hive-TextInputformat自定义分隔符
前言
在一次利用sqoop将关系型数据库Oracle中的数据导入到hive的测试中,出现了一个分割符的问题。oracle中有字段中含有\n换行符,由于hive默认是以’\n’作为换行分割符的,所以用sqoop将oracle中数据导入到hive中导致hive中的数据条目跟原始数据库不一致,当时的处理方式是数据在导入到HDFS之前,用sqoop的参数将字段中的换行符都替换掉。
Sqoop在将数据从关系型数据库导入到HDFS时,支持将\n替换成自定义换行符(支持单字符自定义换行符),但是在hive中建表时用语句

< linesterminated by>参数目前仅支持’\n’。不能指定自定义换行符,这样自定义换行符的数据就不能导入到hive中,基于以上考虑,本文简单说明了如何让hive实现自定义多个字符的换行和字段分割符,供大家参考。如有不足请批评指正。
环境
- Hadoop:2.2
- Hive:0.12(星环inceptor,支持原生hive)
目标
- 分析hive自定义多字符串换行符;
- 实现hive自定义多字符串字段分隔符;
- 实现hivetextinputformat自定义编码格式的设置。
1.hive的序列化与反序列化
Hive中,默认使用的是TextInputFormat,一行表示一条记录。在每条记录(一行中),默认使用^A分割各个字段。
在有些时候,我们往往面对多行,结构化的文档,并需要将其导入Hive处理,此时,就需要自定义InputFormat、OutputFormat,以及SerDe了。
首先来理清这三者之间的关系,我们直接引用Hive官方说法:
SerDe is a short name for “Serializer and Deserializer.”
Hive uses SerDe (and !FileFormat) to read and write table rows.
HDFS files –> InputFileFormat –>
Row object –> Serializer –>
总结一下,面对一个HDFS上的文件,Hive将如下处理(以读为例):
(1) 调用InputFormat,将文件切成不同的文档。每篇文档即一行(Row)。
(2) 调用SerDe的Deserializer,将一行(Row),切分为各个字段。
当HIVE执行INSERT操作,将Row写入文件时,主要调用OutputFormat、SerDe的Seriliazer,顺序与读取相反。
针对含有自定义换行符和字段分隔符的HDFS文件,本文仅介绍hive读取的过程的修改。
2 Hive默认采用的TextInputFormat类
首先建一个简单的表,然后用
transwarp> create table test1(id int);
OK
Time taken: 0.062seconds
transwarp>describe extended test1;
OK
id int None
Detailed Table Information
Table(tableName:test1, dbName:default, owner:root,createTime:1409300219, lastAccessTime:0, retention:0,
sd:StorageDescriptor(
cols:[FieldSchema(name:id, type:int,comment:null)],location:hdfs://leezq-vm3:8020/inceptor1/user/hive/warehouse/test1,
inputFormat:org.apache.hadoop.mapred.TextInputFormat,outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat,
compressed:false,
numBuckets:-1,
serdeInfo:SerDeInfo(
name:null,
serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe,
parameters:{serialization.format=1}),
bucketCols:[], sortCols:[], parameters:{},skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[],skewedColValueLocationMaps:{}), storedAsSubDirectories:false),partitionKeys:[],
parameters:{transient_lastDdlTime=1409300219},
viewOriginalText:null, viewExpandedText:null,tableType:MANAGED_TABLE
)
Time taken: 0.121 seconds, Fetched: 3 row(s)从上面可以看出,默认状态下,hive的输入和输出调用的类分别为:
inputFormat:org.apache.hadoop.mapred.TextInputFormat,
outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat,虽然现在现在hadoop现在升级到2.X版本,hive依然采用老版的mapred接口。
我们要改写的就是类TextInputFormat。
2.1类 TextInputFormat
类TextInputFormat在hadoop-mapreduce-client-core-2.2.0.jar中。
重点看类中getRecordReader方法,该方法返回LineRecordReader对象。并且该方法中已经实现了接收自定义字符串作为换行符的代码,只要建表前在hive的CLI界面上输入set textinputformat.record.delimiter=<自定义换行字符串>;即可实现自定义多字符换行符。

2.2类LineRecordReader
为了进一步查看其实现原理,我们进一步看LineRecordReader(package org.apache.hadoop.mapred. LineRecordReader)类。

