CapsNet日益火爆!Hinton大神横扫AI界的「胶囊网络」如何理解?

来源:雷克世界
编译:嗯~阿童木呀
概要:Geoff Hinton等人最近关于胶囊网络(Capsule networks)的论文在机器学习领域造成相当震撼的影响。

Geoff Hinton等人最近关于胶囊网络(Capsule networks)的论文在机器学习领域造成相当震撼的影响。它提出了理论上能更好地替代卷积神经网络的方案,是当前计算机视觉领域的最新技术。
首先,我想谈谈神经网络那些令人困惑的术语。机器学习中的许多想法来源于符号数字化的认知概念。为了演示,我们以神经元为例。在物质世界中,这是一组细胞,以信号作为输入,并发出一些信号作为输出,只要它足够兴奋。虽然这是一个简单直白的解释,但这最终是对“神经网络”机器学习概念的充分体现。在这里,神经元是一个数学单位,它接受一个输入,并使用一系列函数给出输入的输出。我们学习权重来确定在训练阶段哪个特定的输入可能比使用反向传播的输入更重要。我们可以堆叠这些神经元,使得一层神经元的输出成为另一层神经元的输入。所有类型的神经元都取自从这个基本概念,包括递归神经网络和卷积神经网络。
现在让我们来描述胶囊的概念。像基本的神经元一样,它们也代表了一个认知思想的符号数字化。大脑的高层做了更多的演绎、理解和高层次特征的计算,大脑的特定部分在他们处理的领域或主题上有明确的含义。我们并不是将所有维度的数据都放在整个大脑中,而是“喂食(feed in)”较低级别的特征,以供大脑的高层部分处理,从而将认知负荷从较高级别的处理中移除。如果较低级别的功能与大脑某些较高级别的部分不相关,则不应将其发送到那里。它的信号至少应该有所减弱。
这些胶囊被设想为用以处理识别姿势的问题。就是说,当一个模型原先是被训练来对一只狗进行识别时,但却变得依赖于视野内该狗所在的方向。如果将这只狗转个方向,并试图从不同的角度对其拍照,那么该模型在对狗进行识别时可能会遇到麻烦。为了解决这一问题,胶囊试图通过让“符号数学大脑(symbolic mathematical brain)”(即网络)的更高级别部分来处理复杂特征的识别和姿势认证,而较低级别部分用来处理“子”特征。一个较高级别的胶囊可以识别出一张脸部特征,而这是基于较低级别的胶囊是以一个相一致的方向来对嘴巴和鼻子进行识别的。
卷积神经网络目前并不是这样做的,相反,他它们依靠的是大量的数据,其中将该目标可能拥有的所有姿势都包含在内,当然,它们也具有其他的缺点。
对于初学者来说,这是一个上下文的问题。信息有时需要在上下文中才能有效。Geoff Hinton自己遇到过这样一个示例:一个四面体被切成两半之后,即使是麻省理工学院的教授也很难将其恢复成原形。其实,很难确切地去弄明白这是为什么,但它似乎与我们的参考框架有关:我们选择查看目标的方式可以决定我们对其进行操作和识别的方式。而胶囊网络可以潜在地通过将该信息嵌入特定胶囊中来解决这个问题,而该特定胶囊对所涉及的上下文进行学习,然后将该信息馈送到网络的更高部分。
其次,卷积神经网络通过池化的方式将多个特征检测器合并在一起。前层神经网络作为特征馈入到后层中。人们认为,这些早期网络充当的是特征检测器,因为早期网络识别的是非常基本的特征,而后续网络可以识别耳朵、眼睛等器官特征。通过将它们池化在一起,可以解决方差问题,即就模型而言,图片中左手边的耳朵可能与右手边的耳朵不是一样的。
尽管如此,池化的结果也是非常不稳定的,它使得信息分布在许多个而不是少数几个神经元中。因此,每个神经元必须更努力地运行。如果我们能够对神经元进行特定化以便处理特定的识别,那结果将会好很多。我们可以有一个专门用来寻找鼻子的胶囊,一个专门用来寻找嘴巴的胶囊。这样的话,这些胶囊可以很好地对那些非常特殊的目标进行识别,因为就整个网络而言,它们没有别的事情要做。
与之相关的是Geoff Hinton教授的理想目标,即拥有一个目标可以转化到其中的更高的空间域。每次,不管方向如何,在这个更高的域空间内目标都被转换成了相同的刚性形状。达到该目标的一种方法是使用特定的胶囊以帮助将目标转化到更高的域空间中。
