
select emp_name,age,salary from employee where post='teacher' and salary not in (10000,9000,30000);
select emp_name,salary*12 from employee where post='teacher' and emp_name like 'jin%';
group by
单独使用GROUP BY关键字分组
SELECT post FROM employee GROUP BY post;
注意:我们按照post字段分组,那么select查询的字段只能是post,想要获取组内的其他相关信息,需要借助函数
GROUP BY关键字和GROUP_CONCAT()函数一起使用
SELECT post,GROUP_CONCAT(emp_name) FROM employee GROUP BY post;#按照岗位分组,并查看组内成员名
SELECT post,GROUP_CONCAT(emp_name) as emp_members FROM employee GROUP BY post;
GROUP BY与聚合函数一起使用
select post,count(id) as count from employee group by post;#按照岗位分组,并查看每个组有多少人
强调:
如果我们用unique的字段作为分组的依据,则每一条记录自成一组,这种分组没有意义
多条记录之间的某个字段值相同,该字段通常用来作为分组的依据
聚合函数
#强调:聚合函数聚合的是组的内容,若是没有分组,则默认一组
示例:
SELECT COUNT(*) FROM employee;
SELECT COUNT(*) FROM employee WHERE depart_id=1;
SELECT MAX(salary) FROM employee;
SELECT MIN(salary) FROM employee;
SELECT AVG(salary) FROM employee;
SELECT SUM(salary) FROM employee;
SELECT SUM(salary) FROM employee WHERE depart_id=3;
小练习:
1. 查询岗位名以及岗位包含的所有员工名字
2. 查询岗位名以及各岗位内包含的员工个数
3. 查询公司内男员工和女员工的个数
4. 查询岗位名以及各岗位的平均薪资
5. 查询岗位名以及各岗位的最高薪资
6. 查询岗位名以及各岗位的最低薪资
7. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
#题1:分组
mysql> select post,group_concat(emp_name) from employee group by post;
+-----------------------------------------+---------------------------------------------------------+
| post | group_concat(emp_name) |
+-----------------------------------------+---------------------------------------------------------+
| operation | 张野,程咬金,程咬银,程咬铜,程咬铁 |
| sale | 歪歪,丫丫,丁丁,星星,格格 |
| teacher | alex,wupeiqi,yuanhao,liwenzhou,jingliyang,jinxin,成龙 |
| 老男孩驻沙河办事处外交大使 | egon |
+-----------------------------------------+---------------------------------------------------------+
#题目2:
mysql> select post,count(id) from employee group by post;
+-----------------------------------------+-----------+
| post | count(id) |
+-----------------------------------------+-----------+
| operation | 5 |
| sale | 5 |
| teacher | 7 |
| 老男孩驻沙河办事处外交大使 | 1 |
+-----------------------------------------+-----------+
#题目3:
mysql> select sex,count(id) from employee group by sex;
+--------+-----------+
| sex | count(id) |
+--------+-----------+
| male | 10 |
| female | 8 |
+--------+-----------+
#题目4:
mysql> select post,avg(salary) from employee group by post;
+-----------------------------------------+---------------+
| post | avg(salary) |
+-----------------------------------------+---------------+
| operation | 16800.026000 |
| sale | 2600.294000 |
| teacher | 151842.901429 |
| 老男孩驻沙河办事处外交大使 | 7300.330000 |
+-----------------------------------------+---------------+
#题目5
mysql> select post,max(salary) from employee group by post;
+-----------------------------------------+-------------+
| post | max(salary) |
+-----------------------------------------+-------------+
| operation | 20000.00 |
| sale | 4000.33 |
| teacher | 1000000.31 |
| 老男孩驻沙河办事处外交大使 | 7300.33 |
+-----------------------------------------+-------------+
#题目6
mysql> select post,min(salary) from employee group by post;
+-----------------------------------------+-------------+
| post | min(salary) |
+-----------------------------------------+-------------+
| operation | 10000.13 |
| sale | 1000.37 |
| teacher | 2100.00 |
| 老男孩驻沙河办事处外交大使 | 7300.33 |
+-----------------------------------------+-------------+
#题目七
mysql> select sex,avg(salary) from employee group by sex;
+--------+---------------+
| sex | avg(salary) |
+--------+---------------+
| male | 110920.077000 |
| female | 7250.183750 |
+--------+---------------+
HAVING过滤
HAVING与WHERE不一样的地方在于!!!!!!
