LeNet-5 研习 1
LeNet-5的三维可视化
http://scs.ryerson.ca/~aharley/vis/conv/flat.html

http://scs.ryerson.ca/~aharley/vis/conv/

一、LeNet-5的介绍
LeNet-5是一个较简单的卷积神经网络。下图显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。

原始的LeNet-5除了输入层,有7个,现在一般网络上的是如下结构,最后的F6和Gaussian connections取消了,变成了C5全连接后,直接输出层(全连接+softmax激活)

二、卷积神经网络(Convolutional Neural Network, CNN)
1卷积层
卷积层是卷积神经网络的核心基石。在图像识别里我们提到的卷积是二维卷积,即离散二维滤波器(也称作卷积核)与二维图像做卷积操作,简单的讲是二维滤波器滑动到二维图像上所有位置,并在每个位置上与该像素点及其领域像素点做内积。卷积操作被广泛应用与图像处理领域,不同卷积核可以提取不同的特征,例如边沿、线性、角等特征。在深层卷积神经网络中,通过卷积操作可以提取出图像低级到复杂的特征

注意:上述 o(2,2,0)这个计算,一定看下,这个

这只是第一组卷积核计算出的,如上,还需要另一组卷积核再次同样计算
上图给出一个卷积计算过程的示例图,输入图像大小为H=5,W=5,D=3,即5×5大小的3通道(RGB,也称作深度)彩色图像。这个示例图中包含两(用K表示)组卷积核,即图中滤波器W0和W1。在卷积计算中,通常对不同的输入通道采用不同的卷积核,如图示例中每组卷积核包含3个(D=3) 3×3(用F×F表示)大小的卷积核。另外,这个示例中卷积核在图像的水平方向(W方向)和垂直方向(H方向)的滑动步长为2(用S表示);对输入图像周围各填充1(用P表示)个0,即图中输入层原始数据为蓝色部分,灰色部分是进行了大小为1的扩展,用0来进行扩展。经过卷积操作得到输出为3×3×2(用Ho×Wo×K表示)大小的特征图,即3×3大小的2通道特征图,其中Ho计算公式为:Ho=(H(orW)−F+2×P)/S+1,Ho=(5-3+2*1)/2+1,Wo同理。 而输出特征图中的每个像素,是每组滤波器与输入图像每个特征图的内积再求和,再加上偏置bo,偏置通常对于每个输出特征图是共享的。输出特征图o[:,:,0]中的最后一个−2计算如上图右下角公式所示。
记住这几个符号:
- H:图片高度;
- W:图片宽度;
- D:原始图片通道数,也是卷积核个数;
- F:卷积核高宽大小;
- P:图像边扩充大小;
- S:滑动步长。
- 上述中还有一个概念就是卷积核的组数:K
在卷积操作中卷积核是可学习的参数,经过上面示例介绍,每层卷积的参数大小为D×F×F×K。卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
这里提醒一下,是卷积层的主要特性,卷积就是局部连接,他的输出神经元,比如上图中的 -2,就是它的一个输出神经元,该神经元,只和局部区域有关,

就是上图我所圈出来的区域,所以,它在空间维度是局部连接,但是深度,是全部连接
这里萌生一个想法,希望写一个三层BP的博文,对比下,特别清晰理解,因为三层bp全连接,每个神经元要与图片的28*28个输入+1个偏置项全连接
- 局部连接:每个神经元仅与输入神经元的一块区域连接,这块局部区域称作感受野(receptive field)。在图像卷积操作中,即神经元在空间维度(spatial dimension,即上图示例H和W所在的平面)是局部连接,但在深度(该局部连接的深度)上是全部连接。对于二维图像本身而言,也是局部像素关联较强。这种局部连接保证了学习后的过滤器(滤波器,或者卷积操作)能够对于局部的输入特征有最强的响应。局部连接的思想,也是受启发于生物学里面的视觉系统结构,视觉皮层的神经元就是局部接受信息的。
这里可以用一个图来解释:

从图中可见,也可从现实生活中感受,我们人看一个东西,会集中看一个区域,看的时候,没法在意其他区域的细节
还有,通过滤波即卷积操作,我们能够提取边缘特征,角点,提取等