为了建立一个胶囊网络,我们可以从1980年代的发明——霍夫变换(Hough Transforms)中获得灵感。其应用的基本思想是有一个两部分的结构,我将其称之为斑点(speck)。一般的speck预测坐标系为X的概率,另一半预测姿势。然后将这些child_speck_s馈送到父speck中。如果获得这些child_speck_s的足够多的同意后,那么父speck就会给出坐标系为Y的概率,这是一个比X更复杂的目标。例如,child_speck_s可以预测嘴巴、鼻子和眼睛及其所处的方向,然后将其馈送到能够预测到脸部及其姿势的父speck中。
现在,让我们用胶囊代替那些神经元。较低级别的胶囊通过识别该目标的较简单的子部分来做一个该目标可能是什么的“弱赌注”,然后一个更高级别的胶囊会采取这些低级别的赌注,并试图看看它们是否同意。如果它们中有足够多的同意,那么这个目标就是Y,这可能是非常巧合。而这就是这些胶囊网络运行方式的本质。
而问题在于:我们该如何路由这些较低级别的胶囊,以便将它们送到正确的、更高级别胶囊中?
这就是前些天Hinton等人又推出的创新性研究。(该论文于10月26日上传,11月7日又做了更新)
那么这个路由算法的运行原理是什么呢?为了搞明白这一点,我们需要定义一些关键的想法。为了简化,我们将假设一个两层的胶囊网络。将原始特征馈送到层LA中,并将来自层LA的输出馈送到层LB中,其中两个层都是由胶囊组成的。
首先,我们对来自层LA并会输入到层LB的称之为u的输出矩阵进行加权,然后这些权重将被存储为一个向量W,将这两者相乘将得到u'。
然后,路由算法决定一个称为耦合系数c的附加参数,这个系数将减少发送到不正确的胶囊的信息,这可以通过适当减少它们的权重实现。我们还通过使用特定函数来“压缩(squash)”整个输入,这将确保低幅值向量被压缩到几乎为零,而高幅值向量将得到一个只略小于1的长度。这是因为本文中的动态路由算法使用向量的幅度来表示目标在正确输入中出现的概率。因此,这些输入向量不必太过于专注幅度。
我将在这里简单描述路由算法。你可以在论文中看到更为具体的确切形式。需要记住的是,他们提到这个只是一种可以实现路由算法的方法,所以随着时间的推移,可能会有更多的猜测出现。
作为背景,b用来表示对数先验概率,并且耦合因子c被确定为b的softmax函数。
对于层LA和层LB层中的每个胶囊,我们将先验b设置为0。然后,对于r迭代,我们遍历每个胶囊并将耦合因子c设置为b的softmax函数。我们通过将c与u'相乘来计算s。产生的结果值将被称为s。进入层LB的每一个输入都用适当的函数进行“压缩”以得到v。然后对每个胶囊,我们通过将u和v的值加到b中以对其进行调整。
下面是一个更为精确、学术更为友好的算法显示:
# Dynamic Routing Algorithm
for all capsules _i_ in layer A and capsules _j_ in layer B, set _b_
to 0
for _r_ iterations:
for all capsules i in layer A: _c_ is the softmax of _b_
for all capsules j in layer B: _s_ is the multiplication of _c_ &
_u_
for all capsules j in layer B: _v_ is the squashed input of _s_
fir all capsules i in layer A and capsules j in layer B: _b_ is
set to _b_ + _u'_ * _v_
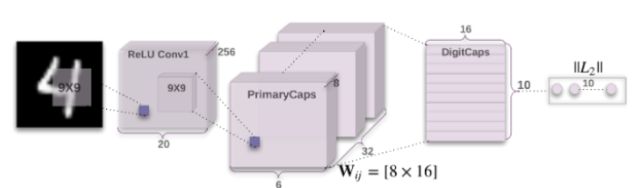
这篇论文包含的内容还有很多,我可能会在接下来的文章中阐述更多,主要是有关在MNIST数据集上的性能以及使用称为CapsNet的卷积神经网络进行的特定实现。
使用Keras实现CapsNet:https://github.com/XifengGuo/CapsNet-Keras