
自然场景下的文字检测是深度学习的重要应用,在之前的文章中已经介绍过了在简单场景、复杂场景下的文字检测方法,包括MSER+NMS、CTPN、SegLink、EAST等方法,详见文章:
【AI实战】手把手教你文字识别(检测篇一: MSER、CTPN、SegLink、EAST方法)
今天将继续介绍复杂场景下基于深度学习的文本检测方法,手把手教你如何使用AdvancedEAST、PixelLink进行文本检测。
1、AdvancedEAST方法实战
在上一篇文本检测的AI实战文章中,介绍了EAST检测方式,取得了不错的检测效果,但是在长文本预测中效果还不是很理想。于是,有大牛对EAST检测方法进行了改进,获得了比EAST更好的预测准确性(特别是在长文本上),并开源了源代码,这就是AdvancedEAST方法。网络结构如下:
AdvancedEAST的网络结构与EAST相似(EAST技术原理详见文章:大话文本检测经典模型EAST),但采用了VGG作为网络主干结构,基于Keras编写,在特征提取层中增加了后面卷积层的通道数量,对后处理方法也进行了优化。下面动手来试试AdvancedEAST的实际检测效果吧。
(1)下载源代码
首先,在github上下载AdvancedEAST源代码(https://github.com/huoyijie/AdvancedEAST),可直接下载成zip压缩包或者git克隆
git clone https://github.com/huoyijie/AdvancedEAST.git(2)下载模型文件
下载AdvancedEAST预训练好的模型,下载链接: https://pan.baidu.com/s/1KO7tR_MW767ggmbTjIJpuQ 提取码: kpm2
创建文件夹saved_model,将下载后的模型文件解压后放到里面
修改cfg.py文件里面的train_task_id,将该id修改与下载的预训练模型一致,以便于在执行程序时,可自动加载模型,修改如下:
train_task_id = ‘3T736’下载keras的VGG预训练模型,因为AdvancedEAST使用了VGG作为网络的主干结构,因此,在调用keras时会加载VGG预训练模型,下载地址为https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5,然后放到keras加载模型的默认路径,目录如下:
~/.keras/model如果没有手动下载,那么在加载keras的VGG模型时,程序也会自动下载,但一般速度会很慢,经常会超时
(3)准备基础环境
AdvancedEAST依赖于以下的基础环境,使用conda或pip进行安装准备。
- python 3.6.3+
- tensorflow-gpu 1.5.0+(or tensorflow 1.5.0+)
- keras 2.1.4+
- numpy 1.14.1+
- tqdm 4.19.7+
(4)AdvancedEAST检测文本
执行python predict.py进行文本检测
默认读取项目自带的demo/012.png文件,进行检测
检测后生成以下文件
其中,012.png_act.jpg是检测过程的结果
012.png_predict.jpg是检测出最终文本框的圈定结果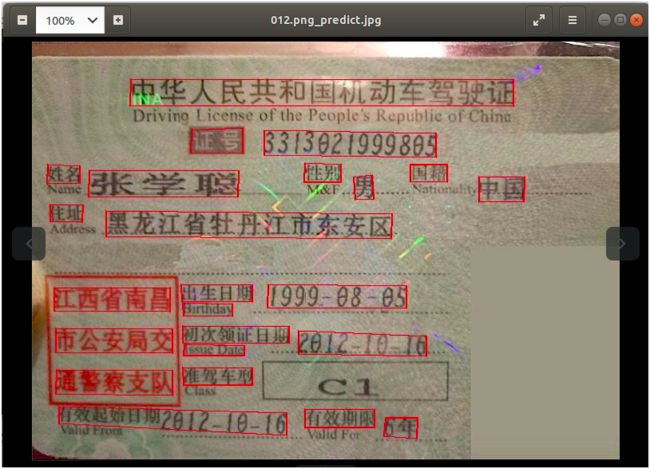
012.txt是检测文本框的位置坐标(4个顶点)
在执行模型时,其中会有少部分检测结果是不完整的(边框少于4个顶点),默认会显示出来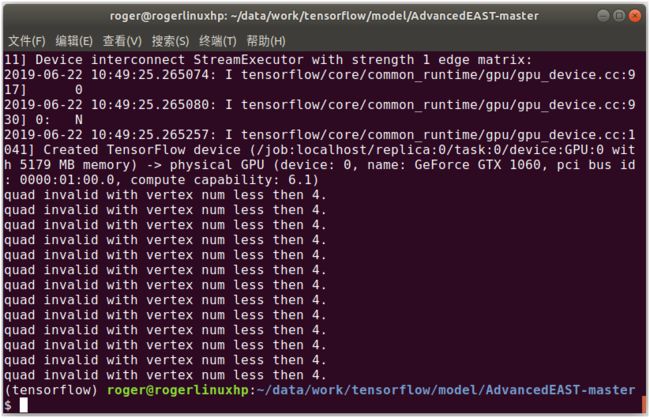
可通过在predict.py的源代码中,让其保持静默(不提示不完整的检测结果),修改最后一行为
predict(east_detect, img_path, threshold, quiet=True)如果要检测指定的图片,在执行python predict.py时,可通过增加参数指定图片路径。另外,还可指定阈值,即在做像素分类判断是否为文本的阈值,默认为0.9。执行命令如下:
python predict.py --path=/data/work/tensorflow/data/icdar_datasets/ICDAR2015/ch4_test_images/img_364.jpg --threshold=0.9
执行效果如下:
(5)AdvancedEAST接口封装
为了方便其它程序调用AdvancedEAST的文本检测能力,在predict.py的基础上进行代码修改,对AdvancedEAST进行接口封装,核心代码如下:
# sigmoid 函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# AdvancedEAST 模型
def east_detect():
east = East()
east_detect = east.east_network()
east_detect.load_weights(cfg.saved_model_weights_file_path)
return east_detect
# 基于 Advanced EAST 的文本检测
# 输入:AdvancedEAST模型,图片路径,像素分类阈值
# 返回:检测后文本框的位置信息
def text_detect(east_detect,img_path,pixel_threshold=0.9):
img = image.load_img(img_path)