查看该类的构造函数,该类调用org.apache.hadoop.util.LineReader(在包hadoop-common-2.2.0.jar中)获取每行的数据,把参数recordDelimiter传给类对象LineReader,类LineReader中的readLine(Text str, int maxLineLength, intmaxBytesToConsume)方法负责按照用户自定义分隔符返回每行的长度,如果用户不设定 textinputformat.record.delimiter的值,recordDelimiter的值为null,这时readLine方法就会按照默认’\n’分割每行。readLine的代码如下:

通过读源码可以看到,原始的hive可以通过设置参数的方法实现多字符自定义换行符(textFile的存储方式),通过上图中readCustomLine方法获得用户自定义换行符的字符串实现自动换行,每行最大可支持2147483648大小。但是要想实现自定义多字符的字段分隔符和自定义编码格式的设置,还需要对源码进行改写。下面就讲一下改写的步骤。
3 自定义TextInputFormat
- 实现自定义多字符串的字段分割符
- 实现自定义编码格式的设置
首先建一个空的java工程,添加必须的五个包

然后新建两个类SQPTextInputFormat和SQPRecordReader,将TextInputFormat和LineRecordReader的代码分别拷贝过来。
在SQPTextInputFormat中添加对自定义编码格式的设置。(对换行符的参数进行了更名,将textinputformat.record.delimiter改成了textinputformat.record.linesep)
//======================================================
String delimiter = job.get("textinputformat.record.linesep");
this.encoding = job.get("textinputformat.record.encoding",defaultEncoding);
byte[] recordDelimiterBytes = null;
if (null != delimiter) {//Charsets.UTF_8
recordDelimiterBytes = delimiter.getBytes(this.encoding);
}
return new SQPRecordReader(job, (FileSplit)genericSplit, recordDelimiterBytes);
在SQPRecordReader构造函数中添加对字段分隔符和编码格式的设置。
//======================================================
this.FieldSep = job.get("textinputformat.record.fieldsep",defaultFSep);
this.encoding = job.get("textinputformat.record.encoding",defaultEncoding);
在SQPRecordReader的next()方法中添加对字段分割符的替换和对编码格式的设置。
//======================================================
if (encoding.compareTo(defaultEncoding) != 0) {
String str = new String(value.getBytes(), 0,value.getLength(), encoding);
value.set(str);
}
if (FieldSep.compareTo(defaultFSep) != 0) {
String replacedValue = value.toString().replace(FieldSep, defaultFSep);
value.set(replacedValue);详细的代码如下:
package com.learn.util.hadoop;
//import com.google.common.base.Charsets;
import java.io.IOException;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.SplittableCompressionCodec;
import org.apache.hadoop.mapred.*;
public class SQPTextInputFormat extends FileInputFormat
implements JobConfigurable
{
private CompressionCodecFactory compressionCodecs = null;
private final static String defaultEncoding = "UTF-8";//"US-ASCII""ISO-8859-1""UTF-8""UTF-16BE""UTF-16LE""UTF-16"
private String encoding = null;
public void configure(JobConf conf) {
this.compressionCodecs = new CompressionCodecFactory(conf);
}
protected boolean isSplitable(FileSystem fs, Path file) {
CompressionCodec codec = this.compressionCodecs.getCodec(file);
if (null == codec) {
return true;
}
return codec instanceof SplittableCompressionCodec;
}
public RecordReader getRecordReader(InputSplit genericSplit, JobConf job, Reporter reporter)
throws IOException
{
reporter.setStatus(genericSplit.toString());
String delimiter = job.get("textinputformat.record.linesep");
this.encoding = job.get("textinputformat.record.encoding",defaultEncoding);
byte[] recordDelimiterBytes = null;
if (null != delimiter) {//Charsets.UTF_8
recordDelimiterBytes = delimiter.getBytes(this.encoding);
}
return new SQPRecordReader(job, (FileSplit)genericSplit, recordDelimiterBytes);
}
} package com.learn.util.hadoop;
import java.io.IOException;
import java.io.InputStream;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.classification.InterfaceAudience.LimitedPrivate;
import org.apache.hadoop.classification.InterfaceStability.Unstable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.Seekable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CodecPool;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.Decompressor;
import org.apache.hadoop.io.compress.SplitCompressionInputStream;
import org.apache.hadoop.io.compress.SplittableCompressionCodec;
import org.apache.hadoop.io.compress.SplittableCompressionCodec.READ_MODE;
import org.apache.hadoop.util.LineReader;
import org.apache.hadoop.mapred.RecordReader;
import org.apache.hadoop.mapred.FileSplit;
//@InterfaceAudience.LimitedPrivate({"MapReduce", "Pig"})
//@InterfaceStability.Unstable
public class SQPRecordReader
implements RecordReader
{
private static final Log LOG = LogFactory.getLog(SQPRecordReader.class.getName());
private CompressionCodecFactory compressionCodecs = null;
private long start;
private long pos;
private long end;
private LineReader in;
private FSDataInputStream fileIn;
private final Seekable filePosition;
int maxLineLength;
private CompressionCodec codec;
private Decompressor decompressor;
private String FieldSep; //field separator
private static final String defaultFSep="\001";
private final static String defaultEncoding = "UTF-8";//"US-ASCII""ISO-8859-1""UTF-8""UTF-16BE""UTF-16LE""UTF-16"
private String encoding = null;
public SQPRecordReader(Configuration job, FileSplit split)
throws IOException
{
this(job, split, null);
}
public SQPRecordReader(Configuration job, FileSplit split, byte[] recordDelimiter) throws IOException
