所谓表白神器,就是输入一段想说的话,自动输出一张图片,图片上有一帮卡通人物举着对应的纸牌,有应援的感觉,哈哈。

其实这个神器的核心方法早在2016年底完成,可是心头大石一放下,人就懒了,项目丢一边,拖到最近才将其彻底完成,并修复了一些BUG。
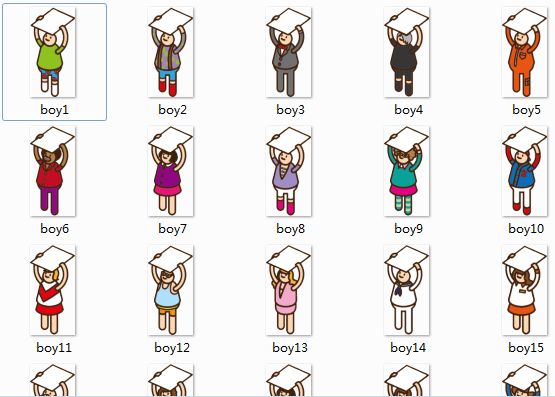
当初是在微信公众号上看到这个好玩的东西,然后萌生模仿的念头。不多想,撸起袖子就干。看着应该挺容易,先从网站上取得小人的素材,由于小人之间有重叠,还得用PS抠图,最后素材如下,共24个小人。
然后嘛,就是绘制字符,变形,再绘制到小人的纸牌上,最终逐个小人绘制到图片上。
源码在这,代码不多:http://git.oschina.net/terran13/placardboys
main方法在org/pb/core/ImagePainter.java里
变形,AffineTransform
第一次做2D图形变形,不懂啊就寻求搜索引擎,找到AffineTransform,一查词条,高大上的名词映入眼帘——2D 仿射变换。引用百度百科的解释“可以使用一系列平移 (translation)、缩放 (scale)、翻转 (flip)、旋转 (rotation) 和错切 (shear) 来构造仿射变换”。然后就是看不懂的类似矩阵的等式,崩溃。
于是寻求JDK文档和源码,翻开java.awt.geom.AffineTransform,依然没有实质的帮助,都是高大上的晦涩名词和矩阵。再看这个类的方法:
- rotate(double theta) 旋转
- scale(double sx, double sy) 缩放
- translate(double tx, double ty) 平移
- shear(double shx, double shy) 错切
功能是懂,让图形(字符图形)旋转就用rotate方法,参数theta自然是旋转角度。让图形倾斜就用shear方法,但参数代表什么?不懂。后来在维基百科看到一张图,瞬间廓然开朗。
失误的开始
维基百科上的图是这样的:
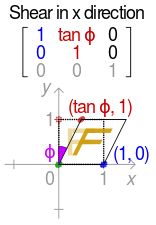
矩形(边长为1)左下角固定在笛卡尔坐标原点时,错切时(倾斜变形),左上角(红点)的坐标由原来的(0,1)变成(tan Φ,1),那么shear方法的参数应该就是矩形左上角的新坐标了。于是风风火火写试验代码,但是结果让人懵逼。
试验代码如下:
// btest.png是背景图,带有灰色线格作为参照,一格10x10像素
Image img = fileAccessor.getFileImage("image/btest.png");
int imgW = img.getWidth(null);
int imgH = img.getHeight(null);
BufferedImage mainImg = new BufferedImage(imgW,imgH,BufferedImage.TYPE_INT_ARGB);
Graphics2D boyG = mainImg.createGraphics();
//绘制背景图
boyG.drawImage(img, 0, 0, imgW, imgH, null);
//在x=10,y=10的位置绘制20x30的绿色矩形
AffineTransform at = new AffineTransform();
at.translate(10, 10);
boyG.setTransform(at);
boyG.setPaint(Color.green);
boyG.drawRect(0, 0, 20, 30);
//同上,但这个错切30度(sheer)
AffineTransform at1 = new AffineTransform();
at1.translate(40, 10);
at1.shear(Math.tan(Math.toRadians(30)), 1);
boyG.setTransform(at1);
boyG.setPaint(Color.red);
boyG.drawRect(0, 0, 20, 30);
boyG.dispose();
//保存图片到磁盘
fileAccessor.saveImageToFile(mainImg, "test.png");
效果图,一个灰格是10x10像素。(为了看清楚,图放大了几倍,所以有断点和锯齿,100%的时候几乎看不出)