- 权重共享:计算同一个深度切片的神经元时采用的滤波器是共享的。例上图中计算o[:,:,0]的每个每个神经元的滤波器均相同,都为W0,这样可以很大程度上减少参数。共享权重在一定程度上讲是有意义的,例如图片的底层边缘特征与特征在图中的具体位置无关。但是在一些场景中是无意的,比如输入的图片是人脸,眼睛和头发位于不同的位置,希望在不同的位置学到不同的特征 。请注意权重只是对于同一深度切片的神经元是共享的,在卷积层,通常采用多组卷积核提取不同特征,即对应不同深度切片的特征,不同深度切片的神经元权重是不共享。另外,偏重对同一深度切片的所有神经元都是共享的。
这里的权重共享,是指同一深度卷积核共享,所以卷积核的权重共享,如图:

然后不同深度切片的神经元权重是不共享,如左图,为了让同一深度切片在保持权重共享特性下,增加卷积核的组数,用于保证提取到不同的特征(采用多组卷积核提取不同特征,即对应不同深度切片的特征),通过这样,增加了同一深度特征的多样性(属于自己理解,不一定对)
 ----------------以及----------------------------
----------------以及----------------------------
红色加粗字,我的理解是,同一个卷积核,依然可以把灰度图中,很多边缘信息提取出来,
紫色加粗字,我的理解是,如同人脸识别的时候LBP与Haar,他们提取眼睛和嘴,用的是不同的特征模板
如下如:

通过介绍卷积计算过程及其特性,可以看出卷积是线性操作(核是加减乘除的算术运算,不是逻辑运算),并具有平移不变性(shift-invariant),平移不变性即在图像每个位置执行相同的操作。卷积层的局部连接和权重共享使得需要学习的参数大大减小,这样也有利于训练较大卷积神经网络。------优于BP的全连接

整体计算过程如下(与上图中的数据不同,但是计算过程相同):

2池化层

池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如上图所示。
池化,我的理解类似降采样,我们以前用的都是线性差值法,这里使用非线性,是提供更多的可能性,下图虽然讲非线性激活函数,但是道理相同,降采样可能是为了像SIFT算法一样,模拟人体视觉,图像金字塔,最后让训练出的网络,具有尺度不变性


三、Lenet-5解析
LeNet5 这个网络虽然很小,但是它包含了深度学习的基本模块:卷积层,池化层,全链接层。是其他深度学习模型的基础, 这里我们对LeNet5进行深入分析。同时,通过实例分析,加深对与卷积层和池化层的理解。

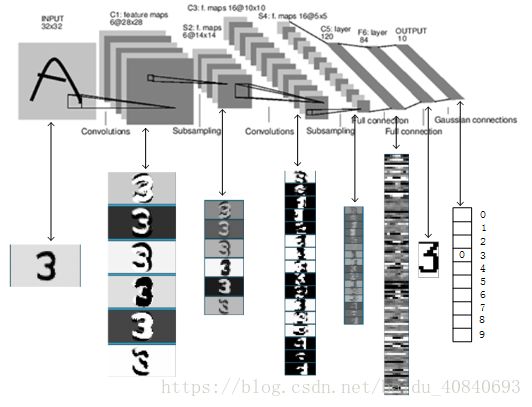
LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
这里和上面卷积层的卷积核提取不同的是,LeNet5的输入是28*28的二值图,不需要三通道RGB(不同深度),为了保持我们前面说的特征多样性,这里它用不同组的卷积核去提取特征,每个层有多组卷积核,就有多个Feature Map
各层参数详解:
提前说一下,S2到C3,最难,慢慢看
1、INPUT层-输入层
首先是数据 INPUT 层,输入图像的尺寸统一归一化为32*32。mnist的数据集都是28*28,这里这么处理可能后续有原因,如果没有,可能我多虑了
答案:
LeNet-5给输入图像增加了一圈黑边,使输入图像大小变成了32x32,这样的目的是为了在下层卷积过程中保留更多原图的信息。
注意:本层不算LeNet-5的网络结构,传统上,不将输入层视为网络层次结构之一。
2、C1层-卷积层
输入图片:32*32
卷积核大小:5*5
卷积核种类:6
相当于6组,每组一个模板
输出featuremap大小:28*28 (32-5+1)
前面的公式是Ho×Wo= 像素数
Ho=Wo=(H−F+2×P)/S+1=(高−卷积核的边长+2×图像边扩充大小)/滑动步长+1
=(32−5+2×0)/1+1=28 由此我们知道LeNet-5的C1,没有扩充,且滑动步长为1,padding=0,stride=1
神经元数量:28*28*6
可训练参数:(5*5+1) * 6(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器)
参数个数:(5*5+1)*6=156
连接数: 156*28*28=122304
由此我们知道,该网络是6组卷积核,+1 是因为每组卷积核的bias偏置项不同
如前面图中的
连接数:(5*5+1)*6*28*28=122304
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 5*5 的卷积核),得到6个C1特征图(6个大小为28*28的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为5*5,总共就有6*(5*5+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的5*5个像素和1个bias有连接,所以总共有156*28*28=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。