{
this.maxLineLength = job.getInt("mapreduce.input.linerecordreader.line.maxlength", 2147483647);
this.FieldSep = job.get("textinputformat.record.fieldsep",defaultFSep);
this.encoding = job.get("textinputformat.record.encoding",defaultEncoding);
this.start = split.getStart();
this.end = (this.start + split.getLength());
Path file = split.getPath();
this.compressionCodecs = new CompressionCodecFactory(job);
this.codec = this.compressionCodecs.getCodec(file);
FileSystem fs = file.getFileSystem(job);
this.fileIn = fs.open(file);
if (isCompressedInput()) {
this.decompressor = CodecPool.getDecompressor(this.codec);
if ((this.codec instanceof SplittableCompressionCodec)) {
SplitCompressionInputStream cIn = ((SplittableCompressionCodec)this.codec).createInputStream(this.fileIn, this.decompressor, this.start, this.end, SplittableCompressionCodec.READ_MODE.BYBLOCK);
this.in = new LineReader(cIn, job, recordDelimiter);
this.start = cIn.getAdjustedStart();
this.end = cIn.getAdjustedEnd();
this.filePosition = cIn;
} else {
this.in = new LineReader(this.codec.createInputStream(this.fileIn, this.decompressor), job, recordDelimiter);
this.filePosition = this.fileIn;
}
} else {
this.fileIn.seek(this.start);
this.in = new LineReader(this.fileIn, job, recordDelimiter);
this.filePosition = this.fileIn;
}
if (this.start != 0L) {
this.start += this.in.readLine(new Text(), 0, maxBytesToConsume(this.start));
}
this.pos = this.start;
}
public SQPRecordReader(InputStream in, long offset, long endOffset, int maxLineLength)
{
this(in, offset, endOffset, maxLineLength, null);
}
public SQPRecordReader(InputStream in, long offset, long endOffset, int maxLineLength, byte[] recordDelimiter)
{
this.maxLineLength = maxLineLength;
this.in = new LineReader(in, recordDelimiter);
this.start = offset;
this.pos = offset;
this.end = endOffset;
this.filePosition = null;
}
public SQPRecordReader(InputStream in, long offset, long endOffset, Configuration job)
throws IOException
{
this(in, offset, endOffset, job, null);
}
public SQPRecordReader(InputStream in, long offset, long endOffset, Configuration job, byte[] recordDelimiter)
throws IOException
{
this.maxLineLength = job.getInt("mapreduce.input.linerecordreader.line.maxlength", 2147483647);
this.in = new LineReader(in, job, recordDelimiter);
this.start = offset;
this.pos = offset;
this.end = endOffset;
this.filePosition = null;
}
public LongWritable createKey() {
return new LongWritable();
}
public Text createValue() {
return new Text();
}
private boolean isCompressedInput() {
return this.codec != null;
}
private int maxBytesToConsume(long pos) {
return isCompressedInput() ? 2147483647 : (int)Math.min(2147483647L, this.end - pos);
}
private long getFilePosition()
throws IOException
{
long retVal;
if ((isCompressedInput()) && (null != this.filePosition))
retVal = this.filePosition.getPos();
else {
retVal = this.pos;
}
return retVal;
}
public synchronized boolean next(LongWritable key, Text value)
throws IOException
{
while (getFilePosition() <= this.end) {
key.set(this.pos);
int newSize = this.in.readLine(value, this.maxLineLength, Math.max(maxBytesToConsume(this.pos), this.maxLineLength));
if (newSize == 0) {
return false;
}
if (encoding.compareTo(defaultEncoding) != 0) {
String str = new String(value.getBytes(), 0, value.getLength(), encoding);
value.set(str);
}
if (FieldSep.compareTo(defaultFSep) != 0) {
String replacedValue = value.toString().replace(FieldSep, defaultFSep);
value.set(replacedValue);
}
this.pos += newSize;
if (newSize < this.maxLineLength) {
return true;
}
LOG.info("Skipped line of size " + newSize + " at pos " + (this.pos - newSize));
}
return false;
}
public synchronized float getProgress()
throws IOException
{
if (this.start == this.end) {
return 0.0F;
}
return Math.min(1.0F, (float)(getFilePosition() - this.start) / (float)(this.end - this.start));
}
public synchronized long getPos() throws IOException
{
return this.pos;
}
public synchronized void close() throws IOException {
try {
if (this.in != null)
this.in.close();
}
finally {
if (this.decompressor != null)
CodecPool.returnDecompressor(this.decompressor);
}
}
}
4 自定义InputFormat的使用
1. 将程序打成jar包,放在/usr/lib/hive/lib和各个节点的/usr/lib/hadoop-mapreduce目录下。
在hvie的CLI命令行界面可以设置如下参数,分别修改编码格式、自定义字段分隔符和自定义换行符。
set textinputformat.record.encoding=UTF-8;
//"US-ASCII""ISO-8859-1""UTF-8""UTF-16BE""UTF-16LE""UTF-16"
set textinputformat.record.fieldsep=,;
set textinputformat.record.linesep=|+|;2. 建表,标示采用的Inputformat和OutputFormat,其中org.apach…noreKeyTextOutputFormat 是hive默认的OutputFormat分隔符。
create table test
(
id string,
name string
)
stored as
INPUTFORMAT'com.learn.util.hadoop.SQPTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'3. Load 语句加载数据
实例
测试数据:
![]()
测试数据中有一个字段中含有换行符。字段分隔符和行分隔符分别为’,’和“|+|”。
分别设置字段分隔符和行分割符,并建表指定Inputformat和outputformat如下图所示,