#!!!执行优先级从高到低:where > group by > having
#1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。
#2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
mysql> select @@sql_mode;
+--------------------+
| @@sql_mode |
+--------------------+
| ONLY_FULL_GROUP_BY |
+--------------------+
row in set (0.00 sec)
mysql> select * from emp where salary > 100000;
+----+------+------+-----+------------+---------+--------------+------------+--------+-----------+
| id | emp_name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+------+------+-----+------------+---------+--------------+------------+--------+-----------+
| 2 | alex | male | 78 | 2015-03-02 | teacher | NULL | 1000000.31 | 401 | 1 |
+----+------+------+-----+------------+---------+--------------+------------+--------+-----------+
row in set (0.00 sec)
mysql> select post,group_concat(emp_name) from emp group by post having salary > 10000;#错误,分组后无法直接取到salary字段
ERROR 1054 (42S22): Unknown column 'salary' in 'having clause'
mysql> select post,group_concat(emp_name) from emp group by post having avg(salary) > 10000;
+-----------+-------------------------------------------------------+
| post | group_concat(emp_name) |
+-----------+-------------------------------------------------------+
| operation | 程咬铁,程咬铜,程咬银,程咬金,张野 |
| teacher | 成龙,jinxin,jingliyang,liwenzhou,yuanhao,wupeiqi,alex |
+-----------+-------------------------------------------------------+
rows in set (0.00 sec)
小练习:
1. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数
3. 查询各岗位平均薪资大于10000的岗位名、平均工资
4. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资
#题1: mysql> select post,group_concat(emp_name),count(id) from employee group by post having count(id) < 2; +-----------------------------------------+--------------------+-----------+ | post | group_concat(emp_name) | count(id) | +-----------------------------------------+--------------------+-----------+ | 老男孩驻沙河办事处外交大使 | egon | 1 | +-----------------------------------------+--------------------+-----------+ #题目2: mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000; +-----------+---------------+ | post | avg(salary) | +-----------+---------------+ | operation | 16800.026000 | | teacher | 151842.901429 | +-----------+---------------+ #题目3: mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 and avg(salary) <20000; +-----------+--------------+ | post | avg(salary) | +-----------+--------------+ | operation | 16800.026000 | +-----------+--------------+
ORDER BY 查询排序
按单列排序
SELECT * FROM employee ORDER BY salary;
SELECT * FROM employee ORDER BY salary ASC;
SELECT * FROM employee ORDER BY salary DESC;
按多列排序:先按照age排序,如果年纪相同,则按照薪资排序
SELECT * from employee
ORDER BY age,
salary DESC;
小练习:
1. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序
2. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列
3. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列
#题目1
mysql> select * from employee ORDER BY age asc,hire_date desc;
#题目2
mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) asc;
+-----------+---------------+
| post | avg(salary) |
+-----------+---------------+
| operation | 16800.026000 |
| teacher | 151842.901429 |
+-----------+---------------+
#题目3
mysql> select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) desc;
+-----------+---------------+
| post | avg(salary) |
+-----------+---------------+
| teacher | 151842.901429 |
| operation | 16800.026000 |
+-----------+---------------+
LIMIT 限制查询的记录数
示例:
SELECT * FROM employee ORDER BY salary DESC
LIMIT 3; #默认初始位置为0
SELECT * FROM employee ORDER BY salary DESC
LIMIT 0,5; #从第0开始,即先查询出第一条,然后包含这一条在内往后查5条
