Caffe学习1-图像识别与数据可视化
本文采用深度学习库caffe做图像的识别与分类,所用模型为caffemodel。
具体参考caffe官网:http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/00-classification.ipynb
#用caffe来进行图像的识别和各层可视化
# 加载各个模块,比如python,numpy和matploblib
import numpy as np
import matplotlib.pyplot as plt
# 在notebook里面显示图像
%matplotlib inline
# set display defaults
plt.rcParams['figure.figsize'] = (10, 10) # 显示图像的最大范围
plt.rcParams['image.interpolation'] = 'nearest' # 差值方式
plt.rcParams['image.cmap'] = 'gray' # 灰度空间
#第二步,用来加载caffe
import sys
caffe_root='../../' #我的路径是在caffe/example/test路径下,根据你的情况将caffe_root路径进行定义
sys.path.insert(0,caffe_root+'python')
import caffe#如果没有事先下载了已经训练好了的caffemodel,这里需要判别一下,如果没有模型则提示需要下载
import os
if os.path.isfile(caffe_root+'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'):
print 'CaffeNet found.'
else:
print 'Downloading pre-trained CaffeNet model...'
!../scripts/download_model_binary.py ../models/bvlc_reference_caffenetCaffeNet found
#第三步,设置用CPU来加载Caffe并且加载网络
caffe.set_mode_cpu()
model_def=caffe_root + 'models/bvlc_reference_caffenet/deploy.prototxt' #网络结构定义文件
model_weights=caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel' #加载了caffe的预训练模型
#定义网络
net = caffe.Net(model_def,model_weights,caffe.TEST) #用caffe的测试模式,即只是提取特征,不训练
#定义转换也即是预处理函数
#caffe中用的图像是BGR空间,但是matplotlib用的是RGB空间;再比如caffe的数值空间是[0,255]但是matplotlib的空间是[0,1]。这些都需要转换过来
#载入imagenet的均值,实际图像要减去这个均值,从而减少噪声的影响
mu = np.load(caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy')
mu = mu.mean(1).mean(1) #计算像素的平均值
print 'mean-subtracted values:', zip('BGR', mu) #打印B、G、R的平均像素值
# 定义转换输入的data数值的函数
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1)) # 分离图像的RGB三通道
transformer.set_mean('data', mu) # 减去平均像素值
transformer.set_raw_scale('data', 255) # 将0-1空间变成0-255空间
transformer.set_channel_swap('data', (2,1,0)) # 交换RGB空间到BGR空间
mean-subtracted values: [(‘B’, 104.0069879317889), (‘G’, 116.66876761696767), (‘R’, 122.6789143406786)]
#第四步,用CPU来进行图像的分类
#首先,可以resize图像的大小
net.blobs['data'].reshape(50,3,227,227) #batchsize=50,三通道,图像大小是227*227
#第五步,加载图像
image = caffe.io.load_image(caffe_root + 'examples/00-classification-test/dog.jpg')
traformed_image = transformer.preprocess('data',image)
plt.imshow(image)
#将图像数据拷贝到内存中并分配给网络net
net.blobs['data'].data[...] = traformed_image
#分类,这里用的是caffemodel,这是在imagenet上的预训练模型,有1000类
output = net.forward()
output_prob = output['prob'][0] #这里是输出softmax回归向量
print 'predicted class is:', output_prob.argmax() #找出这个向量里面值最大的那个标号predicted class is: 253
#第五步,加载imagenet里面1000类的标签
labels_file=caffe_root + 'data/ilsvrc12/synset_words.txt'
if not os.path.exists(labels_file):
!../data/ilsvrc12/get_ilsvrc_aux.sh
labels = np.loadtxt(labels_file,str,delimiter='\t')
print 'output label:', labels[output_prob.argmax()] #输出是一个八仙吉犬,牛逼!output label: n02110806 basenji
#输出概率较大的前五个物体
top_inds = output_prob.argsort()[::-1][:5]
print 'probailities and labels:'
zip(output_prob[top_inds],labels[top_inds]) #根据概率,输出排名前五个probailities and labels:
[(0.81211644, ‘n02110806 basenji’),
(0.098898478, ‘n02087046 toy terrier’),
(0.030348787, ‘n02113023 Pembroke, Pembroke Welsh corgi’),
(0.022625968, ‘n02091032 Italian greyhound’),
(0.015911266, ‘n02113186 Cardigan, Cardigan Welsh corgi’)]
#采用cpu查看一次正向传播时间
%timeit net.forward()1 loop, best of 3: 521 ms per loop
#采用gpu查看一次正向的时间
caffe.set_device(0) # 假如有多块gpu,选择第一块gpu
caffe.set_mode_gpu()
net.forward()
%timeit net.forward()10 loops, best of 3: 61.6 ms per loop
