《Linux C编程实战》中一些基础C语言知识 && 一些笔试面试题总结
C语言的数据类型:基本数据类型(整型,浮点类型,字符型),构造数据类型(数组,结构体,枚举,联合体),指针类型,空类型
整型:
十六进制(0~9,A~F),八进制(0~7),十进制(0~9)
32位操作系统上:
Int: 短整型(2),基本整型(4),长整型(4)
Short int : - 2^15 ~2^15-1 -32768~32767
Int : -2^31~2^31-1 -21474836538~21474836538
Unsigned short int: 0~2^16-1 0~65535
Unsigned int : 0~2^32-1 0~4294967295
64位操作系统上:
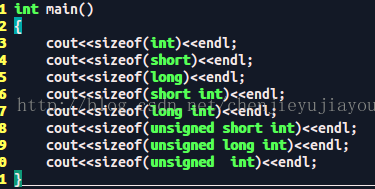
结果:
浮点型
十进制表示:正负号,数字,小数点(必须有)
指数形式:xEy:表示x*10^y,其中y必须为整数
单精度(float 4) :-10^37~10^38 有效数字是7位
双精度(double 8):-10^307~10^308 有效数字为16位
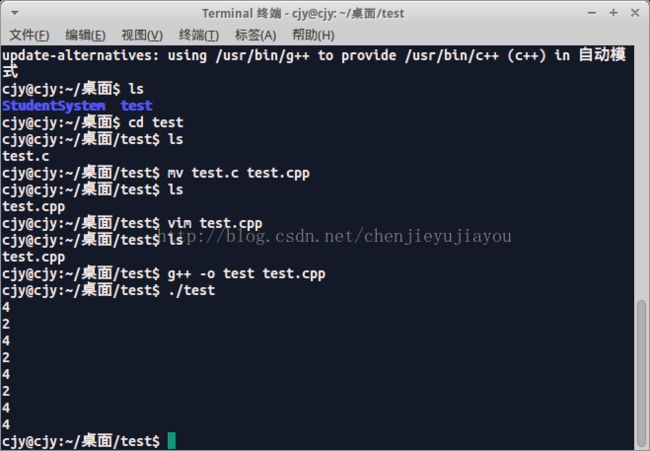
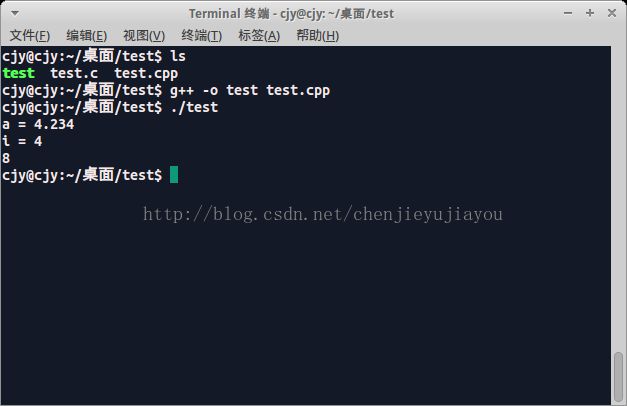
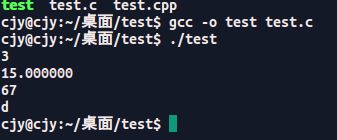
test.c:

结果:
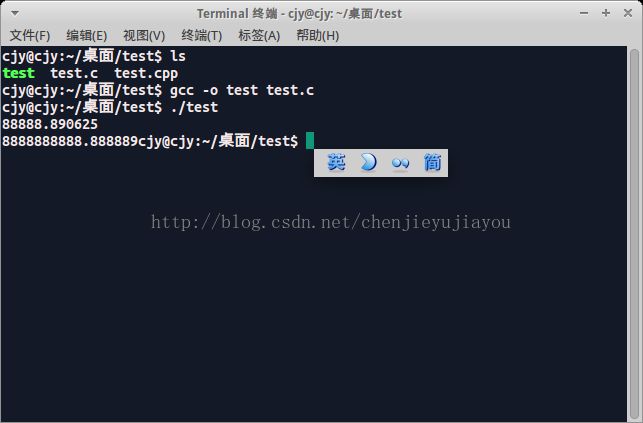
分析:%f ,小数点后最多输出六位
a是单精度浮点型,有效位数只有7位,而整数部分已经占5位,小数部分两位之后均为无效数字,小数部分的9是四舍五入的结果,是最后一位有效位
b是双精度类型:有效数字为16位,最后一位9是四舍五入的结果,%f规定小数点后最多保留6位。
Test.cpp 文件执行的结果和test.c 不太一样:amazing!!!
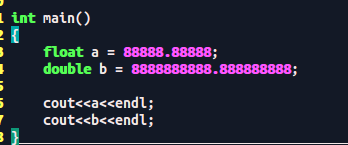
结果:

字符型
字符型常量
用‘ ’括起来的一个字符‘a’,’b’,’c’ ’B’
字符型变量
Char ch = ‘A’;
一个字符型变量在内存中只占一个字节,字符是以ASCII码形式存放在内存单元里面的,A 65 a (97) 取值范围:-128~127
Unsigned char 0~2^8-1(0~255)
因为字符在内存中以ASCII码值存放的,所以可以和整型变量进行运算
转义字符(特殊的字符常量)
以\ 打头
| 字符形式 |
含义 |
| \n |
换行,相当于enter |
| \t |
相当于table键 |
| \b |
退格 backspace |
| \\ |
表示\ |
| \’ |
表示‘ |
| \’’ |
表示“ |
| \0 |
表示字符串的结束 |
字符串常量
”china“
字符串常量在内存中存储模型

字符是以ASCII码值存储的:

符号常量
#define PI 3.141592653
使程序更加清晰,程序的修改更加方便
运算符与表达式
算术运算符与算数表达式
+,—,*,/ %(两边都应该为整数)
当整型(int, short, long ),浮点型(float,double),字符型(char),不同类型的数据先转换为同一类型,然后再进行计算:short型和char型自动转换为int,float型转化为double型
A+’A’:
A是一整型变量。值为1000,A是一个字符型常量,‘A’将转化为int,运算结果就为int:
a+b:
a和b都是float型的,运算时,系统自动将a和b扩充为8个字节的double型进行计算,产生结果后,又把double型换为float型,运算结果为float型。如果float型与double型进行运算,则最后结果为double 型
100+23.6+’A’
在运算时会把char 型转换为int 型,既有int型又有float型:int型会转化为float型,
Float型在进行运算时自动转化为double型进行运算,所以最后三个量都转化为double进行运算,最后又将double转化为fioat
强制类型转换:()
!!!在强制类型转换时,得到的是一个所需的中间类型,原来的变量类型并没有发生变化