SELECT * FROM employee ORDER BY salary DESC
LIMIT 5,5; #从第5开始,即先查询出第6条,然后包含这一条在内往后查5条
小练习:
1. 分页显示,每页5条
mysql> select * from employee limit 0,5;
+----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
| id | emp_name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
| 1 | egon | male | 18 | 2017-03-01 | 老男孩驻沙河办事处外交大使 | NULL | 7300.33 | 401 | 1 |
| 2 | alex | male | 78 | 2015-03-02 | teacher | | 1000000.31 | 401 | 1 |
| 3 | wupeiqi | male | 81 | 2013-03-05 | teacher | NULL | 8300.00 | 401 | 1 |
| 4 | yuanhao | male | 73 | 2014-07-01 | teacher | NULL | 3500.00 | 401 | 1 |
| 5 | liwenzhou | male | 28 | 2012-11-01 | teacher | NULL | 2100.00 | 401 | 1 |
+----+-----------+------+-----+------------+-----------------------------------------+--------------+------------+--------+-----------+
rows in set (0.00 sec)
mysql> select * from employee limit 5,5;
+----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+
| id | emp_name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+
| 6 | jingliyang | female | 18 | 2011-02-11 | teacher | NULL | 9000.00 | 401 | 1 |
| 7 | jinxin | male | 18 | 1900-03-01 | teacher | NULL | 30000.00 | 401 | 1 |
| 8 | 成龙 | male | 48 | 2010-11-11 | teacher | NULL | 10000.00 | 401 | 1 |
| 9 | 歪歪 | female | 48 | 2015-03-11 | sale | NULL | 3000.13 | 402 | 2 |
| 10 | 丫丫 | female | 38 | 2010-11-01 | sale | NULL | 2000.35 | 402 | 2 |
+----+------------+--------+-----+------------+---------+--------------+----------+--------+-----------+
rows in set (0.00 sec)
mysql> select * from employee limit 10,5;
+----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| id | emp_name | sex | age | hire_date | post | post_comment | salary | office | depart_id |
+----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| 11 | 丁丁 | female | 18 | 2011-03-12 | sale | NULL | 1000.37 | 402 | 2 |
| 12 | 星星 | female | 18 | 2016-05-13 | sale | NULL | 3000.29 | 402 | 2 |
| 13 | 格格 | female | 28 | 2017-01-27 | sale | NULL | 4000.33 | 402 | 2 |
| 14 | 张野 | male | 28 | 2016-03-11 | operation | NULL | 10000.13 | 403 | 3 |
| 15 | 程咬金 | male | 18 | 1997-03-12 | operation | NULL | 20000.00 | 403 | 3 |
+----+-----------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
rows in set (0.00 sec)
使用正则表达式查询
SELECT * FROM employee WHERE emp_name REGEXP '^ale';
SELECT * FROM employee WHERE emp_name REGEXP 'on$';
SELECT * FROM employee WHERE emp_name REGEXP 'm{2}';
小结:对字符串匹配的方式
WHERE emp_name = 'egon';
WHERE emp_name LIKE 'yua%';
WHERE emp_name REGEXP 'on$';
小练习:
查看所有员工中名字是jin开头,n或者g结果的员工信息
select * from employee where emp_name regexp '^jin.*[gn]$';
多表查询(联表查询)
准备
建表与数据准备
#建表
create table department(
id int,
name varchar(20)
);
create table employee(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入数据
insert into department values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');
insert into employee(name,sex,age,dep_id) values
('egon','male',18,200),
('alex','female',48,201),
('wupeiqi','male',38,201),
('yuanhao','female',28,202),
('liwenzhou','male',18,200),
('jingliyang','female',18,204)
;
#查看表结构和数据
mysql> desc department;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
mysql> desc employee;
+--------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(11) | YES | | NULL | |
| dep_id | int(11) | YES | | NULL | |
+--------+-----------------------+------+-----+---------+----------------+
mysql> select * from department;
+------+--------------+
| id | name |
+------+--------------+
| 200 | 技术 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+------+--------------+
mysql> select * from employee;