试验代码的效果图跟维基百科的图完全不一样,而且差别也很离谱,不是任意方向的倾斜变形,而是拉伸变形,为什么?我看着维基百科的图想啊想,最后看着矩形右下角(蓝点)的坐标(1,0)为什么要用蓝色标出来呢?而且在矩阵里似乎地位挺重要。莫非shear方法的第二个参数不是左上角的y坐标,而是右下角的y坐标?
因为矩形倾斜变形时(左下角固定在笛卡尔坐标原点),左上角a的y坐标都是不会变的,永远是1,如果y变化,就不是倾斜,而是拉伸。右下角b刚好相反,倾斜变形时,x不会变,x变的话,则是拉伸。
修改一下代码试试,shear方法的第二个参数改为0,即矩形右下角b的y坐标,效果图显示,却依然错误,但接近了:
at1.shear(Math.tan(Math.toRadians(30)), 0);
此图附上笛卡尔坐标,o为原点,看到错切后,左上角a依然是(0,1),左下角c却变成(tan 30°,0),跟shear方法参数的表述有出入,到底发生什么事?
这是因为,以上的推测,都是基于维基百科的笛卡尔坐标,矩形左下角是笛卡尔坐标的原点o。但是,在Java里则完全不一样,Java绘制一个图形,基准点是在左上角,也即a,而不是o,所以不能参照维基百科的笛卡尔坐标图。
回归正道
重新给上面那张图画上Java绘图环境下的笛卡尔坐标(注意x轴y轴方向,第四象限都是正数坐标,一般情况下向第四象限区域绘图):

那么,此时再看错切后的图型,结果跟代码一致,c的x坐标是tan 30度,d的y坐标是0。
at1.shear(Math.tan( Math.toRadians(30)) , 0 );
结论也就出来了,shear方法的第一个参数就是a点错切后(变为c)的x坐标,第二个参数就是b点错切后(变为d)的y坐标。而矩形的哪个点视为a哪个点视为b,主要看笛卡尔坐标原点在哪。在java中,绘图的基准点在左上角o,那么这个点就是笛卡尔坐标原点,a和b就分别是x轴方向的点和y轴方向的点,如上图。
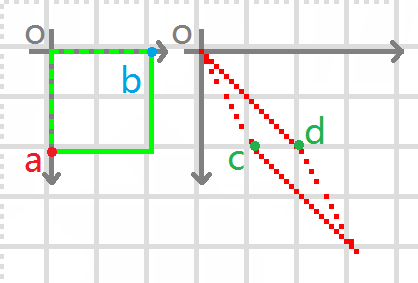
再回顾前面那一个让人懵逼的错切代码:
at1.shear(Math.tan(Math.toRadians(30)), 1);效果图,套上正确的笛卡尔坐标就对了,c的x坐标是tan 30度,d的y坐标是1:
如果要达到向左倾斜的实际需求呢,很简单:
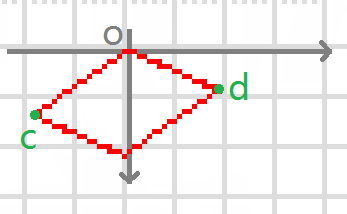
at1.shear(-Math.tan(Math.toRadians(30)), 0);c的x坐标是负tan 30度,d的y坐标是0:

再加上翻转代码,绕着o点顺时针转24度:
at1.rotate(Math.toRadians(24));
at1.shear(-Math.tan(Math.toRadians(30)), 0);最终效果如下,其形状已经跟小人儿高举的牌子形状契合,把绘制矩形换成绘制字符,一样的道理。
绘制字符
为什么把这一章放在AffineTransform之后,因为绘制字符跟绘制矩形有点不同,要借助AffineTransform验证一些潜藏的问题。
打印或绘制字符有个坑,叫“字符基线”,无论是英文字母还是中文,不认识“字符基线”的存在,打印或绘制时,错误的位置会让人找不到原因而崩溃。
字符基线
先看下面代码,在画布的0,0位置绘制30像素大小的字符串。
// btest.png是背景图,带有灰色线格作为参照,一格10x10像素
Image img = fileAccessor.getFileImage("image/btest.png");
int imgW = img.getWidth(null);
int imgH = img.getHeight(null);
BufferedImage mainImg = new BufferedImage(imgW,imgH,BufferedImage.TYPE_INT_ARGB);
Graphics2D boyG = mainImg.createGraphics();
//绘制背景图
boyG.drawImage(img, 0, 0, imgW, imgH, null);
//绘制字符串
int fontSize = 30;
Font font = new Font("微软雅黑",Font.PLAIN, fontSize);
boyG.setFont(font);
boyG.setColor(Color.RED);
boyG.drawString("apple 苹果", 0, 0);
boyG.dispose();
//保存图片到磁盘
fileAccessor.saveImageToFile(mainImg, "test.png");
结果如下:

WTF?很明显绘制位置出了问题,但明明设了x=0,y=0啊。看文档,drawString方法第二第三参数的描述“最左侧字符的基线位于此图形上下文坐标系统的 (x, y) 位置处”,果然之前理解错了该方法。
原来是最左侧字符(即字符a)的“字符基线”坐标,不是类似于绘制矩形的左上角坐标,改成如下:
boyG.drawString("apple 苹果", 0, fontSize);
蓝色线就是“字符基线”了,其位置在30像素处,同时可以看到,部分字母和中文字的底部,超出了30像素。
此时有问题要提出
- 字体大小为30,可其显示范围包括空白区域,即不可见的矩形(我称为“字符空间”)似乎超出了30像素。
- 字体大小为30,指的是哪里的30?“字符空间”的高度?还是“字符基线”到“字符空间”顶部的距离?
- “字符空间”到底是指哪个区域?
要搞清楚一个字符准确的“字符空间”,是为了在字符进行错切、旋转或平移时,准确算出最终绘制的坐标位置。一切的变形操作,实则是操作这个“字符空间”,是个隐形的矩形。
字符空间(我发明的名词)
就是一个字符显示的范围,包括边缘的空白位置,看前一节的图可以推测,大小为30的英文字母的“字符空间”宽小于30,高大于30;大小为30的中文,其“字符空间”的宽等于30,高大于30。也可以推测,其左上角(o点)位于(0,0)处。为了验证,可以利用AffineTransform的translate方法平移一下字符,在(20,10)位置绘制字符:

此时o点正好在(20,10),基本可以确定“字符空间”的左边界和上边界(右边界不重要,而下边界也可以忽略,都画出来只是参考),这就回答刚才提出的问题:字体大小为30,指的是“字符基线”到“字符空间”顶部的距离,不管英文还是中文,一样。“字符空间”宽度,英文因应字符的宽而变化,例如“l”的就比“a”的窄,而中文都是30。
错切一下:

那么现在最终确定了“字符空间”,也就是一个矩形,对字符的变形和平移操作也将得心应手。
可能此时你会受不了字体的锯齿,的确啊,即使原图恢复到100%,经过错切和旋转的字体,锯齿依然很严重,影响美观,还好Java绘图支持“去锯齿”,或叫羽化,一行代码搞定:
boyG.setRenderingHint(RenderingHints.KEY_TEXT_ANTIALIASING,RenderingHints.VALUE_TEXT_ANTIALIAS_ON);
边缘被羽化了,放大图锯齿改善不明显,但是如果恢复到100%,效果十分赞,舒服得多。最后贴出上面例子的完整代码:
Image img = fileAccessor.getFileImage("image/btest.png");
int imgW = img.getWidth(null);
int imgH = img.getHeight(null);
BufferedImage mainImg = new BufferedImage(imgW,imgH,BufferedImage.TYPE_INT_ARGB);
Graphics2D boyG = mainImg.createGraphics();
boyG.drawImage(img, 0, 0, imgW, imgH, null);
AffineTransform at1 = new AffineTransform();
at1.translate(20, 10);
at1.shear(-Math.tan(Math.toRadians(30)), 0);
int fontSize = 30;
Font font = new Font("微软雅黑",Font.PLAIN, fontSize);
boyG.setFont(font);
boyG.setColor(Color.RED);
boyG.setBackground(Color.yellow);
boyG.setTransform(at1);
boyG.setRenderingHint(RenderingHints.KEY_TEXT_ANTIALIASING,RenderingHints.VALUE_TEXT_ANTIALIAS_ON); //字体边缘模糊(羽化)
boyG.drawString("apple 苹果", 0, fontSize);
boyG.dispose();
fileAccessor.saveImageToFile(mainImg, "test.png");
把字符绘制到小人素材上
在此之前先说说此表白神器的配置文件PlacardBoys.properties的这些配置是什么意思:
- placardRotateDegree,牌子(字符)旋转的角度,对应下图中的α角。
- placardShearInnerDegree,牌子的内角,对应下图中的β角。90度减β等于字符shear的角度。
- placardCenterX和placardCenterY,牌子中心在素材中的x,y坐标。
- fontSize,字符的大小
- fontBottomMargin,用于微调字符位置,因为“字符基线”的原因。

