TensorFlow-Slim图像分类库
TensorFlow-Slim图像分类库
TF-slim是用于定义,训练和评估复杂模型的TensorFlow(tensorflow.contrib.slim)的新型轻量级高级API。 该目录包含了几种广泛使用的卷积神经网络(CNN)图像分类模型的训练和测试代码。它包含脚本,允许您从头开始训练模型或从预训练(pre-train)的模型进行fine-tune。 它还包含用于下载标准图像数据集的代码,将其转换为TensorFlow的TFRecord格式,并可以使用TF-Slim的数据读取和队列程序进行读取。您可以轻松地使用这些数据集进行任意模型的训练,如下所示。 我们还包括一个 jupyter notebook,它提供了如何使用TF-Slim进行图像分类的工作示例。
安装
在本节中,我们将描述安装相应必备软件包所需的步骤。
安装最新版本的TF-slim
TF-Slim通过tf.contrib.slim的形式引入(TensorFlow 1.0)。 要测试安装是否正常,请执行以下命令:
python -c "import tensorflow.contrib.slim as slim; eval = slim.evaluation.evaluate_once"安装TF-slim图像模型库
使用TF-Slim做图片分类任务时,您同样需要安装TF-slim图像模型库,注意它并不是TF库的核心部分,所以请查看tensorflow/models,如下所示:
cd $HOME/workspace
git clone https://github.com/tensorflow/models/各个网络模型放在$HOME/workspace/models/research/slim下。(它还将创建一个名为models / inception的目录,其中包含一个较旧版本的slim,您完全可以忽略此目录。)
要验证这是否正常工作,请执行以下命令:
cd $HOME/workspace/models/research/slim
python -c "from nets import cifarnet; mynet = cifarnet.cifarnet"准备数据集
作为Slim库的一部分,我们提供了几个常用的图像数据库下载与转换。
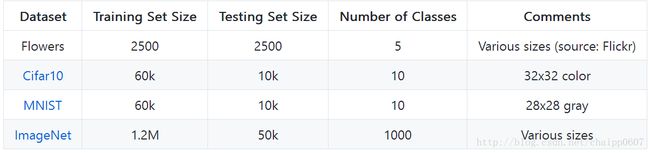
下载与转换到TFRecord格式
对于任意一个数据集,我们都需要下载原始数据和转化到TensorFlow的TFRecord格式。每个TFRecord包含TF示例协议缓冲区。 下面我们演示如何为Flowers数据集执行此操作。
$ DATA_DIR=/tmp/data/flowers
$ python download_and_convert_data.py \
--dataset_name=flowers \
--dataset_dir="${DATA_DIR}"当脚本运行完成之后,您会发现几个创建的TFRecord文件:
$ ls ${DATA_DIR}
flowers_train-00000-of-00005.tfrecord
...
flowers_train-00004-of-00005.tfrecord
flowers_validation-00000-of-00005.tfrecord
...
flowers_validation-00004-of-00005.tfrecord
labels.txt这些代表了训练和验证数据,每个分为5个文件。 您还将找到包含从整数标签到类名称的映射的$ DATA_DIR/labels.txt文件。
您可以使用相同的脚本创建mnist和cifar10数据集。 但是,对于ImageNet,您必须按照这里的说明进行操作。 请注意,您首先必须在image-net.org注册一个帐户。 此外,下载可能需要几个小时,最多可以使用500GB。
创建TF-Slim数据集描述
一旦TFRecord文件被成功创建,您可以很容易的定义一个Slim数据集(这个数据集的意思是读取TFRecord之后生成网络可用的数据),它存储指向数据文件的指针,以及各种其他数据,如图片的标签,训练/测试脚本和如何解析TFExample protos。我们提供了 Cifar10, ImageNet, Flowers和MNIST四种数据集的数据集描述符。下面是一个例子,如何使用TF-Slim数据集描述加载数据(使用DatasetDataProvider)