对比:
上文中所说的局部连接在这里体现就是(5*5+1)
如果是BP神经网络,那这里不仅没有提取到特征,而且是全连接,假设隐藏层为28*28个,连接数目为:
32*32*28*28=1024*28*28,现在大家能理解为什么叫局部连接了吧,从数目上,就和全连接不是一个等级

3、S2层-池化层(下采样层)
输入:28*28
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid(这里不太理解,后续看怎么解释)
采样种类:6
输出featureMap大小:14*14(28/2)
神经元数量:14*14*6
连接数:(2*2+1)*6*14*14
参数个数:(1+1)*6=12
连接数: (2*2+1)*14*14*6= 5880
S2中每个特征图的大小是C1中特征图大小的1/4。
详细说明:第一次卷积之后紧接着就是池化运算,使用 2*2核 进行池化,于是得到了S2,6个14*14的 特征图(28/2=14)。S2这个pooling层是对C1中的2*2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。同时有5x14x14x6=5880个连接。
使用2×2大小的卷积核进行池化,得到6个14×14大小的特征图(28−2+2×0)/2+1=14
前面的公式是Ho×Wo=像素数
Ho=Wo=(H−F+2×P)/S+1=(高−卷积核的边长+2×图像边扩充大小)/滑动步长+1
=(28−2+2×0)/2+1=28 由此我们知道LeNet-5的S2,没有扩充,且滑动步长为2,padding=0,stride=2
(前面我们说了,其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,所以肯定是步长为2,为了不重叠)
可训练参数个数:(1+1)×6=12,其中第一个1为池化所对应的2*2感受野中所乘的权重,第二个1为偏置
这里由参数个数可知,一种采样,池化的Wo和Bo,是同一个数


这里(A+B+C+D)的操作,相当于卷积运算,卷积核为2*2的,核中数值全为1
上文中说最后用到了sigmod,sigmod函数和它的导数特性


函数曲线

最后Output的像素值是0或者1
这里和我们前面讲的最大池化不同,是因为使用的手写图像,全是二值图,只有0和1
有些博客有不同声音:我的感觉是因为他们写的全是CNN的池化还是应该按如上方式
4、C3层-卷积层
输入:S2中所有6个或者几个特征map组合
卷积核大小:5*5
卷积核种类:16
相当于16组,每组模板数不同,有的是 3 4 4 6
输出featureMap大小:10*10 (14-5+1)=10
前面的公式是Ho×Wo=像素数
Ho=Wo=(H−F+2×P)/S+1=(高−卷积核的边长+2×图像边扩充大小)/滑动步长+1
=(14−5+2×0)/1+1=10 由此我们知道LeNet-5的C3,没有扩充,且滑动步长为1,padding=0,stride=1
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合
存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。
则:可训练参数:6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516
连接数:10*10*1516=151600
参数个数:(5*5*3+1)*6+(5*5*3+1)*6+(5*5*4+1)*3+(5*5*6+1)=1516
连接数:1516*10*10=151600
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 5*5. 我们知道S2 有6个 14*14 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。具体如下:
C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入
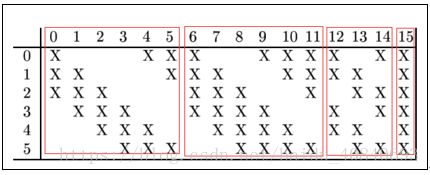