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
表department与employee
多表连接查询
#重点:外链接语法
SELECT 字段列表
FROM 表1 INNER|LEFT|RIGHT JOIN 表2
ON 表1.字段 = 表2.字段;
1 交叉连接:不适用任何匹配条件。生成笛卡尔积
mysql> select * from employee,department;
+----+------------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+----+------------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 1 | egon | male | 18 | 200 | 201 | 人力资源 |
| 1 | egon | male | 18 | 200 | 202 | 销售 |
| 1 | egon | male | 18 | 200 | 203 | 运营 |
| 2 | alex | female | 48 | 201 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 2 | alex | female | 48 | 201 | 202 | 销售 |
| 2 | alex | female | 48 | 201 | 203 | 运营 |
| 3 | wupeiqi | male | 38 | 201 | 200 | 技术 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 202 | 销售 |
| 3 | wupeiqi | male | 38 | 201 | 203 | 运营 |
| 4 | yuanhao | female | 28 | 202 | 200 | 技术 |
| 4 | yuanhao | female | 28 | 202 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 4 | yuanhao | female | 28 | 202 | 203 | 运营 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 201 | 人力资源 |
| 5 | liwenzhou | male | 18 | 200 | 202 | 销售 |
| 5 | liwenzhou | male | 18 | 200 | 203 | 运营 |
| 6 | jingliyang | female | 18 | 204 | 200 | 技术 |
| 6 | jingliyang | female | 18 | 204 | 201 | 人力资源 |
| 6 | jingliyang | female | 18 | 204 | 202 | 销售 |
| 6 | jingliyang | female | 18 | 204 | 203 | 运营 |
+----+------------+--------+------+--------+------+--------------+
2 内连接:只连接匹配的行
#找两张表共有的部分,相当于利用条件从笛卡尔积结果中筛选出了正确的结果
#department没有204这个部门,因而employee表中关于204这条员工信息没有匹配出来
mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee inner join department on employee.dep_id=department.id;
+----+-----------+------+--------+--------------+
| id | name | age | sex | name |
+----+-----------+------+--------+--------------+
| 1 | egon | 18 | male | 技术 |
| 2 | alex | 48 | female | 人力资源 |
| 3 | wupeiqi | 38 | male | 人力资源 |
| 4 | yuanhao | 28 | female | 销售 |
| 5 | liwenzhou | 18 | male | 技术 |
+----+-----------+------+--------+--------------+
#上述sql等同于
mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee,department where employee.dep_id=department.id;
3 外链接之左连接:优先显示左表全部记录
#以左表为准,即找出所有员工信息,当然包括没有部门的员工
#本质就是:在内连接的基础上增加左边有右边没有的结果
mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id;
+----+------------+--------------+
| id | name | depart_name |
+----+------------+--------------+
| 1 | egon | 技术 |
| 5 | liwenzhou | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
| 6 | jingliyang | NULL |
+----+------------+--------------+
4 外链接之右连接:优先显示右表全部记录
#以右表为准,即找出所有部门信息,包括没有员工的部门
#本质就是:在内连接的基础上增加右边有左边没有的结果
mysql> select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id;
+------+-----------+--------------+
| id | name | depart_name |
+------+-----------+--------------+
| 1 | egon | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
| 5 | liwenzhou | 技术 |
| NULL | NULL | 运营 |
+------+-----------+--------------+
5 全外连接:显示左右两个表全部记录
全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果
#注意:mysql不支持全外连接 full JOIN
#强调:mysql可以使用此种方式间接实现全外连接
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id
;
#查看结果
+------+------------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+------+------------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 6 | jingliyang | female | 18 | 204 | NULL | NULL |
| NULL | NULL | NULL | NULL | NULL | 203 | 运营 |
+------+------------+--------+------+--------+------+--------------+
#注意 union与union all的区别:union会去掉相同的纪录
符合条件连接查询
#示例1:以内连接的方式查询employee和department表,并且employee表中的age字段值必须大于25,即找出年龄大于25岁的员工以及员工所在的部门
select employee.name,department.name from employee inner join department
