VOT2019——数据集
刚刚发现VOT2019的数据可以down了,就马上下下来来看。
和2018的短时序列相比,2019仍然是60个序列,有重复的,也有新的。
列表
1 : agility
2 : ants1
3 : ball2
4 : ball3
5 : basketball
6 : birds1
7 : bolt1
8 : book
9 : butterfly
10 : car1
11 : conduction1
12 : crabs1
13 : dinosaur
14 : dribble
15 : drone1
16 : drone_across
17 : drone_flip
18 : fernando
19 : fish1
20 : fish2
21 : flamingo1
22 : frisbee
23 : girl
24 : glove
25 : godfather
26 : graduate
27 : gymnastics1
28 : gymnastics2
29 : gymnastics3
30 : hand
31 : hand2
32 : handball1
33 : handball2
34 : helicopter
35 : iceskater1
36 : iceskater2
37 : lamb
38 : leaves
39 : marathon
40 : matrix
41 : monkey
42 : motocross1
43 : nature
44 : pedestrian1
45 : polo
46 : rabbit
47 : rabbit2
48 : road
49 : rowing
50 : shaking
51 : singer2
52 : singer3
53 : soccer1
54 : soccer2
55 : soldier
56 : surfing
57 : tiger
58 : wheel
59 : wiper
60 : zebrafish11、14、31、37、39、41、45、47、49、56、58等是新加的,快去练手!
baidu 盘:链接:https://pan.baidu.com/s/1qDwQVIUnZ177c7y2ZyUL8g
提取码:l4rl
csdn:
前30个序列
后30个序列
命令行直接下载:链接:https://pan.baidu.com/s/1hCHf1vpWR_qQpziaqFwZiw
提取码:qw8d
这是windows的.cmd文件,利用chrome下载,需要将Chrome添加至环境变量。
先down下来,然后再remove
可视化代码:
import numpy as np
import cv2
import os
list0=[]
target_name='dribble'
file_paath='E:/vot2019/'+target_name+'/'
#file_dir=file_paath+'img//'
# resu_dir=file_paath+'results//'
target_path = "E:/vot2019/"
# is_reslt_dir_exi=os.path.exists(resu_dir)
# if not is_reslt_dir_exi:
# os.makedirs(resu_dir)
# print("--- ... new folder... ---")
# print("--- ...OK... ---")
# else:
# print("--- There is this folder! ---")
for files in os.walk(file_paath):
list0.append(files)
img_list=[]
for ii in list0[0][2]:
if(ii.split('.')[-1]=='jpg'):
img_list.append(ii)
list_img_name=np.array(img_list)
list_img_name.sort()
# print(list_img_name)
path = file_paath+'/''groundtruth.txt'
data=[]
for line2 in open(path):
data.append(line2)
#print(line2)
data1=[]
for i in data:
data1.append(i[:len(i)-1])
data2=[]
data3=[]
for j in data1:
data2.append(j.split(','))
# print(data2[1])
data4=[]
for k in data2:
data3=np.array([0.0 if y=='' else float(y) for y in k])
data4.append(data3)
data_rect=np.array(data4)
# for jj in data_rect:
# print(jj)
for num in range(0,len(list_img_name)):
if len(data_rect[num])>2:
x1=int(data_rect[num][0])
y1=int(data_rect[num][1])
x2=int(data_rect[num][2])