这里X表示选择卷积,比如第0张输出图像是由第0、1、2张输入图像分别同第0个卷积模板卷积相加,再加上偏重,经过激活函数得到的。而第15张图像是由第0、1、2、3、4、5张输入图像分别同第15个卷积模板卷积相加得到的。
如上,还是16组卷积核,不过方式核C1不同
C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。

卷积核大小依然为5*5,所以总共有6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516个参数。
这里的3*5*5中的3类似前面讲卷积层的深度概念,因为深度为3,一组卷积核中,有三个卷积模板
而图像大小为10*10,所以共有151600个连接。
C3与S2中前3个图相连的卷积结构如下图所示:


上图对应的参数为 3*5*5+1,一共进行6次卷积得到6个特征图,所以有6*(3*5*5+1)参数。
为什么采用上述这样的组合了?论文中说有两个原因:1)减少参数,2)这种不对称的组合连接的方式有利于提取多种组合特征。
5、S4层-池化层(下采样层)
输入:10*10
采样区域:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:16
输出featureMap大小:5*5(10/2)
前面的公式是Ho×Wo=像素数
Ho=Wo=(H−F+2×P)/S+1=(高−卷积核的边长+2×图像边扩充大小)/滑动步长+1
=(10−2+2×0)/2+1=5 由此我们知道LeNet-5的S4,没有扩充,且滑动步长为2,padding=0,stride=2
神经元数量:5*5*16=400
连接数:16*(2*2+1)*5*5=2000
S4中每个特征图的大小是C3中特征图大小的1/4
可训练参数个数:(1+1)×16=32,其中第一个1为池化所对应的2*2感受野中所乘的权重,第二个1为偏置
参数个数:(1+1)*16=32
连接数: (2*2+1)*16*5*5=2000
详细说明:S4是pooling层,窗口大小仍然是2*2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。有5x5x5x16=2000个连接。连接的方式与S2层类似。
6、C5层-卷积层
输入:S4层的全部16个单元特征map(与s4全相连)
卷积核大小:5*5
卷积核种类:120
相当于120组,每组16个模板
输出featureMap大小:1*1(5-5+1)
前面的公式是Ho×Wo=像素数
Ho=Wo=(H−F+2×P)/S+1=(高−卷积核的边长+2×图像边扩充大小)/滑动步长+1
=(5−5+2×0)/1+1=1 由此我们知道LeNet-5的C5,没有扩充,且滑动步长为1,padding=0,stride=1
可训练参数/连接:120*(16*5*5+1)=48120
参数个数:120*(16*5*5+1) = 48120
连接数: (5*5*16+1)*120*1*1=48120
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下:
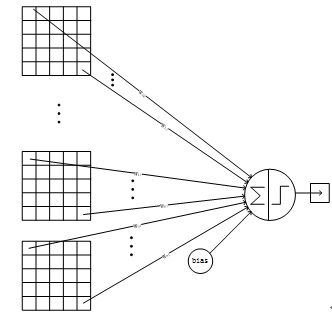
C5这里的计算跟C3相同,也是多通道(深度)卷积,因此5*5后面乘以16.
7、F6层-全连接层
输入:c5 120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出。
可训练参数:84*(120+1)=10164
详细说明:6层是全连接层。F6层有84个节点,对应于一个7x12=84的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。ASCII编码图如下:

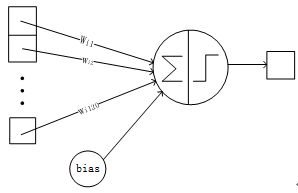
F6层的连接方式如下:
8、Output层-全连接层
Output层也是全连接层,共有10个节点,分别代表数字0到9,且如果节点i的值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式。假设x是上一层的输入,y是RBF的输出,则RBF输出的计算方式是:


上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。该层有84x10=840个参数和连接。
最后
LeNet-5识别数字3的过程:
附上网上的PPT截图:


