UC Berkeley提出变分判别器瓶颈,有效提高对抗学习平衡性


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
这是 PaperDaily 的第 116 篇文章作者丨武广
学校丨合肥工业大学硕士生
研究方向丨图像生成
本期推荐的论文笔记来自 PaperWeekly 社区用户 @TwistedW ,作者今天要解读的是 UC Berkeley 投稿 ICLR 2019 的工作。
对抗学习中判别器一直保持着强大的侵略优势,造成了对抗中的不平衡。本文采用变分判别器瓶颈(Variational Discriminator Bottleneck,VDB),通过对数据样本和编码到的特征空间的互信息进行限制,提高判别器的判别难度,进而提高了对抗学习中的平衡性。实验表明 VDB 思想可以在 GAN、模仿学习和逆强化学习上取得不小的进步。


引言
生成对抗网络中判别器在二分类游戏上表现了强大的区分能力,RSGAN 使用相对判别器将真假样本混合利用“图灵测试”的思想削弱了判别器的能力,T-GANs 将 RSGAN 一般化到其它 GAN 模型下,判别器得到限制在整体上平衡了生成器和判别器,可以使 GAN 训练上更加稳定。VDB 则通过对判别器加上互信息瓶颈来限制判别器的能力。
论文引入
GAN 存在两大固有问题,一个是生成上多样性不足;另一个就是当判别器训练到最优时,生成器的梯度消失。造成梯度消失的原因在于生成样本和真实样本在分布上是不交叠的,WGAN [1] 提出可以通过加入噪声来强制产生交叠,但是如何控制噪声加入以及能否保证交叠都是存在问题的。WGAN 以及它的改进虽然在 GAN 训练中稳定性上提高了,但是对于样本真假的二分类判别上,判别器展现了过于强大的能力,这样打破了对抗上的平衡问题,最终还是造成训练阶段的不稳定(不平衡,生成质量提不上去)。
RSGAN 提出了采用相对判别器通过区分真假样本混合在一起判断真假,这样判别器不再是判断真或假,还要在一堆样本下将真假样本分开。这样对于判别器的要求提高了,难度上来后自然会进一步平衡训练,
关于 RSGAN 的进一步理解可参看RSGAN:对抗模型中的“图灵测试”思想。T-GANs 更是进一步将 RSGAN 一般化,让RSGAN中的混合真假样本的思想得到充分应用,具体了解,可参看T-GANs:基于“图灵测试”的生成对抗模型。
我们今天要解读的文章是变分判别器瓶颈(Variational Discriminator Bottleneck,VBD)。论文通过对互信息加上限制来削弱判别器的能力,从而平衡网络的训练。这种对判别器互信息限制,不仅可以用在 GAN 的训练上,对于模仿学习和逆强化学习都有很大的提高。由于我更加关注 VDB 在 GAN 上的应用,所以在模仿学习和强化学习方面将只做简短介绍,把重点放在 VDB 在 GAN 上的作用。
在开启正文前,我们一起看一下互信息瓶颈限制在监督学习上的正则作用。这个思想在 16 年被 Alemi 提出,原文叫 Deep Variational Information Bottleneck [2]。我们有数据集 {xi,yi},其中 xi 为数据样本,yi 为对应的标签,通过最大似然估计优化模型:
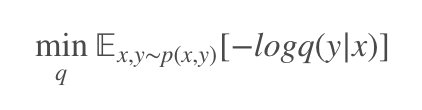
这种最大似然估计方法往往会造成过拟合的现象,这时候就需要一定的正则化。变分互信息瓶颈则是鼓励模型仅关注最具辨别力的特征,从而对模型做一定的限制。
为了实现这种信息瓶颈,需要引入编码器对样本特征先做提取 E(z|x) 将样本编码到特征空间 z,通过对样本 x 和特征空间 z 的互信息 I(X,Z) 做限制,即 I(X,Z)≤Ic,则正则化目标:
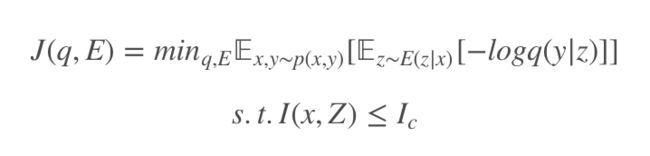
此时最大似然估计就是对模型 q(y|z) 操作的,实现将特征空间 z 到标签 y,互信息定义为:
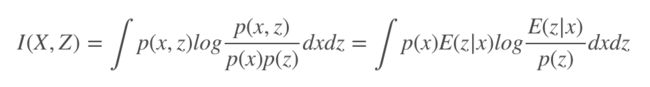
这里的 p(x) 为数据样本的分布,p(x,z)=p(x)E(z|x),计算分布 p(z)=∫p(x)E(z|x)dx是困难的,p(z) 是数据编码得到的,这个分布是很难刻画的,但是使用边际的近似 r(z) 可以获得变分下界。
取 KL[p(z)‖r(z)]=∫p(z)logp(z)−∫p(z)logr(z)≥0,此时 ∫p(z)logp(z)≥∫p(z)logr(z),I(X,Z) 可以表示为:
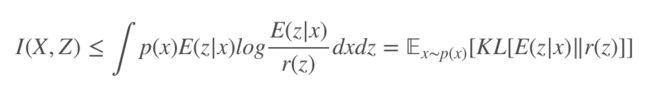
这提供了正则化的上界,J̃(q,E)≥J(q,E)。
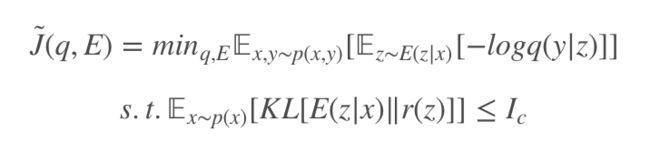
优化的时候可以采取拉格朗日系数 β。我们从整体上分析一下这个互信息的瓶颈限制,互信息反应的是两个变量的相关程度,而我们得到的特征空间 z 是由 x 编码得到的,理论上已知 x 就可确定 z,x 和 z 是完全相关的,也就是 x 和 z 的互信息是较大的。
而现在限制了互信息的值,这样就切断了一部分 x 和 z 的相关性,保留的相关性是 x 和 z 最具辨别力的特征,而其它相关性较低的特征部分将被限制掉,从而使得模型不至于过度学习,从而实现正则化的思想。
VDB 正是把这个用在监督学习的正则思想用到了判别器上,从而在 GAN、模仿学习和逆强化学习上都取得了不小的提升。
总结一下 VDB 的优势:
判别器信息瓶颈是对抗性学习的自适应随机正则化方法,可显著提高各种不同应用领域的性能;
在 GAN、模仿学习和逆强化学习上取得性能上的改进。
VDB在GAN中的实现
VDB其实是在 Deep Variational Information Bottleneck [2] 的基础上将互信息思想引入到判别器下,如果上面描述的互信息瓶颈读懂的话,这一块将很好理解。
对于传统 GAN,我们先定义下各个变量(保持和原文一致)。真实数据样本分布 p∗(x),生成样本分布 G(x),判别器为 D,生成器为 G,目标函数为:
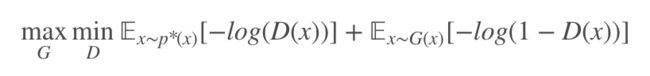
类似于 Deep Variational Information Bottleneck [2],文章也是先对数据样本做了 Encoder,经数据编码到特征空间下,这样一来降低了数据的维度,同时将真假样本都做低维映射,更加可能实现一定的交叠。
当然这个不是文章的重点,文章的重点还是为了在互信息上实行瓶颈限制。将数据编码得到的 z 和数据 x 的互信息做瓶颈限制,我们先看目标函数,再来解释为什么做了瓶颈限制可以降低判别器的能力。
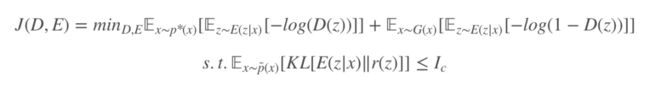
这里强调一下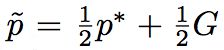 ,这个我们待会再进一步分析,同样可以通过引入拉格朗日系数优化目标函数:
,这个我们待会再进一步分析,同样可以通过引入拉格朗日系数优化目标函数:
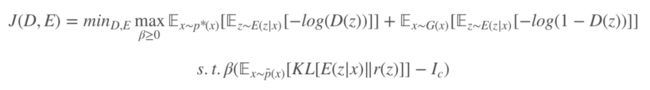
我们分析一下限制互信息瓶颈在 GAN 中起到的作用,同样的互信息是样本 x 和它经过编码得到的特征空间 z。互信息表示变量间的相关程度,通过限制 x 和 z 的相关性,对于很具有辨识性的特征,判别器将可以区分真假,但是经过信息瓶颈限制把样本和特征空间相关性不足的特征限制住,这样判别器就增加了区分样本真假的难度。