结果:
自加和自减运算符(只对单个变量起作用,对常量和表达式不起作用)
i++;(先用后加)
++i;(先加后用)
I--;(先用后减)
--i;(先减后用)
赋值运算符:
如果赋值语句两边的数据类型不同:系统就会自动把右边的类型转换为左边的类型
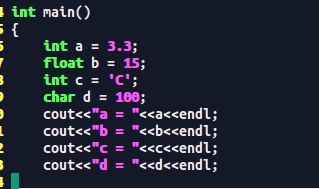
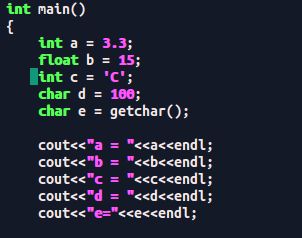
将实型赋给整型:int a = 3.3;
将整型赋给实型:float b = 15;
将字符型赋给整型 int c = ‘C’;
将整型赋给字符型 char d = 100;
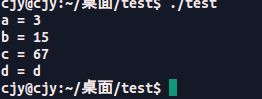
test.cpp
结果:
Test.c
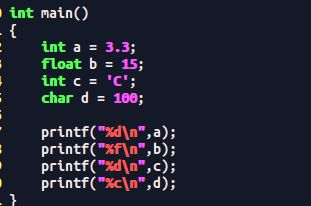
结果:
逗号表达式的优先级是最低的,最后一个表达式的值为整个逗号表达式的值
标准输入输出函数:
键盘:标准输入设备
显示器:标准输出设备
格式化输入函数:scanf(“%d”, &n)
字符输入函数:c=getchar()(一般用法)
初学者一定要注意!!!scanf(“%d”, &n),第一个参数没有\n,第二个参数必须要有&
我在刚开始学习c语言的时候就经常出现这样的小bug;~~~~
此函数接收来自键盘的输入,自动把输入的数据转换为规定的格式并存储到参数指定的变量中 ,参数必须以变量地址的形式给出,也就是我刚才在前面所说的第二个参数 &n
Scanf 使用的格式字符:
| d |
十进制整数 |
| o |
八进制整数 |
| x |
十六进制整数 |
| u |
无符号整数 |
| c |
字符 |
| s |
字符串 |
| f |
浮点数 |
| e |
以科学计数法表示的浮点数 |
分析:要是输入有错误的话,程序会出现什么结果?

结果:
![]()
结果是输出一些奇怪的数
getchar() 只接受一个字符
如下程序验证:
test.c


Cpp 文件验证:
结果:

由此可见getchar()只能接受一个字符,在屏幕上如果输入的字符超过一个,getchar 只接受一个字符,其他字符将会被忽略
输出函数:
输出字符:putchar(c);
C可以是一个字符型常量,字符型变量,或者一个0~255的整型常量或者变量,还可以是转义字符
格式化输出函数:printf()
| d |
十进制整数 |
| o |
八进制整数 |
| x |
十六进制整数 |
| u |
无符号整数 |
| c |
字符 |
| s |
字符串 |
| f |
浮点数 |
| e |
以科学计数法表示的浮点数 |
| g |
输出%f 与%e中占用位数较短的一个 |
—:输出时左对齐,默认方式是右对齐
dd:指定输出参数所占的最小宽度,如果数据的长度小于最小宽度,则多余部分用空格补齐,如printf(“%5d”, i),i的长度大于或者等于5,原样输出,小于5位,左边以空格补齐,如果是%-5d,右边以空格补齐
dd.dd:
(1)用于输出浮点数:前面的dd表示整个浮点数所占的宽度,后面的dd表示小数点之后要输出几位
(2)输出字符串时:前面的dd表示整个字符串所占的宽度,后面的dd表示输出字符串的前dd个字符

结果:
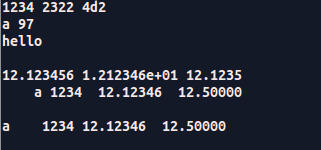
前三行都很简单
从第四行开始说:以三种形式输出浮点型变量f,
以%e输出:小数点之后最多输出六位,最后一位是四舍五入得到的
以%g输出:小数部分只能保留四位最后一位5是四舍五入得到的
%5c左边四位用空格补齐(右对齐)
%-5c(左对齐)
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------华丽的分割线~~~
Vi编辑器的使用:
三种模式:命令行模式,末行模式,插入模式