#显示各个层的参数和输出类型,输出分别是(batchsize,通道数或者feature map数目,输出image高,输出image宽)
for layer_name,blob in net.blobs.iteritems():
print layer_name +'\t' + str(blob.data.shape)data (50, 3, 227, 227)
conv1 (50, 96, 55, 55)
pool1 (50, 96, 27, 27)
norm1 (50, 96, 27, 27)
conv2 (50, 256, 27, 27)
pool2 (50, 256, 13, 13)
norm2 (50, 256, 13, 13)
conv3 (50, 384, 13, 13)
conv4 (50, 384, 13, 13)
conv5 (50, 256, 13, 13)
pool5 (50, 256, 6, 6)
fc6 (50, 4096)
fc7 (50, 4096)
fc8 (50, 1000)
prob (50, 1000)
#查看参数,存放参数的数据结构是输出的feature-map数量,输入的feature-map数量,卷积核大小
#这里conv3和conv4分开了,分别是192,则192*2=384
#后面只有一个参数的表示偏置b数量
for layer_name,param in net.params.iteritems():
print layer_name + '\t' + str(param[0].data.shape),str(param[1].data.shape)conv1 (96, 3, 11, 11) (96,)
conv2 (256, 48, 5, 5) (256,)
conv3 (384, 256, 3, 3) (384,)
conv4 (384, 192, 3, 3) (384,)
conv5 (256, 192, 3, 3) (256,)
fc6 (4096, 9216) (4096,)
fc7 (4096, 4096) (4096,)
fc8 (1000, 4096) (1000,)
#第六步,定义卷积核可视化函数
def vis_square(data):
"""
将数列(通道数,高度,宽度)可视化为(高度,宽度),即卷积核可视化。
"""
#标准化数据normalize
data = (data-data.min())/(data.max()-data.min())
#强制滤波器/卷积核数量为偶数
n = int(np.ceil(np.sqrt(data.shape[0])))
padding = (((0, n ** 2 - data.shape[0]),
(0, 1), (0, 1)) # add some space between filters
+ ((0, 0),) * (data.ndim - 3)) # don't pad the last dimension (if there is one)
data = np.pad(data, padding, mode='constant', constant_values=1) # pad with ones (white)
#给卷积核命名
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)))
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
plt.imshow(data);
# plt.axis('off') #关闭坐标轴
#查看各个层的参数(params)
filters = net.params['conv1'][0].data
vis_square(filters.transpose(0,2,3,1))
#可视化数据卷积层的效果图
feat = net.blobs['data'].data[0,:3]
vis_square(feat)
#显示/统计全连接层和prob层
feat = net.blobs['fc7'].data[0]
plt.subplot(2,1,1) #两行一列第一个
plt.plot(feat.flat)
plt.subplot(2,1,2) #两行一列第二个图像
a= plt.hist(feat.flat[feat.flat > 0], bins=100) #统计直方图
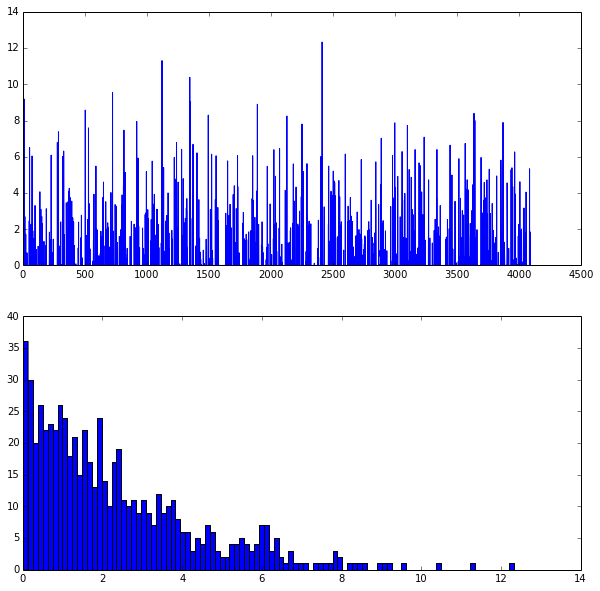
#第七步,统计属于哪一类的概率,记住imagenet有1000类
feat = net.blobs['prob'].data[0]
plt.figure(figsize=(15,3))
plt.plot(feat.flat)
#第八步,载入网上任意的图像,统计其特性
#输入图像的URL地址
my_image_url ="https://upload.wikimedia.org/wikipedia/commons/b/be/Orang_Utan%2C_Semenggok_Forest_Reserve%2C_Sarawak%2C_Borneo%2C_Malaysia.JPG"
!wget -O image.jpg $my_image_url
#转换数据
image = caffe.io.load_image("image.jpg")
net.blobs['data'].data[...] = transformer.preprocess('data',image)
net.forward()
out_prob = net.blobs['prob'].data[0]
top_inds = output_prob.argsort()[::-1][:5]
plt.imshow(image)
print 'probabilites and labels:'
zip(output_prob[top_inds],labels[top_inds])
–2016-05-04 20:57:11– https://upload.wikimedia.org/wikipedia/commons/b/be/Orang_Utan%2C_Semenggok_Forest_Reserve%2C_Sarawak%2C_Borneo%2C_Malaysia.JPG
正在解析主机 upload.wikimedia.org (upload.wikimedia.org)… 198.35.26.112, 2620:0:863:ed1a::2:b
正在连接 upload.wikimedia.org (upload.wikimedia.org)|198.35.26.112|:443… 已连接。
已发出 HTTP 请求,正在等待回应… 200 OK
长度: 1443340 (1.4M) [image/jpeg]
正在保存至: “image.jpg”
100%[======================================>] 1,443,340 25.8KB/s 用时 80s
2016-05-04 20:58:35 (17.6 KB/s) - 已保存 “image.jpg” [1443340/1443340])
probabilites and labels:
[(0.96807837, ‘n02480495 orangutan, orang, orangutang, Pongo pygmaeus’),
(0.030588904, ‘n02492660 howler monkey, howler’),
(0.00085891597, ‘n02493509 titi, titi monkey’),
(0.00015429019, ‘n02493793 spider monkey, Ateles geoffroyi’),
(7.2596624e-05, ‘n02488291 langur’)]