判别器在这个二分类游戏下只能通过相关性很强的特征来判断真假,对于限制条件下,这个的作用是对整体样本的互信息都进行限制,这样真假样本都进行了混淆,判别器判断难度提高,游戏得到进一步平衡。
文章通过实验进一步说明了判别器加入信息瓶颈的作用,通过对两个不同的高斯分布进行区别,左侧认为是假(判为 0),右侧认为是真(判为 1),经过信息瓶颈限制 Ic 的调整,得到的结果如下图:

我们知道,在二分类下信息熵最小是 1bit(当两个事件等概率发生时),由于 x 和 z 是完全相关,我们可以理解理想状态此时的互信息最小是 1bit,当不断减小瓶颈 Ic 的值,上图中由 10 降到 0.1,这个过程中判别器区分两个分布的界限越来越弱,达到了限制判别器能力的效果。
对于网络的优化,主要是对 β 的更新上:
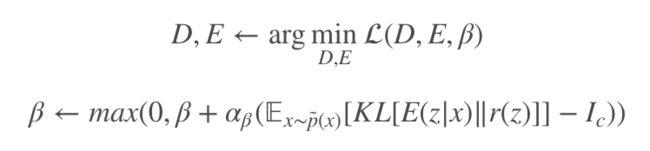
这个互信息瓶颈还可以用在模范学习和逆强化学习上,都取得了一定的改进,感兴趣的可以查看原文进一步了解。
实验
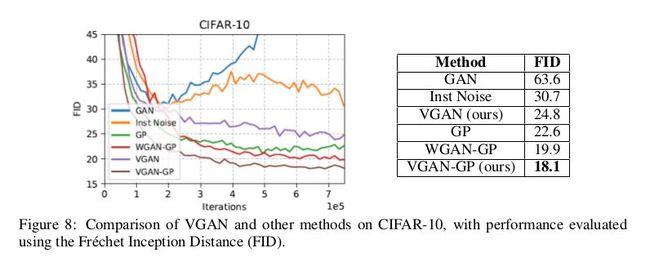
VDB 在 GAN 中的应用实验,作者对 CIFAR10 做了各个模型的 FID 定量对比。为了改善 VDB 在 GAN 上的性能,作者在 VDB 和 GAN 中加入了梯度惩罚,命名为 VGAN-GP。
这样可谓是又进一步限制了判别器,反正实验效果是有所提升,可以猜测作者用到的 GAN 的损失函数肯定基于 WGAN,文中说了代码即将公布,在没看到源码前只能猜测一下。
不过,通过后文实验做到了 1024 × 1024 可以看出,作者所在的实验室一定不简单,跑得动 1024 的图,只能表示一下敬意。

最后,来看一下作者展示的视频 Demo。
总结
在本文中,作者提出了变判别器瓶颈,这是一种用于对抗学习的一般正则化技术。实验表明,VDB 广泛适用于各种领域,并且在许多具有挑战性的任务方面比以前的技术产生了显着的改进。
通过对判别器加入信息瓶颈,限制了判别器的能力,使得对抗中保持平衡,提高了训练的稳定性。这种正则化思想可以在各类 GAN 模型下适用,后续还要对 VDB 做进一步实验上的分析。
参考文献
[1] Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In International Conference on Machine Learning, pages 214–223, 2017.
[2] Alexander A. Alemi, Ian Fischer, Joshua V. Dillon, and Kevin Murphy. Deep variational information bottleneck. CoRR, abs/1612.00410, 2016.
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!
![]()
点击标题查看更多论文解读:
T-GANs:基于“图灵测试”的生成对抗模型
网络表示学习综述:一文理解Network Embedding
神经网络架构搜索(NAS)综述
从傅里叶分析角度解读深度学习的泛化能力
深度解读DeepMind新作:史上最强GAN图像生成器
ACL2018高分论文:混合高斯隐向量文法
自然语言处理中的语言模型预训练方法
自动机器学习(AutoML)最新综述
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 下载论文