d_wight, d_height = resize_image(img, cfg.max_predict_img_size)
scale_ratio_w = d_wight / img.width
scale_ratio_h = d_height / img.height
img = img.resize((d_wight, d_height), Image.NEAREST).convert('RGB')
img = image.img_to_array(img)
img = preprocess_input(img, mode='tf')
x = np.expand_dims(img, axis=0)
y = east_detect.predict(x)
y = np.squeeze(y, axis=0)
y[:, :, :3] = sigmoid(y[:, :, :3])
cond = np.greater_equal(y[:, :, 0], pixel_threshold)
activation_pixels = np.where(cond)
quad_scores, quad_after_nms = nms(y, activation_pixels)
bboxes = []
for score, geo in zip(quad_scores, quad_after_nms):
if np.amin(score) > 0:
rescaled_geo = geo / [scale_ratio_w, scale_ratio_h]
rescaled_geo_list = np.reshape(rescaled_geo, (8,)).tolist()
bboxes.append(rescaled_geo_list)
return bboxes
2、Pixel Link方法实战
前面介绍的文本检测方法,一般都是执行两个预测:通过分类判断是文本/非文本,通过回归确定边界框的位置和角度。其中,回归的耗时比分类要多得多,而PixelLink(像素连接)方法则全部都是通过“分类”的方式实现文本/非文本的判断,并同时给出文本框的位置和角度,具体技术原理详见之前的文章:大话文本检测经典模型PixelLink。
PixelLink的整体框架如下图:
下面介绍如何使用PixelLink模型来检测文字。
(1)下载源代码和模型
首先,在github上下载PixelLink源代码(https://github.com/ZJULearning/pixel_link),可直接下载成zip压缩包或者git克隆
git clone https://github.com/ZJULearning/pixel_link.git下载pylib,下载路径为https://github.com/dengdan/pylib/tree/e749559c9a4bcee3339081ec2d159a6dcf41636e ,解压后将src目录中的util文件夹放到pylib目录下面,然后添加到环境变量,在test_pixel_link.py , test_pixel_link_on_any_image.py, visualize_detection_result.py, datasets/dataset_utils.py的前面加上
import sys
sys.path.append('/data/work/tensorflow/model/pixel_link/pixel_link-master/pylib')
sys.path.append('/data/work/tensorflow/model/pixel_link/pixel_link-master/pylib/util')或者在当前窗口执行以下命令,或在 /etc/profile,~/.bashrc 文件中添加以下命令
export PYTHONPATH=xx:$PYTHONPATH下载基于IC15数据集预训练好的模型,作者提供了两个预训练好的模型PixelLink + VGG16 4s (下载地址 https://pan.baidu.com/s/1jsOc-cutC4GyF-wMMyj5-w),PixelLink + VGG16 2s(下载地址 https://pan.baidu.com/s/1asSFsRSgviU2GnvGt2lAUw)
新建文件夹models/4s和models/2s,解压模型压缩文件,将两个模型放入到相应的目录下,方便进行调用
(2)安装基础环境
在下载的源代码文件中pixel_link_env.txt文件提供了conda基础环境安装包,其中,由于现在清华的conda镜像源已停止服务,于是将其替换为中科大的conda镜像源,修改后的依赖基础环境如下:
name: pixel_link
channels:
- menpo
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free
- https://mirrors.ustc.edu.cn/anaconda/pkgs/main
- defaults
dependencies:
- certifi=2016.2.28=py27_0
- cudatoolkit=7.5=2
- cudnn=5.1=0
- funcsigs=1.0.2=py27_0
- libprotobuf=3.4.0=0
- mkl=2017.0.3=0
- mock=2.0.0=py27_0
- numpy=1.12.1=py27_0
- openssl=1.0.2l=0
- pbr=1.10.0=py27_0
- pip=9.0.1=py27_1
- protobuf=3.4.0=py27_0