Select * 查询如下:
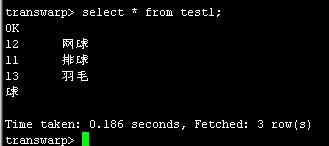
Select count(*)如下:
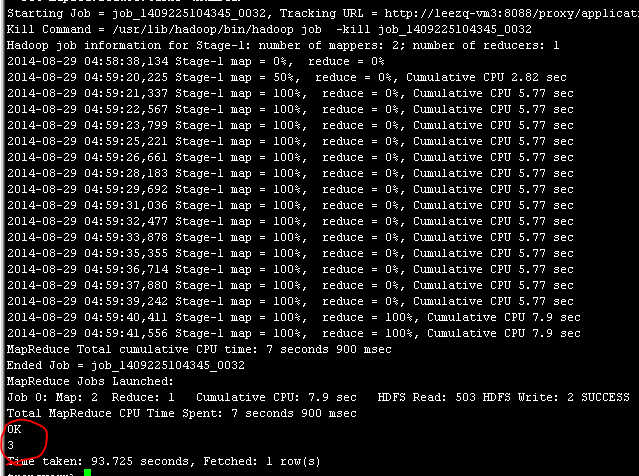
结果是3行,正确。
Select id from test1如下:

Select name from test1:

Select count(name) from test1:

结果正确。
Select name,id from test1:

Select id,name from test1;

Id和name两个字段单独查没问题,但是调用mapreduce一起查的时候带有‘\n’的字段显示上出了问题。
Select id,name from test1 where id=13:
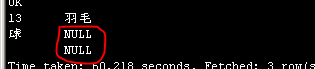
单独查询每个字段时候和查询总行数的时候都是没问题的,这说明改写的InputFormat起作用了,上面的出现的NULL问题应该是hive显示的问题。