Vi编辑器命令总结:
| 命令 |
含义 |
| 启动vi |
|
| Vi |
不指定文件名,在保存的时候指出指定的文件名 |
| Vi 文件名 |
该文件既可以是已经存在的,也可以是新建的 |
| Vi +n 文件名 |
进入vi,光标停留在第n行开始处 |
| Vi + 文件名 |
进入光标停留在文件最后一行开始出 |
| Vi +/字符串 |
进入vi,光标停留在第一个字符串处 |
| 保存文件并退出 |
|
| 在命令模式下按两次Z键 |
保存文件并退出 |
| 接下来的命令在末行模式下进行的 W |
保存当前正在进行编辑的文件,但是不推出vi |
| W 文件名 |
将当前文件保存由“文件名”指定的新文件中,该文件存在的话将会产生错误,该命令不会退出vi |
| W! 文件名 |
将当前文件保存到由“文件名”指定的新文件中,如果该文件存在则覆盖 |
| q: |
不进行保存直接退出vi,如果文件有改动而没有保存将会发生错误, |
| q! |
强行退出vi,若文件内容有改动将恢复到文件的原始内容 |
| wq |
保存并退出 |
| 光标的移动 |
|
| ↑ |
移动到上一行,所在的列不变 |
| ↓ |
移动到下一行,所在的列不变 |
| <-- |
左移一个字符,所在的行不变 |
| --> |
右移一个字符,所在的行不变 |
| 0 |
移动到当前行的行首 |
| $ |
移动到当前行的行尾 |
| nw |
右移n个字(从一个字移动到下一个字) 比如printf(“%d\n”,a, b); 就从printf中的第一个p移动到% |
| w |
右移一个字 |
| nb |
左移n个字 |
| b |
左移一个字 |
| (: |
移动到本句的句首,如果已经处于本句的句首,则移动到前一句的句首 |
| ): |
移动到下一句的句首 |
| {: |
移动到本段的句首,如果已经处于本段的段首,则移动到前一段的段首 |
| }: |
移动到下一段的句首 |
| 1G |
移动到文件首行的行首 |
| G |
移动到文件末行的行首 |
| nG |
移动到第n行的行首 |
| 文本的删除 插入模式下的删除与文档的删除方式相同,接下来重点是命令模式下的各种删除方法的展示 |
|
| x |
删除光标所在位置的一个字符 |
| nx |
删除从光标开始的n个字符 |
| dw |
删除光标所在位置的一个字 |
| ndw |
删除从光标开始的n个字 |
| db |
删除光标前的一个字 |
| ndb |
删除从光标开始的前n个字 |
| d0 |
删除从光标前一个到行首的所有字符 |
| d$ |
删除从光标所在字符到行尾的所有字符 |
| dd |
删除光标所在行(常用) |
| ndd |
删除从当前行开始的n行 |
| d(: |
删除从当前字符开始到句首的所有字符 |
| d): |
删除从当前字符开始到句尾的所有字符 |
| d{ |
删除从当前字符开始到段首的所有字符 |
| d} |
删除从当前字符开始到段尾的所有字符 |
| u |
取消操作(常用)
|
| 文本查找和替换 |
|
| ?String |
在命令模式下输入?和要查找的字符串并按回车 |
| n |
在文件头方向重复前一个查找命令 |
| N |
在文件的尾方向重复前一个查找命令 |
| S/oldstr/newstr |
在当前行用newstr替换oldstr,只替换一次 |
| S/oldstr/newstr/g |
在当前行用newstr来替换所有的oldstr字符串 |
| 1,10s/oldstr/newstr/g |
在1~10行用newstr替换所有的oldstr |
| 1,$s/oldstr/newstr/g |
在整个文件中用字符串newstr来替换所有的字符串oldstr |
| 文本的复制与粘贴(复制是把指定内容复制到内存的一块缓冲区中,而粘贴是把缓冲区的内容粘贴到光标所在的位置) |
|
| yw |
将光标所在位置到字尾的字符复制到缓冲区(最多复制一个字) |
| nyw |
将光标所在位置开始的n个字复制到缓冲区,n为数字 |
| yb |
从光标开始向左复制一个字 |
| nyb |
从光标开始向左复制n个字,n为数字 |
| y0 |
复制从光标前一个字符到行首的所有字符 |
| Y$ |
复制从光标开始到行末的所有字符 |
| yy |
复制当前行:光标所在行(常用) |
| nyy |
复制从当前行开始的n行,n是数字 |
| p |
在光标所在位置的后面插入复制的文本 |
| P |
在光标所在位置的前面插入复制的文本 |
| np |
在光标所在位置的后面插入复制的文本,粘贴n次 |
| nP |
在光标所在位置的前面插入复制的文本,粘贴n次 |
可以在末行模式下输入:set nu
或者 set number
给每一行添加行号,但是行号不是文件内容的一部分
————————————————————————————————————————————————————————————————华丽的分割线
命名规范
1.标识符(变量名,函数名,数组名)
2.标识符只能由:字母,数字,下划线组成,并且每一个标识符第一个字符只能是字母和下划线,不能是数字
下面列举一些不合法的标识符:
(1)3count: 以数字开头
(2)char char是数据类型,不能作为标识符
(3)a*b: *不能作为标识符的字符
(4)number of book: 标识符中不能有空格
关键字:具有特殊含义的字符串(保留字)
(1)类型说明符(定义,说明变量或其他结构的类型)
Int ,double
(2)语义定义符(表示一个语句的功能)
If------else
(3)预处理命令字(表示一个预处理命令)
Include
命名规范
Windows 下:大小写混排:NumberofBlank
这里主要介绍的是Linux 下的命名规则:
(1)变量名具有一定的意义,比如number_of_blank
(2)不建议用大小写混排,一般用小写字母,数字,下划线组成
(3)尽量 避免使用全局变量
面试题精选与实例分析:(有图有真相~~~~)
看程序写结果
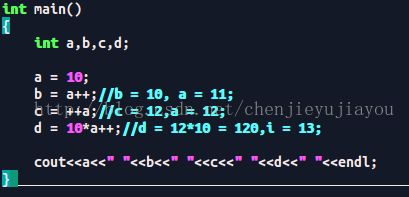
结果:

程序分析:
b = a++; b = 10; 然后a++,------->a = 11,b = 10
c=++a;先++a,a = 12,c = a, c = 12;-------->a = 12, c = 12
d = 10*a++ 因为++运算符只对单个变量有用:所以d = 10*(a++)----->d =120 a = 13
最后结果:a = 13, b = 10, c = 12, d = 120
请你写出两种方法实现两个变量的交换:
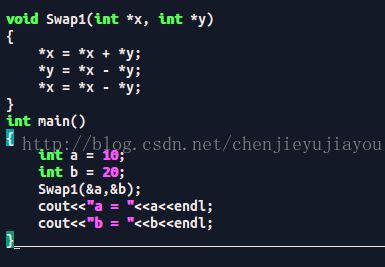
结果验证:

2.
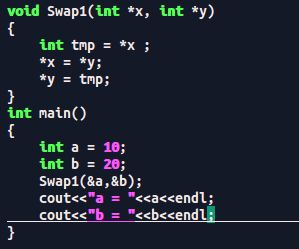
结果验证:
下列哪些变量是合法的?
3a, tmp1, float, _var c#
第一个:以数字开头不合法
第三个:关键字
第五个:非法字符
只有tmp1, _var合法
下面哪一个是合法字符常量
“a” ‘\n’ ‘china’ a
“a”:字符串(不合法)
‘\n’:转义字符(合法)表示换行
‘china’既不是 字符常量,也不是字符串常量
a: 不是字符常量 ‘a’才表示一个字符
3.设变量a的初始值为3,变量a的值是多少?
a+=a-=a*a;
分析:
赋值运算符的结合性是从右到左的,先计算a*a = 9,a-=9 a = 3-9=-6, a+=(-6) a = -6+(-6) = -12
J--也相当与赋值语句
———————————————————————————————————————————————————————————————————————
C程序控制结构和gcc编译器
语句:
(1)空语句:只有一个; 什么也不做
(2)表达式语句 一个表达式加上一个; i+j; 这也是一个合法的表达式
(3)复合语句 :被称为块,是用一对大括号括起来的语句集合,块同时也标识了一块作用域,在一个块中定义的变量只能在该块的内部使用。
(4)函数调用语句:由一个函数和一个分号构成
(5)控制语句:
If........else.......;条件语句
Switch多分支选择语句
for() 循环语句
while() 循环语句
do....while() 循环语句
Continue 结束本次循环
break; 结束整个循环或者结束switch语句
return 函数调用返回语句
goto 转向语句
分支控制结构
关系运算符
< <= > >= == !=
前四种优先级相同,后两种 优先级相同,前四种的优先级大于后两种
赋值运算符<关系运算符<算术运算符

