Spark RDD算子应用案例(1)
这道小题目非常经典,可以有很多种做法,我列出了一种最直白易懂的做法。如果有更多简洁的方法,欢迎在评论区指教,我也很乐衷于探索每道题的不同解法~
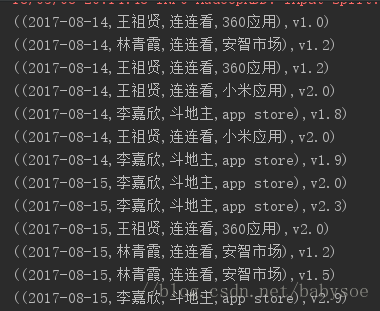
数据格式为:
日期,姓名,app,下载渠道,地区,版本号
2017-08-14,王祖贤,连连看,360应用,北京,v1.0
2017-08-14,林青霞,连连看,安智市场,北京,v1.2
2017-08-14,王祖贤,连连看,360应用,天津,v1.2
2017-08-14,王祖贤,连连看,小米应用,天津,v2.0
2017-08-14,李嘉欣,斗地主,app store,上海,v1.8
2017-08-14,王祖贤,连连看,小米应用,天津,v2.0
2017-08-14,李嘉欣,斗地主,app store,上海,v1.9
2017-08-15,李嘉欣,斗地主,app store,上海,v2.0
2017-08-15,李嘉欣,斗地主,app store,上海,v2.3
2017-08-15,王祖贤,连连看,360应用,北京,v2.0
2017-08-15,林青霞,连连看,安智市场,北京,v1.2
2017-08-15,林青霞,连连看,安智市场,北京,v1.5
2017-08-15,李嘉欣,斗地主,app store,上海,v2.9
需求:
不考虑地区,列出版本升级情况,
结果格式:
日期,姓名,app,下载渠道,升级前版本,升级后版本
例:
数据:
2017-08-14,王祖贤,连连看,360应用,北京,v1.0
2017-08-14,王祖贤,连连看,360应用,天津,v1.2
2017-08-14,王祖贤,连连看,360应用,天津,v2.0
结果:
(2017-08-14,王祖贤,连连看,360应用,v1.0,v1.2)
(2017-08-14,王祖贤,连连看,360应用,v1.2,v2.0)
实现代码:
//创建sc对象 设置模式为本地
val conf: SparkConf = new SparkConf()
.setMaster("local")
.setAppName(this.getClass.getSimpleName)
val sc: SparkContext = new SparkContext(conf)
//读取文件
val line: RDD[String] = sc.textFile("appupgrade.txt")
//切割数据,城市字段不需要,可忽略
val rdd1: RDD[((String, String, String, String), String)] = line.map(t => {
val arr: Array[String] = t.split(",")
((arr(0), arr(1), arr(2), arr(3)), arr(5))
})
//按key分组
val rdd2: RDD[((String, String, String, String), Iterable[String])] = rdd1.groupByKey()
分组后,发现每组中有重复数据,以及单个数据,要把他们过滤掉
//去重,过滤
val rdd3: RDD[((String, String, String, String), List[String])] = rdd2.mapValues(t=>t.toList.distinct).filter(t=>t._2.length>1)
如图,要把每组的value进行拆分组合,这里用到zip()算子,把List的尾列表提取出来,与List进行zip()
val zip: RDD[((String, String, String, String), List[(String, String)])] = rdd3.mapValues(t => {
val tail: List[String] = t.tail
t.zip(tail)
})
结果:
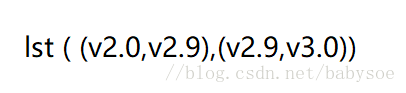
最后,对结果进行格式整理
val res: RDD[(String, String, String, String, String, String)] = zip.flatMap(t => {
t._2.map(tp => {
(t._1._1, t._1._2, t._1._3, t._1._4, tp._1, tp._2)
})
})
完成!