import tensorflow as tf
from datasets import flowers
slim = tf.contrib.slim
# Selects the 'validation' dataset.
dataset = flowers.get_split('validation', DATA_DIR)
# Creates a TF-Slim DataProvider which reads the dataset in the background
# during both training and testing.
provider = slim.dataset_data_provider.DatasetDataProvider(dataset)
[image, label] = provider.get(['image', 'label'])用于处理ImageNet数据的自动化脚本
一般情况下都需要在ImageNet数据集上训练模型。为了方便使用ImageNet数据集,我们提供了一个自动化脚本,用于将ImageNet数据集下载并处理为原始TFRecord格式。
TFRecord格式由一系列的共享文件组成,其中每一个文件都是序列化的tf.Example proto。 每个tf.Example proto包含ImageNet图像(JPEG编码)以及其他数据,如类别标签和边界信息等等。
我们为下载和转换ImageNet数据到TFRecord格式提供了单独的脚本。下载和准备数据可能需要几个小时的时间(最多半天),请避免您的网络或电脑进入睡眠。请耐心等待。
首先,您需要申请一下ImageNet账号(http://image-net.org)注册一个帐户才能访问数据。 查找注册页面,创建一个帐户并请求一个访问密钥来下载数据。
在您拥有USERNAME和PASSWORD之后,您就可以运行我们的脚本了。 确保您的硬盘至少有500 GB的可用空间用于下载和存储数据。 在这里,我们选择DATA_DIR = $ HOME / imagenet-data作为这样一个位置,但可以随时修改。
当您运行以下脚本时,请在出现提示时输入USERNAME和PASSWORD,输入需要早一开始时进行。 一旦输入这些值,您将不需要再次与脚本进行交互。
# location of where to place the ImageNet data
DATA_DIR=$HOME/imagenet-data
# build the preprocessing script.
bazel build slim/download_and_preprocess_imagenet
# run it
bazel-bin/slim/download_and_preprocess_imagenet "${DATA_DIR}"脚本输出的最后一行应为:
2016-02-17 14:30:17.287989: Finished writing all 1281167 images in data set.当脚本运行结束之后,将在上述路径下生成1024个训练文件和128个测试文件,这些文件将以train-????-of-1024和 validation-?????-of-00128这样的方式命名。
恭喜! 您现在可以使用ImageNet数据集进行训练或测试了。
预训练模型
当参数比较多时神经网络一般性能会更好,此时决策面会逼近的更完美。但是这样就意味着模型的训练将是一个需要大量计算的过程,需要几天甚至几周的时间,我们提供了各种网络的预训练模型,所辖所示,这些CNN网络已经在ImageNet数据集上训练过。
在下表中列出了每个模型,都有对应的TensorFlow模型文件,Checkpiont,以及top1和top5精度(在imagenet测试集上)。 请注意,VGG和ResNet V1参数已经从原始的caffe格式(这里和此处)转换,而Inception和ResNet V2参数已在Google内部进行了训练。 还要注意,这些精度是通过使用单个图像作为参考进行评估来计算的。 一些学术论文通过多种尺度统计将具有更高的准确性。
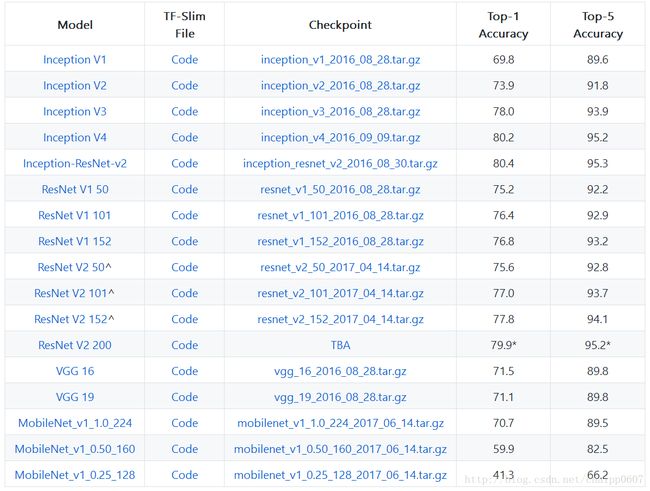
ResNet V2 模型使用imception预处理,输入图片尺寸为299(使用--preprocessing_name inception --eval_image_size 299 当使用 eval_image_classifier.py)。ResNet V2的性能验证与ImageNet验证集。
所有的16个MobileNet Models在MobileNet Paper 中能够找到。
下面是一个例子关于如何下载Inception V3模型的checkpoint:
$ CHECKPOINT_DIR=/tmp/checkpoints
$ mkdir ${CHECKPOINT_DIR}
$ wget http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz
$ tar -xvf inception_v3_2016_08_28.tar.gz
$ mv inception_v3.ckpt ${CHECKPOINT_DIR}
$ rm inception_v3_2016_08_28.tar.gz从头开始训练模型
我们提供一个简单的方法使用TF-Slim数据集从头训练一个模型。以下示例演示如何使用ImageNet数据集上的默认参数训练Inception V3。
DATASET_DIR=/tmp/imagenet
TRAIN_DIR=/tmp/train_logs
python train_image_classifier.py \
--train_dir=${TRAIN_DIR} \
--dataset_name=imagenet \
--dataset_split_name=train \
--dataset_dir=${DATASET_DIR} \
--model_name=inception_v3此过程可能需要几天时间,具体取决于您的硬件设置。 为了方便起见,我们提供了一种同时或异步地在多个GPU和/或多个CPU上训练模型的方法。 有关详细信息,请参阅model_deploy。
TensorBoard
为了在训练期间损失和其他指标可视化,可以通过运行以下命令使用TensorBoard
:
tensorboard --logdir=${TRAIN_DIR}一旦TensorBoard开始运行,即可在浏览器中打开http://localhost:6006。
从已存在的checkpoint Fine-tuning一个模型
我们经常希望从预先训练的模型开始,并对其进行Fine-tuning,而不是从头开始训练。 我们需要声明使用哪个checkpoint进行Fine-tuning,我们通常使用--checkpoint_path来标志检查的路径,并将其分配给检查点文件的绝对路径。
在Fine-tuning模型时,我们需要小心恢复checkpoint的权重。 特别是,当我们用不同数量的输出标签对新任务进行Fine-tuning时,我们将无法恢复最终的logits (分类器)层。 为此,我们将使用–checkpoint_exclude_scopes标志。 该标志阻碍某些变量的加载。 当使用与训练模型不同数量的类对分类任务进行Fine-tune时,新模型将具有与预训练模型不同的最终“logits”层。 例如,如果在Flowers上Fine-tune ImageNet数据集上预训练的模型,预训练的Logist Layer将具有[2048×1001]的尺寸,但是我们需要的是[2048×5]的尺寸。 因此,该标志表示TF-Slim以避免从检查点加载这些权重。
需要记住的是,只有第一次进行Fine-tune时,才会从预训练模型的checkpoint中加载权值,一旦模型开始训练了,新的checkpoint将被保存在${TRAIN_DIR}路径下,如果此时训练停止并再次开始,加载的权值就不再是预训练模型的checkpoint了,而是${TRAIN_DIR}路径下的结果, 因此,标志--checkpoint_path和--checkpoint_exclude_scopes仅在第0个全局步骤(模型初始化)期间使用。 通常,对于Fine-tune,只需要训练一部分子层,所以标志–trainable_scopes允许指定哪些层子层应该训练,其余的将保持冻结。
下面我们给出一个例子:在flowes数据集上迁移学习inception-V3模型,inception_v3在ImageNet上训练了1000个类标签,但是flowes数据集只有5个类。 由于数据集相当小,我们只会训练新的层(Logist Layer)。
$ DATASET_DIR=/tmp/flowers
$ TRAIN_DIR=/tmp/flowers-models/inception_v3
$ CHECKPOINT_PATH=/tmp/my_checkpoints/inception_v3.ckpt
$ python train_image_classifier.py \
--train_dir=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=flowers \
--dataset_split_name=train \
--model_name=inception_v3 \
--checkpoint_path=${CHECKPOINT_PATH} \
--checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits \
--trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits评估模型的性能
在评估模型的性能时,您可以使用eval_image_classifier.py脚本,就像下面展示的:
下面我们给出一个例子关于下载预训练的模型和它在imagenet数据集上的性能评估。
CHECKPOINT_FILE = ${CHECKPOINT_DIR}/inception_v3.ckpt # Example