- python=2.7.13=0
- readline=6.2=2
- setuptools=36.4.0=py27_1
- six=1.10.0=py27_0
- sqlite=3.13.0=0
- tensorflow-gpu=1.1.0=np112py27_0
- tk=8.5.18=0
- werkzeug=0.12.2=py27_0
- wheel=0.29.0=py27_0
- zlib=1.2.11=0
- opencv=2.4.11=nppy27_0
- pip:
- backports.functools-lru-cache==1.5
- bottle==0.12.13
- cycler==0.10.0
- cython==0.28.2
- enum34==1.1.6
- kiwisolver==1.0.1
- matplotlib==2.2.2
- olefile==0.44
- pillow==4.3.0
- polygon2==2.0.8
- pyparsing==2.2.0
- python-dateutil==2.7.2
- pytz==2018.4
- setproctitle==1.1.10
- subprocess32==3.2.7
- tensorflow==1.1.0
- virtualenv==15.1.0使用以下命令创建pixel_link的conda虚拟环境和安装基础依赖包
conda env create --file pixel_link_env.txt
完成基础环境包安装之后,即可使用以下命令切换到pixel_link虚拟环境,在里面执行相应的操作
source activate pixel_link该源代码提供基础环境是基于python2版本的,如果自己之前已安装了相应的基础环境,即可直接使用,其中,要特别注意的是如果是使用python3,则需要对以下脚本进行改造:
- 修改test_pixel_link.py第94行、第156行、第164行、第166行,在print后面加上括号
- 修改datasets/dataset_util.py第112行,在print后面加上括号
- 修改pylib/util/plt.py第174行,在print后面加上括号
- 修改pylib/util/img.py第8行,在print后面加上括号
- 修改pylib/util/proc.py第29行、第30行,在print后面加上括号。第35行,在raise后面加上括号
- 修改pylib/util/thread_.py第39行,在raise后面加上括号
- 修改pylib/util/caffe_.py第29行、第46行、第47行、第50行,在print后面加上括号
- 修改pixel_link.py第187行,在raise后面加上括号
- 修改pylib/util/tf.py第46行,将xrange改为range
- 修改models/4s/config.py第153行,将xrange改为range
- 修改pixel_link.py第257行、第353行,将xrange改为range
- 由于在python3中没有cPickle,在pylib/util/io_.py中,第11行,将import cPickle as pkl改为import _pickle as pkl
- 由于在python3中commands已由subprocess代替,在pylib/util/io_.py中,第12行,将import commands改为import subprocess as commands。在pylib/util/cmd.py中,第4行,将import commands改为import subprocess as commands
- 在test_pixel_link.py在前面加上import util.cmd
(3)PixelLink检测文本测试(批量图片)
通过运行以下命令进行测试
./scripts/test.sh ${GPU_ID} ${model_path}/model.ckpt-xxx ${image_dir}该命令由三个参数组成,第1个参数表示GPU的序号,第2个参数表示模型路径,第3个参数表示测试图片的目录。
在这里使用刚才下载的PixelLink+VGG16 4s预训练模型,使用场景文字图片数据集ICDAR2015进行测试(下载地址 http://rrc.cvc.uab.es/?ch=4&com=downloads),也可以使用自己的测试图片,将测试的图片放入到指定的目录。
执行脚本如下:
./scripts/test.sh 0 models/4s/model.ckpt-38055 /data/work/tensorflow/data/icdar_datasets/ICDAR2015/ ch4_test_images
检测后的结果保存在模型目录下,结果文件是测试图片中的文本框位置(4个坐标点),如下图:
所有结果还会生成zip压缩文件,如下图:
如果要使检测结果显性化,可通过调用scripts/vis.sh脚本,将会使文本检测的结果直接显示在图片上,调用命令为
./scripts/vis.sh ${image_dir} ${det_dir}其中,第一个参数表示原始图片的路径,第二个参数表示检测后的文本框位置文件所在目录,最后输出的标示文本框图片结果保存在~/temp/no-use/pixel_result目录下
执行脚本如下
