Flume架构与实践
Flume架构与实践
系列文章目录
- Flume架构与实践
- Flume学习-小项目实例
转载声明:
本文大量内容系转载自以下文章,有删改,并参考其他文档资料加入了一些内容:
- Flume架构与实践
- 作者:mike_zhangliang
- 出处:数据通道团队
转载仅为方便学习查看,一切权利属于原作者,本人只是做了整理和排版,如果带来不便请联系我删除。
摘要
Apache Flume,现为Apache顶级项目。
他是一款分布式的,可靠的,高可用的高效数据采集、聚合系统,可以从不同数据源把数据导入集中式的数据存储。
具体来说,Flume 是一款实时ETL系统,典型的应用场景是作为数据总线,实时的进行日志采集、分发与存储,它是一个微内核,可扩展的架构设计。
0x01 Flume 基本概念

1.1 Client
可以参考Flume NG 学习笔记(九)Flune Client 开发
它主要用于生产Events,并将它们发送到一个或多个Agents,常见的有 log4j Appender、LoadBalancingRpcClient、FailoverRpcClient,它不是部署图中的必须部分。
1.2 Configuration
一个配置文件可以同时配置多个Agent,只有指定agent名称相关的配置才会被加载,配置错误的组件在加载的时候输出一个条告警日志,然后会被忽略,Agent支持配置的动态加载。
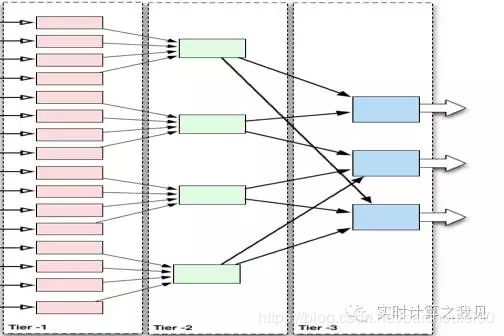
1.3 Agent
- 它是一个拥有
Sources、Channels、Sinks,并将events对象进行透明传输的JVM进程。 - Agent是Flume的
Event数据流的基础组件,提供了生命周期管理、配置动态生效、数据流监控等基本功能。
1.4 Source
它是数据源,从特定渠道接受Events,将它存储到Channel中。
1.5 Channel
它缓存接收到的events直到它们被Sinks节点消费完成,不同的Channel提供不同持久化层级。
1.6 Sink
它主要从特定的Channel中获取数据,将数据可靠的传输到下一个目的地(外部存储或下一个flume-agent)
1.7 Event
Flume Event被定义为数据传输基本单元,他拥有字节负载及可选的String属性集。具体来说,Event由 数据 和 header域信息 构成。header域信息的开销对整个数据采集来说是透明的,是由K-V构成的Map信息,主要用于上下文路由。
0x02 Flume 架构
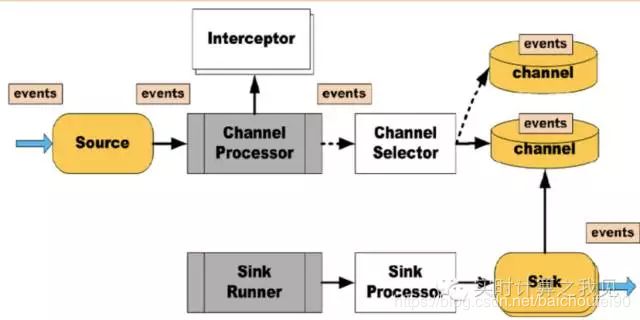
2.1 基本流程
- 客户端发送
events到Agents。 - Agent拥有
Source,Interceptors,Channel Selectors,Channels,Sink Processors,Sinks等组件。 - Source 接受Events, 经过Interceptor(s)过滤 , 根据Channel Selector将它们放置到channel(s)中.
Sink Processor选择一个Sink从指定的Channel获取Events发送到配置的下一跳节点.- Channel 的存、取操作是通过
事务保证了单节点的消息投递的可靠性;Channel 持久化保证了端到端的可靠性。
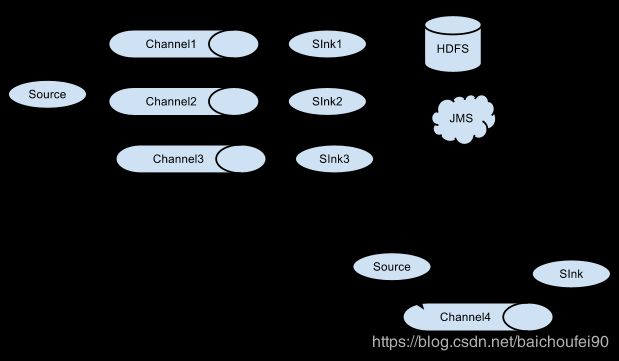
2.2 典型组织
fooAgent通过Avro sink流向下一个barAgent的Avro source

- 多个WebServer通过RPC发送到各自的
Avro-Agent,他们都通过Avro sink发送到第二层的一个或一组Avro-SouceAgent中,汇集数据后最终数据流入HDFS.

- 一个Source,以复制或可配路由选择方式传入不同Channel,Sink入不同目的地:
0x03 Flume-Source

3.1 Source基本概念
- 从外部的Client或者内部的Sink接收events。
- 将接收到的events存到配置的channel(s),保证操作的“事务性”。
- 数据的分流到不同的目的地
3.2 Source的可靠性
- channel侧的put数据的事务保证
- 可靠外部客户端的的异常重试(
Avrosink、LoadBalancingRpcClient)
3.3 Source分类
常见Source分类如下:
3.3.1 Agent-to-Agent 的Source
3.3.1.1 avro
启动一个Avro Server,可与上一级Agent连接
3.3.1.2 http
- 启动一个HttpServer来接收通过HTTP POST和GET(只能再测试时使用) 请求提交的Flume Event。这些HTTP请求会被提交给可插拔的
handler处理转换为Flume Event。 - 批处理和事务性
同一个HTTP请求中的所有Event会在一个事务中被批量提交给Channel,从而使得在诸如File-channel之类的Channel上提高效率。
3.3.2 产生Event的 Source
- exec
执行unix command,获取标准输出,如tail -f - spooldir
监听目录下新增文件 - TAILDIR
监听目录或文件
3.3.3 与第三方对接的Source
- com.jumei.flume.source.kafka.KafkaOffsetSource
- NetCat Source
- Syslog Sources
- jms
0x04 Flume-Channel
4.1 Channel基本概念
- Channel作为sources/sinks间的Buffer,能有效抵挡下游消费者的短暂的不可用,下游消费者的消费速度的不匹配,可看做内部MQ。
- 解耦了
source、sink以及upstream与downstream的依赖关系,是整个Flow可靠性、可用性的关键所在。 - 所有的Channel的存取操作都有
事务机制的保证,支持source写失败时重复写以及sink读失败时重复读等。事务对顺序性是一种弱保护的机制。 - Channel是线程安全的。
4.2 Channel的事务

Channel事务的目标是保证消息的At Least Once 消费,事务是Channel强相关的,它保证了Events 一旦committed 到一个channel ,它只有在下游消费者消费并返回了committed后才会从队列中移除。

具体事务流程如下:
- Source 1 产生的
Event,putandcommitted到 Channel 1 - Sink 1 从 Channel 1中获取
Event并发送到Source 2。 - Source 2
putsandcommits到Channel 2。 - Source 2 发送成功到 Sink 1. Sink 1 发送
commits确认已“take“成功,将这个event从channel1中删除。 - 这样就保证了
一批数据的操作的事务性
4.3 Channel分类
常用channel如下:
4.3.1 memory
存于配置了最大容量的内存队列,速度快,适用于追求高吞吐量且能容忍部分数据丢失的场景。
- 事务
其中transactionCapacity可以配置每个事务中,Channel从Source里获取或Channel传给Sink的events数量。
4.3.2 file
以WAL文件为支持,保证数据的本地持久化,重启数据不丢失。
将Event追加方式顺序写入File Channel文件末尾,通过maxFileSize设置该文件大小阈值。当数据文件中的Event已被读取且该文件已关闭,还接收到了Sink提交过来的已经读取该文件数据完成的事务,则Flume此时会删除该文件。
- 事务
其中transactionCapacity可以配置每个事务中,Channel从Source里获取或Channel传给Sink的events数量。
具体写入File-Channel流程如下:
- events以指定大小存储在log files,并持久化到磁盘中
- 而指向event的指针(logID+offset)存放在内存队列中
- queue当前的状态就是events的当前存储状态
- queue会被周期性的同步到磁盘中- checkpoint
- channel重启时checkpoint-mmap-ed
- 从上次checkpoint发生的put/take/commit/rollback 通过日志回放恢复
4.3.3 kafka
将events存于单独安装的Kafka集群中,由Kafka保证高可用性。使用于以下场景:
- Flume source, sink:可为
events提供可靠性和高可用行 - Flume source, interceptor:此方式可将source数据高效写入Kafka
- Flume sink:将Kafka中的
events以低延时地、错误容忍地方式发送给下游 source,如 HDFS, HBase, Solr等
4.3.4 jdbc
以嵌入式的Derby数据库进行events持久化,适用于对可恢复性要求高的场景。
0x05 Flume-Sink
5.1 Sink基本概念
- 它主要从特定的Channel中获取数据,将数据可靠的传输到下一个目的地。
- 一个Sink有且只能从一个Channel消费event
- 用事务可保证
At least once地消费。具体来说,当Sink写的event成功时,就会向Channel提交一个事务:如果该事务提交成功,则表示该event被处理完成,将删除该event;否则Channel会等待Sink重新消费处理失败的event
5.2 Sink分类
常见Sink分类如下:
- Terminal sink
- HDFS Sink
- Hive Sink
Sink流包含已分隔的文本或JSON数据,可直接写入Hive表或partition(分区可提前创建或Flume自动创建)。且写入过程使用了Hive事务。一旦一个Event集被提交到Hive,他们会立刻对Hive查询可见。该HiveSink在1.6.0版本中不推荐使用,1.8.0删除了这个提示。 - HBaseSink
Sink写入转为HBase的 put,拥有HBase的行级原子一致性保证 - AsyncHBaseSink
- File Roll Sink
- ElasticSearchSink
- KafkaSink
- Agent-to-Agent Sink
- Avro Sink
- ThriftSink
0x06 Interceptor

Interceptor主要用来对流入Source的Event对象进行修饰和过滤(不return该Event即可,或不return 整个Event List代表丢弃所有Event),当前内置的Interceptors支持添加时间戳、主机、静态标签等header域信息;支持用户自定义的Interceptor。
Flume支持多个Interceptor组成链式结构,执行顺序按在配置文件的指定顺序执行。执行链中的前一个interceptor return 的 Event会传递到下一个 interceptor。示例如下:
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.HostInterceptor$Builder
a1.sources.r1.interceptors.i1.preserveExisting = false
a1.sources.r1.interceptors.i1.hostHeader = hostname
a1.sources.r1.interceptors.i2.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
a1.sinks.k1.filePrefix = FlumeData.%{CollectorHost}.%Y-%m-%d
a1.sinks.k1.channel = c1
0x07 Selector
7.1 Selector简介
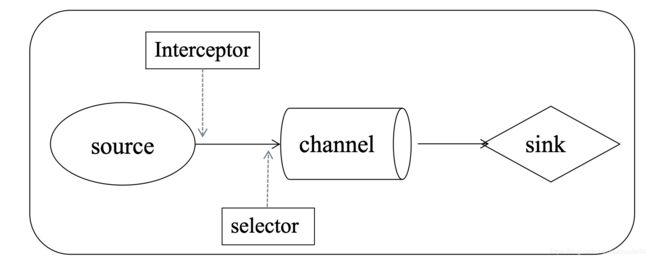
Source在将Event写入Channel之前会先调用Interceptor,等全部处理完后,再调用selector。
selector允许Source根据Event header 域的标签信息,从所有的Channels中选出Event对应的Channel进行发送。
7.2 Selector分类
目前内置的Channel Selectors有两类。
7.2.1 Replicating(默认)
将Event以复制的方式应用到所有对应Channel中。
7.2.2 Multiplexing
7.2.2.1 概念
多路复用Selector。可根据Event header域信息来选择要写入的目标Channel。
7.2.2.2 实例
agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing
agent_foo.sources.avro-AppSrv-source1.selector.header = State
agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.optional.CA = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
该例子中,挑选header域为State的Event。
并根据Value不同取值放入不同Channel,还设了不匹配任何header时默认Channel为mem-channel-1。
Selector将首先尝试写入所需的Channel(非Optional),若其中一个Channel无法消费Event,会造成事务失败。 此时,该事务会在所有Channel上重新尝试。 一旦所有必需的Channel消耗了Event,则Selector将尝试写入optional Channel。 任何optional Channel消耗该Event的失败都会被忽略而不会重试。
当在非/是optional Channel中存在重叠的header,则该Channel被认为是required(必须的)。当Event写入这类Channel中时失败,会导致重试写入到所有配置的required Channel。
没有匹配到非optional Channel的header,会将该Event写入默认Channel,还会尝试写入该header配置的optional Channel。
0x08 Flume的可用性
8.1 Flume整体可用性
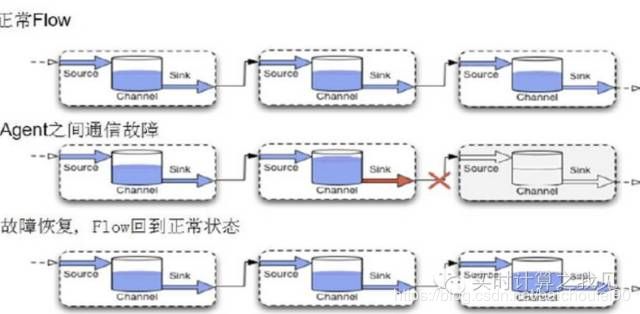
8.2 Client可用性
LoadBalancingRpcClient、FailoverRpcClient ,保证了Client侧的高可用性。
8.3 Channel可用性
Memory Channel、FileChannel、Kafka Channel的可用性递增,性能递减。
8.4 Sink Processor

SinkProcessor主要作用是对多个Sink进行负载均衡和自动Failover。

具体来说,SinkProcessor负责从指定的SinkGroup中调用一个Sink节点,由 Sink Runner负责调度,类似做了一层代理;一个Sink节点只能存在于一个SinkProcessor中,如果没有配置任何SinkGroup,默认是在Default Sink Processor中。目前内置Sink Process有 Load Balancing Sink Processor–RANDOM,ROUND_ROBIN、Failover Sink Processor、Default Sink Processor。
0x09 Flume的可靠性
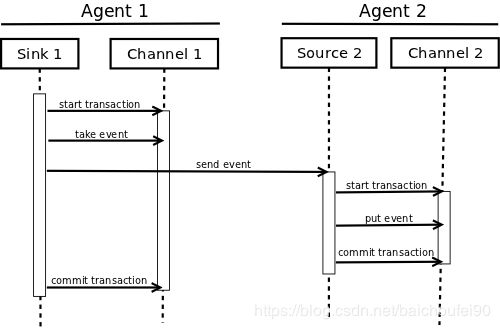
- 可靠的端到端单跳Agent消息传递语义
Event在Agent之间中转时会暂存到channel中,然后才被发送到下一个Agent或其他存储目的地。仅当该Event已经被成功发送到下一个Agent的channel中或其他存储目的地时,才会从当前Channel中移除该Event。 - 事务
Flume使用事务方法来保证Event的可靠传递。Sources和Sinks分别在事务中封装由 Channel提供的事务 中放置或提供的Event的存储/检索。 这可确保Events在流中从点到点可靠地传递。
在多跳流的情况下,来自前一跳的Source和来自下一跳的Source都使用了事务,以确保数据安全地存储在下一跳的Channel中。 - Channel的事务
保证了Agent间数据交换的At least once消费、内置的负载均衡和Failover机制 - 可恢复性
Channel的持久化(如File-Channel)保证了Agent挂了之后的可恢复性,保证了消息的At least once消费 - 节点不可用
- 通过冗余的topologies来解决, Flume 允许你将你数据流复制到冗余的topologies,这个对于应对磁盘损坏和单点失效有用,代价较大,topology会比较复杂。
- 如果承载channel的磁盘做了Raid,重新挂在,启动agent,也能很快的进行数据恢复,例如Kafka channel/JDBC Channel
- 允许部分数据的丢失。
- 概率较小,推荐在应用层进行回放的操作。
0x10 Flume 的调优
- 选择正确的Channel
- memory channel:低延时,高吞吐,可靠性弱。
- file channel:延时相对高,吞吐相对小,可靠性较高。
- disk-based channels 10’s of MB/s
- memory based channels 100’s of MB/s
- 选择合适的capacity
根据你容忍的down机时间而定,capacity越大,恢复需要的时间越长,同时存在消费延时的问题。 - 选择合适的batch size
batch size越大吞吐量越高,异常重传的代价高,一般推荐 100 or 1,000 or 10,000 这个跟单个event的大小也有关 - client 与 agent的比例配比
20:1 or 30:1 的客户端agent比例比较适中 - GC参数的选择
根据应用的具体情况进行调优 - agent的监控
通过agent暴露的metrice服务,关注ChannelSize 找到数据流中的瓶颈
http://10.0.52.28:34545/metrics
0x11 Flume应用
11.1 业界应用
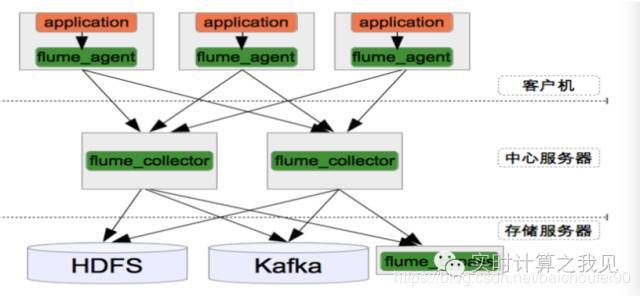
11.2 该作者应用

使用的是
Client+Avro Source+ Replicating/ Multiplexing+TimeStampInterceptor+FileChannel/MemChannel+Failover sink Processr/Loadbalance SinkProcess+HdfsSink/ ElasticSink/FileSink/CustomSource。