softmax with cross-entropy loss求导(转载+细节整理)
softmax 函数
softmax(柔性最大值)函数,一般在神经网络中, softmax可以作为分类任务的输出层。
其实可以认为softmax输出的是几个类别选择的概率,比如我有一个分类任务,要分为三个类,softmax函数可以根据它们相对的大小,输出三个类别选取的概率,并且概率和为1。
即总共有 k k k类,必有:
∑ k = 1 C y i = 1 \sum_{k=1}^Cy_i=1 k=1∑Cyi=1
为了方便下面的推导,先来个图示:
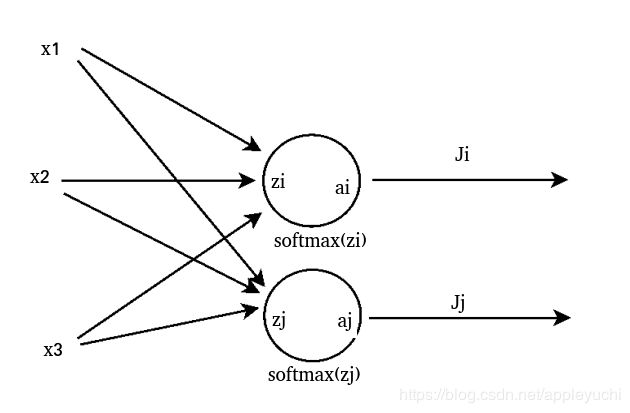
----------------------------------------
softmax函数的公式是这种形式:
a i = e z i ∑ k e z k a_i=\frac{e^{z_i}}{\sum_k^{e^{z_k}}} ai=∑kezkezi
其中:
w i j w_{ij} wij:第 i i i个神经元的第 j j j个权重,
b:偏移值。
z i z_i zi:该网络的第 i i i个输出。
在 z i z_i zi后面施加softmax函数,得到 a i a_i ai
损失函数使用Cross_Entropy
----------------------------------------
J = − ∑ i y i l n a i J=-\sum_i{y_i}ln\ a_i J=−i∑yiln ai
其中:
a i a_i ai:模型预测值
y i y_i yi:预期数值
当二分类时,有
1 N ∑ n = 1 N [ p n l o g q n + ( 1 − p n ) l o g ( 1 − q n ) ] \frac{1}{N}\sum_{n=1}^N[p_nlogq_n+(1-p_n)log(1-q_n)] N1n=1∑N[pnlogqn+(1−pn)log(1−qn)]
其中:
N N N:数据集的总数
p n p_n pn:真实分布
q n q_n qn:预测分布
----------------------------------------------
这篇博客中,我们的目标函数是:
∂ J ∂ z i \frac{\partial J}{\partial z_i} ∂zi∂J
= ∑ j ( ∂ J j ∂ a j ∂ a j ∂ z i ) =\sum_j(\frac{\partial J_j}{\partial a_j}\frac{\partial a_j}{\partial z_i}) =j∑(∂aj∂Jj∂zi∂aj)
其中:
∂ J j ∂ a j \frac{\partial J_j}{\partial a_j} ∂aj∂Jj
= − − y j ⋅ l n a j ∂ a j =-\frac{-y_j·ln a_j}{\partial a_j} =−∂aj−yj⋅lnaj
= − y j 1 a j =-y_j\frac{1}{a_j} =−yjaj1
∂ a j ∂ z i \frac{\partial a_j}{\partial z_i} ∂zi∂aj
= ∂ [ e z j ∑ k e z k ] ∂ z i =\frac{\partial[ \frac{e^{z_j}}{ \sum_k e^{z_k} }]}{\partial z_i} =∂zi∂[∑kezkezj]
下面分情况,这里之所以要分情况是求导的规律来决定的:
∂ [ e z j ∑ k e z k ] ∂ z i ( 1 ) \frac{\partial[ \frac{e^{z_j}}{ \sum_k e^{z_k} }]}{\partial z_i}(1) ∂zi∂[∑kezkezj](1)
为了处理式(1),根据:
f ( x ) = g ( x ) h ( x ) f(x)=\frac{g(x)}{h(x)} f(x)=h(x)g(x)
f ′ ( x ) = g ′ ( x ) h ( x ) − g ( x ) h ′ ( x ) ∣ h ( x ) ∣ 2 f'(x)=\frac{g'(x)h(x)-g(x)h'(x)}{|h(x)|^2} f′(x)=∣h(x)∣2g′(x)h(x)−g(x)h′(x)
所以这里:
g ( x ) = e z j g(x)=e^{z_j} g(x)=ezj
h ( x ) = ∑ k e z k h(x)={\sum_k e^{z_k}} h(x)=∑kezk
① i = j 时 , g ′ ( x ) = e z j , h ′ ( x ) = e z j i=j时,g'(x)=e^{z_j},h'(x)=e^{z_j} i=j时,g′(x)=ezj,h′(x)=ezj
② i i i≠j 时 , g ′ ( x ) = 0 , h ′ ( x ) = e z j 时,g'(x)=0,h'(x)=e^{z_j} 时,g′(x)=0,h′(x)=ezj
由此处理式(1)得到:
① i = j 时 i=j时 i=j时
∂ a j ∂ z i = e z i ∑ k e z k − ( e z i ) 2 [ ∑ k e z k ] 2 = a i − a i 2 \frac{\partial a_j}{\partial z_i}=\frac{e^{z_i}{\sum_k e^{z_k}}-(e^{z_i})^2}{[ { \sum_k e^{z_k} }]^2}=a_i-a_i^2 ∂zi∂aj=[∑kezk]2ezi∑kezk−(ezi)2=ai−ai2
① i i i≠ j 时 j时 j时
∂ a j ∂ z i = − ( e z j ) ( e z i ) [ ∑ k e z k ] 2 = − a j ⋅ a i \frac{\partial a_j}{\partial z_i}=\frac{-(e^{z_j})(e^{z_i})}{[ { \sum_k e^{z_k} }]^2}=-a_j·a_i ∂zi∂aj=[∑kezk]2−(ezj)(ezi)=−aj⋅ai
总结下:
∂ J ∂ z i \frac{\partial J}{\partial z_i} ∂zi∂J
= ∑ j ( ∂ J j ∂ a j ∂ a j ∂ z i ) =\sum_j (\frac{\partial J_j}{\partial a_j} \frac{\partial a_j}{\partial z_i}) =j∑(∂aj∂Jj∂zi∂aj)
= ∑ i = j [ ( − y j a j ) ( a i − a i 2 ) ] + ∑ i ≠ j [ ( − y j a j ) ( − a j a i ) ] =\sum_{i=j}[(\frac{-y_j}{a_j})(a_i-a_i^2)]+\sum_{i \ne j}[(\frac{-y_j}{a_j})(-a_ja_i)] =i=j∑[(aj−yj)(ai−ai2)]+i̸=j∑[(aj−yj)(−ajai)]
= − y i ( 1 − a i ) + ∑ i ≠ j [ y j a i ] =-y_i(1-a_i)+\sum_{i \ne j}[y_ja_i] =−yi(1−ai)+i̸=j∑[yjai]
= − y i + a i ∑ j y j =-y_i+a_i\sum_jy_j =−yi+aij∑yj
∵ ∑ j y j = 1 ( 因 为 所 有 情 况 的 概 率 和 为 1 ) ∵ \sum_j y_j=1(因为所有情况的概率和为1) ∵j∑yj=1(因为所有情况的概率和为1)
∴ 原 式 = − y i + a i ∴原式=-y_i+a_i ∴原式=−yi+ai
参考链接:
https://blog.csdn.net/Charel_CHEN/article/details/81266838
https://blog.csdn.net/qian99/article/details/78046329
https://zhuanlan.zhihu.com/p/27223959
http://shuokay.com/2016/07/20/softmax-loss/