y2=int(data_rect[num][3])
x3=int(data_rect[num][4])
y3=int(data_rect[num][5])
x4=int(data_rect[num][6])
y4=int(data_rect[num][7])
# print(x,y,w,h)
img_file_name=file_paath+str(list_img_name[num])
print(img_file_name)
src=cv2.imread(img_file_name)
# cv2.imshow('aa',src)
# cv2.waitKey(0)
cv2.line(src,(x1,y1),(x2,y2),(0,0,255),thickness=1)
cv2.line(src,(x2,y2),(x3,y3),(0,0,255),thickness=1)
cv2.line(src,(x3,y3),(x4,y4),(0,0,255),thickness=1)
cv2.line(src,(x4,y4),(x1,y1),(0,0,255),thickness=1)
cv2.imshow(target_name,src)
cv2.waitKey(0)
# save_file_name=resu_dir+str(list_img_name[num])
#print(save_file_name)
# cv2.imwrite(save_file_name,src)有人可能会疑惑数据如何获取的
我把我获取过程说一下:
进vot-tookit官网,看到stack文件夹
进去以后看到很多的.m文件,=。=找到vot2019
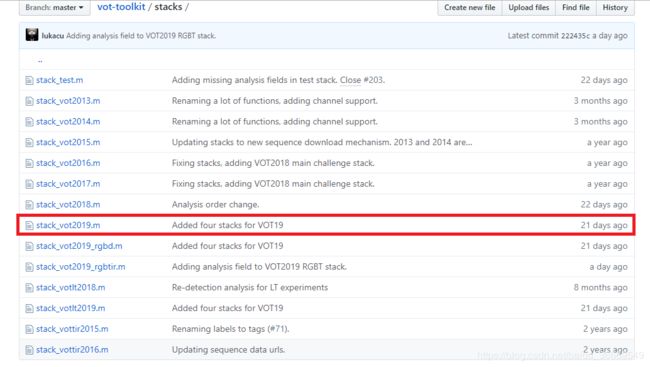
双击打开
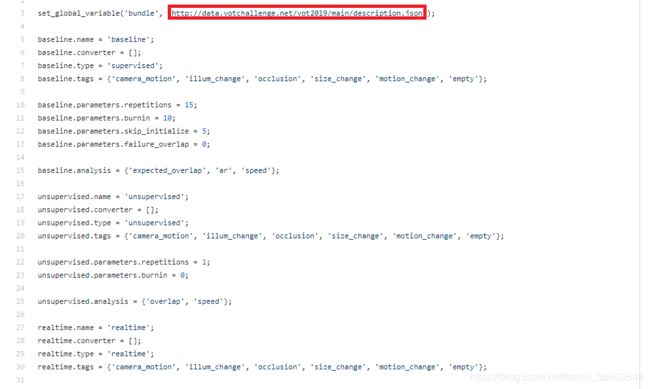
上面那个.json的网址存放着vot2019 的数据,我们打开这个链接
{
"homepage": "http://data.votchallenge.net/",
"name": "VOT19 Challenge",
"sequences": [
{
"annotations": {
"checksum": "21b2db18f226a10d66e527a53999136d108f2b00",
"compressed": 5650,
"uid": "46f03a3f3ebb584c99034e8391403dc740814d315e8e6259f407b59688f181b2b95831af258698e19da36e7a75d7cb5021a3781f2c300cf1c715aff317c8c656",
"uncompressed": 5522,
"url": "agility.zip"
},
"channels": {
"color": {
"checksum": "d295e024dad03e203b8963ad992d96413a7e37b4",
"compressed": 3153822,
"pattern": "%08d.jpg",
"uid": "619736ae62946f3dac03c6a10154dcdecfb792c5fbebd81ffba40070b138f075f8fb5c977300c46d7b89535787688a6c75acca1ea25a24c74aa97278ca448d25",
"uncompressed": 3149622,
"url": "../../sequences/619736ae62946f3dac03c6a10154dcdecfb792c5fbebd81ffba40070b138f075f8fb5c977300c46d7b89535787688a6c75acca1ea25a24c74aa97278ca448d25.zip"
}
},
"fps": 30,
"height": 480,
"length": 100,
"name": "agility",
"preview": null,
"thumbnail": "agility.png",
"width": 854
},
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
..............................
],
"timestamp": "2019-04-15 13:41:56.108000"
}很长,可以给它看成一个大字典,channels字典里存放着图像,annotations里面存放着标签信息,它们都有自己的url,学过爬虫的可以直接解析这个url进行爬虫下载。或者用wget语句分别下载。
举个例子:
第60个序列对应下载的url为
60 : http://data.votchallenge.net/sequences/77028a6105041ca4a6af0c7c24e235172911d5f0d2d50395d2670544f94935de38d7018711595fd47f0e508012981e9fe980d3dec6fda66089e3d6cb59741f65.zip
60 : http://data.votchallenge.net/vot2019/main/zebrafish1.zip上面一行为图像,下面一行为标签,我写的那个cmd文件应该可以直接操作的。