逻辑运算符
(1)&&:逻辑与(双目)
(2)||逻辑或(双目)
(3)!逻辑非(单目)
只要是非0的数,都认为是真
逻辑与和逻辑或运算符都存在“懒惰求值”规则
对于逻辑与:如果第一个运算量的值为假,则这个逻辑表达式的值就为假,就不需要求第二个表达式的值
对于逻辑或运算:如果第一个表达式为真,则这个逻辑表达式的值就为真,就不需要再求第二个表达式的值

K的值为1,因为赋值运算符 的优先级仅低于逗号运算符 ,所以先计算i||(j == 1) 这一部分计算的值为1,所以最后把1的值赋给k
if 语句
else 总是与他们最接近的if配对
例1:输入三个数,按照从小到大的顺序输出
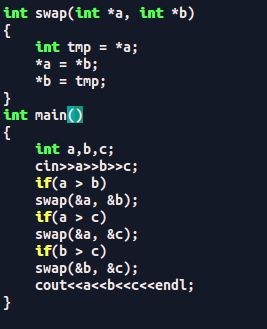
条件运算符
a>b?a:b;
三目运算符
如果第一个表达式的值为真,则第二个表达式是整个表达式的值,否则第三个表达式是整个表达式的值
条件表达式同样也遵守前面所说的“懒惰求值”
当第一个表达式为真时,就直接计算第二个表达式的值,并把它的值作为整个表达式的值,就不会去计算表达式三的值,同样,如果第一个表达式为假,直接执行第三个表达式的值,不计算第二个表达式的值。
switch语句
Switch 表达式所计算的结果必须为整型,常量表达式也必须为整型,而且不能为变量
下面列举一些错误用法(~~~~~~~~~~~~~~~~~~~~~~~~)



循环控制结构
1.while
求 1-100的和
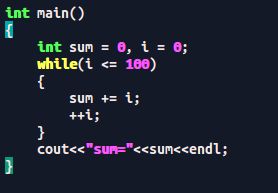
如果循环体包括一句以上的语句就用{}包起来,否则循环体只是进跟着while的第一个语句。
2.do...while
do
{
}while(); 先执行一次循环体,然后再进行判断,最少执行一次循环体
while: 先判断,再执行
do while: 先执行,后判断
3.for(表达式1;表达式2 ;表达式3)
表达式1:给循环变量赋初值
表达式二:设置循环结束的条件
表达式三:修改循环变量的值
表达式一只执行一次
4.break :从循环体中跳出
continue:结束本次循环
计算1~10的阶乘

-----------------------------------------------------------------------------------------------------------------------------
程序的编译过程:
| 预处理 |
gcc -E test.c -o test.i test.i称为中间文件 |
| 编译 |
gcc -S test.i -o test.s test.s称为汇编语言文件 |
| 汇编 |
gcc -o test.s -o test.o test.o称为可执行的二进制文件 |
| 链接 |
gcc test.o -o test test 称为可执行文件 |
以上部分可以只用一句话:gcc -o test test.c 就可以完成
./test 执行
gcc 基本用法
Gcc [options][filename]
| -c |
只编译,不链接成可执行文件,编译器只是由输入的.c为后缀的源代码文件生成.o为后缀的目标文件,通常用于编译不包含主程序的子程序文件 |
| -o output_filename |
确定输出文件的名称 |
| -g |
产生gdb调试信息 |
| -O |
优化编译,链接 |
| -O2 |
更好的优化编译,链接 |
| -Wall |
输出所有警告信息 |
| -w |
关闭所有的警告 |
| -Idirname |
将名为dirname的目录加入到程序头文件目录列表中,是在预处理阶段使用的选项I 表示include |
| _Ldirname |
将名为dirname的目录加入到程序头文件目录列表中,是在链接阶段使用的选项L 表示Link |
实例精讲
1. 日本某一地方发生了一起谋杀案,警察通过排查确定杀人凶手为4个嫌疑犯中的一个
A说: 不是我
B说:是C
C说:是D
D说:C在说谎
思路:将四个人所说的供词转换为逻辑表达式
| 不是A |
Killer !=’A’ |
| 是C |
Killer == ‘C’ |
| 是D |
Killer == ‘D’ |
| C说谎 |
Killer!=’D’ |