on employee.dep_id = department.id
where age > 25;
#示例2:以内连接的方式查询employee和department表,并且以age字段的升序方式显示
select employee.id,employee.name,employee.age,department.name from employee,department
where employee.dep_id = department.id
and age > 25
order by age asc;
子查询
#1:子查询是将一个查询语句嵌套在另一个查询语句中。 #2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。 #3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字 #4:还可以包含比较运算符:= 、 !=、> 、<等
1 带IN关键字的子查询
#查询平均年龄在25岁以上的部门名
select id,name from department
where id in
(select dep_id from employee group by dep_id having avg(age) > 25);
#查看技术部员工姓名
select name from employee
where dep_id in
(select id from department where name='技术');
#查看不足1人的部门名(子查询得到的是有人的部门id)
select name from department where id not in (select distinct dep_id from employee);
2 带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<> #查询大于所有人平均年龄的员工名与年龄 mysql> select name,age from emp where age > (select avg(age) from emp); +---------+------+ | name | age | +---------+------+ | alex | 48 | | wupeiqi | 38 | +---------+------+ 2 rows in set (0.00 sec) #查询大于部门内平均年龄的员工名、年龄 select t1.name,t1.age from emp t1 inner join (select dep_id,avg(age) avg_age from emp group by dep_id) t2 on t1.dep_id = t2.dep_id where t1.age > t2.avg_age;
3 带EXISTS关键字的子查询
EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。
而是返回一个真假值。True或False
当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询
#department表中存在dept_id=203,Ture
mysql> select * from employee
-> where exists
-> (select id from department where id=200);
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
#department表中存在dept_id=205,False
mysql> select * from employee
-> where exists
-> (select id from department where id=204);
Empty set (0.00 sec)
练习:查询每个部门最新入职的那位员工
company.employee
员工id id int
姓名 emp_name varchar
性别 sex enum
年龄 age int
入职日期 hire_date date
岗位 post varchar
职位描述 post_comment varchar
薪水 salary double
办公室 office int
部门编号 depart_id int
#创建表
create table employee(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
#查看表结构
mysql> desc employee;
+--------------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(3) unsigned | NO | | 28 | |
| hire_date | date | NO | | NULL | |
| post | varchar(50) | YES | | NULL | |
| post_comment | varchar(100) | YES | | NULL | |
| salary | double(15,2) | YES | | NULL | |
| office | int(11) | YES | | NULL | |
| depart_id | int(11) | YES | | NULL | |
+--------------+-----------------------+------+-----+---------+----------------+
#插入记录
#三个部门:教学,销售,运营
insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部
('alex','male',78,'20150302','teacher',1000000.31,401,1),
('wupeiqi','male',81,'20130305','teacher',8300,401,1),
('yuanhao','male',73,'20140701','teacher',3500,401,1),
('liwenzhou','male',28,'20121101','teacher',2100,401,1),
('jingliyang','female',18,'20110211','teacher',9000,401,1),
('jinxin','male',18,'19000301','teacher',30000,401,1),
('成龙','male',48,'20101111','teacher',10000,401,1),
('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),
('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;
#ps:如果在windows系统中,插入中文字符,select的结果为空白,可以将所有字符编码统一设置成gbk
准备表和记录
SELECT
*
FROM
emp AS t1
INNER JOIN (
SELECT
post,
max(hire_date) max_date
FROM
emp
GROUP BY
post
) AS t2 ON t1.post = t2.post
WHERE
t1.hire_date = t2.max_date;
mysql> select (select t2.name from emp as t2 where t2.post=t1.post order by hire_date desc limit 1) from emp as t1 group by post;
+---------------------------------------------------------------------------------------+
| (select t2.name from emp as t2 where t2.post=t1.post order by hire_date desc limit 1) |