./scripts/vis.sh /data/work/tensorflow/data/icdar_datasets/ICDAR2015/ch4_test_images models/4s/test/icdar2015_test/model.ckpt-38055/txt
输出的结果图片如下
(4)PixelLink检测文本测试(任意图片)
为方便测试,可直接调用以下命令对任意图片进行测试,命令如下:
./scripts/test_any.sh ${GPU_ID} ${model_path}/model.ckpt-xxx ${image_dir}该命令由三个参数组成,第1个参数表示GPU的序号,第2个参数表示模型路径,第3个参数表示图片的路径。
例如仍拿ICDAR2015的测试图片集进行测试,执行的命令如下:
./scripts/test_any.sh 0 models/4s/model.ckpt-38055 /data/work/tensorflow/data/icdar_datasets/ICDAR2015/ ch4_test_images
执行后,文字的检测结果将会直接显示在图片上,如下图
可能会有些人有疑惑,test_any.sh命令不就是把test.sh、vis.sh两个命令整合在一起吗,那究竟有什么区别呢?主要的区别如下:
a. test_any.sh命令调用的是test_pixel_link_on_any_image.py,而test.sh命令调用的是test_pixel_link.py,两者在调用检测模型时,test_pixel_link_on_any_image.py将并查集的后处理放到模型里面,而test_pixel_link.py则是将并查集的后处理放到模型外边。从检测效率来看,test_pixel_link_on_any_image.py比test_pixel_link.py在速度上慢了很多,这是由于并查集处理需要大量计算,放到模型外面利用CPU计算反而更加快速
b. test_pixel_link.py只输出文本框位置数据,而test_pixel_link_on_any_image.py直接将检测的文本框标示到图片上
(5)PixelLink文本检测能力封装
为方便其它程序调用PixelLink的文字检测能力,通过对test_pixel_link.py, visualize_detection_result.py代码进行改造封装,即可将文字检测能力提供给相应的程序调用,核心代码如下:
# 模型参数
checkpoint_dir='/data/work/tensorflow/model/pixel_link/pixel_link-master/models/4s/model.ckpt-38055'
image_width = 1280
image_height = 768
# 配置初始化
def config_initialization():
image_shape = (image_height, image_width)
config.init_config(image_shape,
batch_size = 1,
pixel_conf_threshold = 0.8,
link_conf_threshold = 0.8,
num_gpus = 1,
)
# 文本检测
def text_detect(img):
with tf.name_scope('eval'):
image = tf.placeholder(dtype=tf.int32, shape = [None, None, 3])
image_shape = tf.placeholder(dtype = tf.int32, shape = [3, ])
processed_image, _, _, _, _ = ssd_vgg_preprocessing.preprocess_image(image, None, None, None, None,
out_shape = config.image_shape,
data_format = config.data_format,
is_training = False)
b_image = tf.expand_dims(processed_image, axis = 0)
net = pixel_link_symbol.PixelLinkNet(b_image, is_training = True)
global_step = slim.get_or_create_global_step()
sess_config = tf.ConfigProto(log_device_placement = False, allow_soft_placement = True)
sess_config.gpu_options.allow_growth = True
saver = tf.train.Saver()
checkpoint = util.tf.get_latest_ckpt(checkpoint_dir)
bboxes = []
with tf.Session(config = sess_config) as sess:
saver.restore(sess, checkpoint)
image_data = img
pixel_pos_scores, link_pos_scores = sess.run(
[net.pixel_pos_scores, net.link_pos_scores],
feed_dict = {
image:image_data
})
mask = pixel_link.decode_batch(pixel_pos_scores, link_pos_scores)[0, ...]