结果验证:
![]()
1. 猜数字游戏
计算机随机产生一个1~100之间的数,让用户来猜,如果猜对了给出提示信息,“Wonderful, you are right”如果猜错了就提示“sorry ,you are wrong”,并告诉用户too high 或者too low,最多只能猜8次

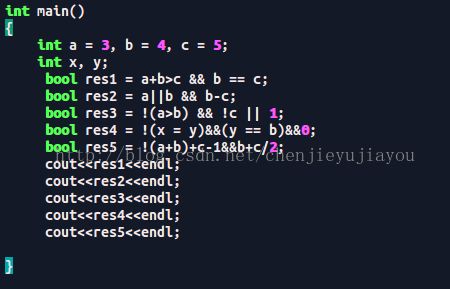
1. 计算下列逻辑表达式的值
a = 3, b = 4, c = 5
(1)a+b>c && b == c
(2)a||b && b-c
(3)!(a > b) && !c||1
(4)!(x = a) && (y == b)&& 0
(5)!(a+b)+c-1&&b+c/2
算数运算符>关系运算符>逻辑运算符>赋值运算符
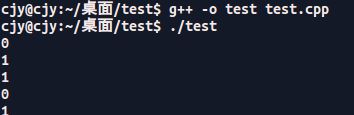
(1)=0
(2)=1
(3)=1
(4)=0
(5)=1
验证一下:
2.用逻辑表达式,for 循环来求解逻辑题,5位运动员参加了10米台跳水比赛,有人让他们预测比赛结果
A说:B第一,我第三 ‘B’ 第一 或者 ‘C’ 第三
B选手 说:我第二,E第四 ‘ B’第二 或者 ‘E’第四
C选手说:我第一,D第二 ‘C’第三 或者‘D’ 第二
D选手说:C最后,我第三 ‘C’ 第五 或者‘D’第三
E选手说:我第四,A第一 ‘E’第四 或者 A第一
比赛结束后,每位选手都只说对了一半,请编程确定比赛名次
using namespace std;
int main()
{
int A = 1,B =1, C = 1, D = 1, E = 1;
for(A=1; A<=5; ++A)
{
for(B=1; B<=5; ++B)
{
for(C=1; C<=5; ++C)
{
for(D=1; D<=5; ++D)
{
for(E=1; E<=5; ++E)
{
if( ((B==1)+(A==3) == 1) && ((B==2)+(E==4) == 1) && ((C==1)+(D==2) == 1) && ((C==5)+(D==3)==1) && ((E==4)+(A==1) == 1) )
{
int ret = 0;
ret |= (1<<(A-1));
ret |= (1<<(B-1));
ret |= (1<<(C-1));
ret |= (1<<(D-1));
ret |= (1<<(E-1));
while(ret)
{
if(ret%2 == 0)
{
break;
}
ret/=2;
}
if(ret == 0)
{
cout<<"A是第"<结果验证:
![]()
2.用穷举法求爱因斯坦数学题,有一条长阶梯,若每部跨两阶,最后剩一阶,若每步跨3阶,最后剩2阶,若每步跨5阶,最后剩4阶,若每步跨6阶,最后剩5阶,若每步跨7阶,最后一阶都不剩,请问这条台阶共有多少阶?
假设有n阶,n%2 == 1;
n%3 == 2
n%5 == 4;
n%6 == 5
n%7 == 0;