$ python eval_image_classifier.py \
--alsologtostderr \
--checkpoint_path=${CHECKPOINT_FILE} \
--dataset_dir=${DATASET_DIR} \
--dataset_name=imagenet \
--dataset_split_name=validation \
--model_name=inception_v3导出模型
保存包含模型体系结构的GraphDef。
要使用由slim定义的模型名称,请运行:
$ python export_inference_graph.py \
--alsologtostderr \
--model_name=inception_v3 \
--output_file=/tmp/inception_v3_inf_graph.pb
$ python export_inference_graph.py \
--alsologtostderr \
--model_name=mobilenet_v1 \
--image_size=224 \
--output_file=/tmp/mobilenet_v1_224.pb整合导出的Graph
如果然后要将结果模型与您自己的或预先训练的检查点一起用作mobile model,则可以运行freeze_graph以使用以下内容将变量内嵌为常量:
bazel build tensorflow/python/tools:freeze_graph
bazel-bin/tensorflow/python/tools/freeze_graph \
--input_graph=/tmp/inception_v3_inf_graph.pb \
--input_checkpoint=/tmp/checkpoints/inception_v3.ckpt \
--input_binary=true --output_graph=/tmp/frozen_inception_v3.pb \
--output_node_names=InceptionV3/Predictions/Reshape_1输出节点名称将根据型号而有所不同,但您可以使用summarize_graph工具检查和估计它们。
bazel build tensorflow/tools/graph_transforms:summarize_graph
bazel-bin/tensorflow/tools/graph_transforms/summarize_graph \
--in_graph=/tmp/inception_v3_inf_graph.pb用C++运行标签图片
想要在C++中运行结果图:
bazel build tensorflow/examples/label_image:label_image
bazel-bin/tensorflow/examples/label_image/label_image \
--image=${HOME}/Pictures/flowers.jpg \
--input_layer=input \
--output_layer=InceptionV3/Predictions/Reshape_1 \
--graph=/tmp/frozen_inception_v3.pb \
--labels=/tmp/imagenet_slim_labels.txt \
--input_mean=0 \
--input_std=255故障排除
该模型耗尽CPU内存:
Model Runs out of CPU memory
该模型耗尽GPU内存:
The model runs out of GPU memory
The model training results in NaN’s:
Model Resulting in NaNs.
ResNet和VGG有1000类,但是ImageNet有1001类:
ImageNet数据集提供了一个空白背景类。如果您尝试用VGG或者ResNet进行Fine-tuning和train的时候,可能会报出如下错误:
InvalidArgumentError: Assign requires shapes of both tensors to match. lhs shape= [1001] rhs shape= [1000]这是因为模型只有1000类而不是1001类。为了解决这个问题,您应该设置标志位--labels_offset=1。
我想使用不同的图片尺寸训练模型:
预处理功能全部以高度和宽度为参数。 您可以使用以下代码段更改默认值:
image_preprocessing_fn = preprocessing_factory.get_preprocessing(
preprocessing_name,
height=MY_NEW_HEIGHT,
width=MY_NEW_WIDTH,
is_training=True)硬件参数参考:
Hardware Specifications