bboxes = pixel_link.mask_to_bboxes(mask, image_data.shape)
return bboxes(6)pixellink的keras版本
刚才介绍的pixel link是基于tensorflow版本的,还有大牛使用Keras对核心代码进行改写,并在github上开放了keras版本pixel link的源代码。具体使用如下:
a. 下载源代码
下载地址为https://github.com/opconty/pixellink_keras,可直接下载成zip压缩包或者git克隆
git clone https://github.com/opconty/pixellink_keras.gitb. 下载预训练模型
作者并没有重新训练模型,而是直接拿tensorflow版本的训练模型结果PixelLink-VGG 4s,转化为Keras的权重文件。下载地址为https://drive.google.com/file/d/1MK0AkvBMPZ-VfKN5m4QtSWWSUqoMHY33/view?usp=sharing
c. 安装基础环境
除了需要安装Keras之外,还要安装imutils依赖包
pip install imutils如果是使用了OpenCV 4.x,则需要修改pixellink_utils.py第220行,将cv2.findContours的返回结果由3个结果修改为2个结果,将_,cnts,_改为cnts,_
d. 运行模型
执行pixellink_eval.py,即可进行文本检测,命令如下
python pixellink_eval.py
默认对项目自带的图片进行检测(路径./samples/img_1099.jpg),检测效果如下:

如果要指定图片进行检测,可修改pixellink_eval.py文件中第21行,将img_path修改为指定的图片路径,然后再执行python pixellink_eval.py即可对指定的图片进行文字检测
为方便介绍,以上AdvancedEAST、PixelLink的文本检测能力封装时,将加载模型、文本框预测、图片绘制文本框等一些代码写在一起,而在实际生产使用中,一般是将其分开。如要了解在生产环境中的详细使用,可再私信进行交流。
欢迎关注本人的微信公众号“大数据与人工智能Lab”(BigdataAILab),获取 完整源代码


推荐相关阅读
1、AI 实战系列
- 【AI实战】手把手教你文字识别(文字检测篇一:MSER、CTPN、SegLink、EAST 等)
- 【AI实战】手把手教你文字识别(文字检测篇二:AdvancedEAST、PixelLink 方法)
- 【AI实战】手把手教你文字识别(入门篇:验证码识别)
- 【AI实战】快速掌握TensorFlow(一):基本操作
- 【AI实战】快速掌握TensorFlow(二):计算图、会话
- 【AI实战】快速掌握TensorFlow(三):激励函数
- 【AI实战】快速掌握TensorFlow(四):损失函数
- 【AI实战】搭建基础环境
- 【AI实战】训练第一个模型
- 【AI实战】编写人脸识别程序
- 【AI实战】动手训练目标检测模型(SSD篇)
- 【AI实战】动手训练目标检测模型(YOLO篇)
2、大话深度学习系列
- 【精华整理】CNN进化史
- 大话文本识别经典模型(CRNN)
- 大话文本检测经典模型(CTPN)
- 大话文本检测经典模型(SegLink)
- 大话文本检测经典模型(EAST)
- 大话文本检测经典模型(PixelLink)
- 大话文本检测经典模型(Pixel-Anchor)
- 大话卷积神经网络(CNN)
- 大话循环神经网络(RNN)
- 大话深度残差网络(DRN)
- 大话深度信念网络(DBN)
- 大话CNN经典模型:LeNet
- 大话CNN经典模型:AlexNet
- 大话CNN经典模型:VGGNet
- 大话CNN经典模型:GoogLeNet
- 大话目标检测经典模型:RCNN、Fast RCNN、Faster RCNN
- 大话目标检测经典模型:Mask R-CNN
- 大话注意力机制
3、图解 AI 系列
- 什么是语义分割、实例分割、全景分割
- 各种深度学习卷积(标准卷积、反卷积、可分离卷积、分组卷积…)
4、AI 杂谈
- 27种深度学习经典模型
- 浅说“迁移学习”
- 什么是“强化学习”
- AlphaGo算法原理浅析
- 大数据究竟有多少个V
5、大数据超详细系列
- Apache Hadoop 2.8 完全分布式集群搭建超详细教程
- Apache Hive 2.1.1 安装配置超详细教程
- Apache HBase 1.2.6 完全分布式集群搭建超详细教程
- 离线安装Cloudera Manager 5和CDH5(最新版5.13.0)超详细教程