+---------------------------------------------------------------------------------------+
| 张野 |
| 格格 |
| alex |
| egon |
+---------------------------------------------------------------------------------------+
rows in set (0.00 sec)
mysql> select (select t2.id from emp as t2 where t2.post=t1.post order by hire_date desc limit 1) from emp as t1 group by post;
+-------------------------------------------------------------------------------------+
| (select t2.id from emp as t2 where t2.post=t1.post order by hire_date desc limit 1) |
+-------------------------------------------------------------------------------------+
| 14 |
| 13 |
| 2 |
| 1 |
+-------------------------------------------------------------------------------------+
rows in set (0.00 sec)
#正确答案
mysql> select t3.name,t3.post,t3.hire_date from emp as t3 where id in (select (select id from emp as t2 where t2.post=t1.post order by hire_date desc limit 1) from emp as t1 group by post);
+--------+-----------------------------------------+------------+
| name | post | hire_date |
+--------+-----------------------------------------+------------+
| egon | 老男孩驻沙河办事处外交大使 | 2017-03-01 |
| alex | teacher | 2015-03-02 |
| 格格 | sale | 2017-01-27 |
| 张野 | operation | 2016-03-11 |
+--------+-----------------------------------------+------------+
rows in set (0.00 sec)
答案一为正确答案,答案二中的limit 1有问题(每个部门可能有>1个为同一时间入职的新员工),我只是想用该例子来说明可以在select后使用子查询
可以基于上述方法解决:比如某网站在全国各个市都有站点,每个站点一条数据,想取每个省下最新的那一条市的网站质量信息
综合练习
init.sql文件内容
/*
数据导入:
Navicat Premium Data Transfer
Source Server : localhost
Source Server Type : MySQL
Source Server Version : 50624
Source Host : localhost
Source Database : sqlexam
Target Server Type : MySQL
Target Server Version : 50624
File Encoding : utf-8
Date: 10/21/2016 06:46:46 AM
*/
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `class`
-- ----------------------------
DROP TABLE IF EXISTS `class`;
CREATE TABLE `class` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`caption` varchar(32) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `class`
-- ----------------------------
BEGIN;
INSERT INTO `class` VALUES ('1', '三年二班'), ('2', '三年三班'), ('3', '一年二班'), ('4', '二年九班');
COMMIT;
-- ----------------------------
-- Table structure for `course`
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`cname` varchar(32) NOT NULL,
`teacher_id` int(11) NOT NULL,
PRIMARY KEY (`cid`),
KEY `fk_course_teacher` (`teacher_id`),
CONSTRAINT `fk_course_teacher` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `course`
-- ----------------------------
BEGIN;
INSERT INTO `course` VALUES ('1', '生物', '1'), ('2', '物理', '2'), ('3', '体育', '3'), ('4', '美术', '2');
COMMIT;
-- ----------------------------
-- Table structure for `score`
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`student_id` int(11) NOT NULL,
`course_id` int(11) NOT NULL,
`num` int(11) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_score_student` (`student_id`),
KEY `fk_score_course` (`course_id`),
CONSTRAINT `fk_score_course` FOREIGN KEY (`course_id`) REFERENCES `course` (`cid`),
CONSTRAINT `fk_score_student` FOREIGN KEY (`student_id`) REFERENCES `student` (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=53 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `score`
-- ----------------------------
BEGIN;
INSERT INTO `score` VALUES ('1', '1', '1', '10'), ('2', '1', '2', '9'), ('5', '1', '4', '66'), ('6', '2', '1', '8'), ('8', '2', '3', '68'), ('9', '2', '4', '99'), ('10', '3', '1', '77'), ('11', '3', '2', '66'), ('12', '3', '3', '87'), ('13', '3', '4', '99'), ('14', '4', '1', '79'), ('15', '4', '2', '11'), ('16', '4', '3', '67'), ('17', '4', '4', '100'), ('18', '5', '1', '79'), ('19', '5', '2', '11'), ('20', '5', '3', '67'), ('21', '5', '4', '100'), ('22', '6', '1', '9'), ('23', '6', '2', '100'), ('24', '6', '3', '67'), ('25', '6', '4', '100'), ('26', '7', '1', '9'), ('27', '7', '2', '100'), ('28', '7', '3', '67'), ('29', '7', '4', '88'), ('30', '8', '1', '9'), ('31', '8', '2', '100'), ('32', '8', '3', '67'), ('33', '8', '4', '88'), ('34', '9', '1', '91'), ('35', '9', '2', '88'), ('36', '9', '3', '67'), ('37', '9', '4', '22'), ('38', '10', '1', '90'), ('39', '10', '2', '77'), ('40', '10', '3', '43'), ('41', '10', '4', '87'), ('42', '11', '1', '90'), ('43', '11', '2', '77'), ('44', '11', '3', '43'), ('45', '11', '4', '87'), ('46', '12', '1', '90'), ('47', '12', '2', '77'), ('48', '12', '3', '43'), ('49', '12', '4', '87'), ('52', '13', '3', '87');
COMMIT;
-- ----------------------------
-- Table structure for `student`
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`gender` char(1) NOT NULL,
`class_id` int(11) NOT NULL,
`sname` varchar(32) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_class` (`class_id`),
CONSTRAINT `fk_class` FOREIGN KEY (`class_id`) REFERENCES `class` (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `student`
-- ----------------------------
BEGIN;
INSERT INTO `student` VALUES ('1', '男', '1', '理解'), ('2', '女', '1', '钢蛋'), ('3', '男', '1', '张三'), ('4', '男', '1', '张一'), ('5', '女', '1', '张二'), ('6', '男', '1', '张四'), ('7', '女', '2', '铁锤'), ('8', '男', '2', '李三'), ('9', '男', '2', '李一'), ('10', '女', '2', '李二'), ('11', '男', '2', '李四'), ('12', '女', '3', '如花'), ('13', '男', '3', '刘三'), ('14', '男', '3', '刘一'), ('15', '女', '3', '刘二'), ('16', '男', '3', '刘四');
COMMIT;
-- ----------------------------
-- Table structure for `teacher`
-- ----------------------------
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`tid` int(11) NOT NULL AUTO_INCREMENT,
`tname` varchar(32) NOT NULL,
PRIMARY KEY (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `teacher`
-- ----------------------------
BEGIN;
INSERT INTO `teacher` VALUES ('1', '张磊老师'), ('2', '李平老师'), ('3', '刘海燕老师'), ('4', '朱云海老师'), ('5', '李杰老师');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
从init.sql文件中导入数据
#准备表、记录
mysql> create database db1;
mysql> use db1;
mysql> source /root/init.sql
表结构为
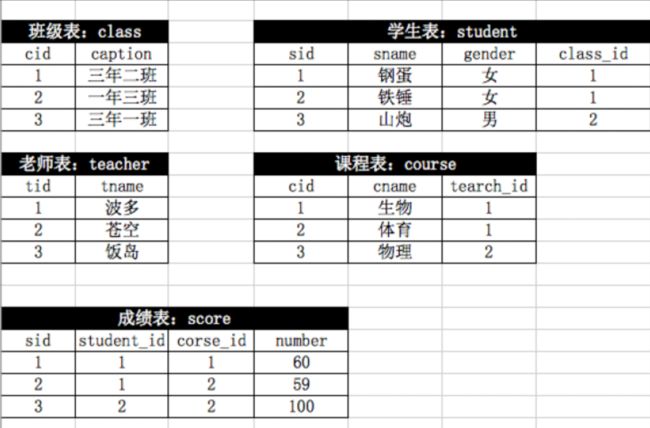
1、查询男生、女生的人数;
2、查询姓“张”的学生名单;
3、课程平均分从高到低显示
4、查询有课程成绩小于60分的同学的学号、姓名;
5、查询至少有一门课与学号为1的同学所学课程相同的同学的学号和姓名;
6、查询出只选修了一门课程的全部学生的学号和姓名;
7、查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分;
8、查询课程编号“2”的成绩比课程编号“1”课程低的所有同学的学号、姓名;
9、查询“生物”课程比“物理”课程成绩高的所有学生的学号;
10、查询平均成绩大于60分的同学的学号和平均成绩;
11、查询所有同学的学号、姓名、选课数、总成绩;
12、查询姓“李”的老师的个数;
13、查询没学过“张磊老师”课的同学的学号、姓名;
14、查询学过“1”并且也学过编号“2”课程的同学的学号、姓名;
15、查询学过“李平老师”所教的所有课的同学的学号、姓名;
1、查询没有学全所有课的同学的学号、姓名;
2、查询和“002”号的同学学习的课程完全相同的其他同学学号和姓名;
3、删除学习“叶平”老师课的SC表记录;
4、向SC表中插入一些记录,这些记录要求符合以下条件:①没有上过编号“002”课程的同学学号;②插入“002”号课程的平均成绩;
5、按平均成绩从低到高显示所有学生的“语文”、“数学”、“英语”三门的课程成绩,按如下形式显示: 学生ID,语文,数学,英语,有效课程数,有效平均分;
6、查询各科成绩最高和最低的分:以如下形式显示:课程ID,最高分,最低分;
7、按各科平均成绩从低到高和及格率的百分数从高到低顺序;
8、查询各科成绩前三名的记录:(不考虑成绩并列情况)
9、查询每门课程被选修的学生数;
10、查询同名同姓学生名单,并统计同名人数;
11、查询每门课程的平均成绩,结果按平均成绩升序排列,平均成绩相同时,按课程号降序排列;
12、查询平均成绩大于85的所有学生的学号、姓名和平均成绩;
13、查询课程名称为“数学”,且分数低于60的学生姓名和分数;
14、查询课程编号为003且课程成绩在80分以上的学生的学号和姓名;
15、求选了课程的学生人数
16、查询选修“杨艳”老师所授课程的学生中,成绩最高的学生姓名及其成绩;
17、查询各个课程及相应的选修人数;
18、查询不同课程但成绩相同的学生的学号、课程号、学生成绩;
19、查询每门课程成绩最好的前两名;
20、检索至少选修两门课程的学生学号;
21、查询全部学生都选修的课程的课程号和课程名;
22、查询没学过“叶平”老师讲授的任一门课程的学生姓名;
23、查询两门以上不及格课程的同学的学号及其平均成绩;
24、检索“004”课程分数小于60,按分数降序排列的同学学号;
25、删除“002”同学的“001”课程的成绩;