字符要正确绘制到牌子上,字符中心和牌子中心必须重合。如果知道了fontSize,牌子中心的坐标,就能算出字符插入的位置(“字符空间”左上角的位置)。看图比较好理解,完完全全只是三角函数,不难。
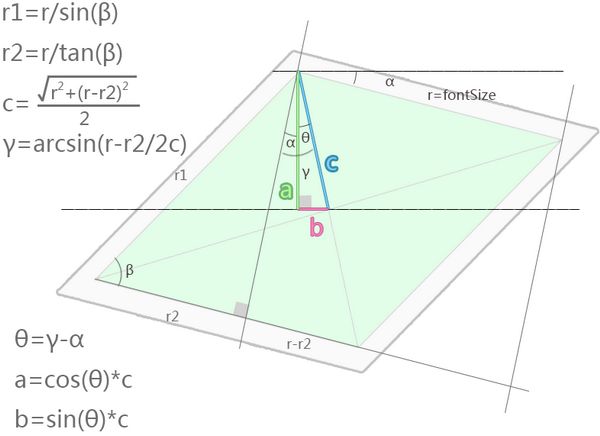
白色是素材的牌子,浅绿色是shear后的字符空间主要部分(下边界是“字符基线”),两者中心点重合。r是字符大小(回顾之前说的,fontSize等于“字符基线”到“字符空间”顶部的距离)。最后计算出a、b的值,那么placardCenterX – b就是字符插入素材的坐标x,placardCenterY – a就是字符插入素材的坐标y。
第一次做这个算法时,犯了严重的错误。我读高中时好歹是级里的几何大师,以往的高考物理光学大题必会做,而且是班里唯一一个,可是隔了这么多年没接触几何,说翻车就翻车。而且更离奇的是,错误的算法,结果的差距却很小很小,根本看不出来x,y算错。这很危险,世上有很多灾难就是因为不易察觉的微小错误引发的。所以作为工程师,无论是写代码的,还是造火箭的,必须要有严谨的态度。
以下是完整的计算方法(而错误方法我依然保留在源码里,时刻提醒自己):
private void calculateCharInitXY2(double placardCenterX,
double placardCenterY,
double placardRotateDegree,
double placardShearDegree,
int fontSize){
double r2 = fontSize/Math.tan(Math.toRadians(placardShearDegree));
double t = fontSize - r2;
double c = Math.sqrt((fontSize*fontSize)+t*t)/2;
double gama = Math.toDegrees(Math.asin(t/(2*c)));
double theta = gama - placardRotateDegree;
double a = Math.cos(Math.toRadians(theta))*c;
double b = Math.sin(Math.toRadians(theta))*c;
//算出了x和y(rounding方法是四舍五入)
this.x = placardCenterX - rounding(b);
this.y = placardCenterY - rounding(a);
}
之后绘制字符时,就平移到该(x,y)坐标,旋转,错切:
AffineTransform at = new AffineTransform();
at.translate(x, y);
at.rotate(Math.toRadians(placardRotateDegree));
at.shear(-Math.tan(Math.toRadians(90-placardShearInnerDegree)), 0);
最终效果:

会发现,为什么字符位置还会靠下啊。因为计算x,y时是以“字符基线”作为下边界,而字符的某些部分会超过下边界,所以字符就靠下。于是就利用fontBottomMargin参数值微调,把“字符基线”往上调高。drawString方法第三参数由原来的fontSize再减fontBottomMargin即可。
boyG.drawString(character, 0, fontSize - fontBottomMargin);微调后的效果:

回顾前一章说到,英文字母的字符空间宽度比中文字符空间的宽度窄,而且还是动态变化的,为了兼容,无论输入英文还是中文字符,一律以中文的字符空间的宽度计算。所以这就有点不足,当绘制英文字符时,位置会偏左。
绘制所有小人
小人站哪里?
再说说配置文件PlacardBoys.properties的其他配置是什么意思:
- boyImgWidth和boyImgHeight,小人素材的宽和高
- placardLeftTopCornerX,牌子左上角的x坐标,用于计算下一张牌子的位置
- placardLeftBottomCornerY,牌子左下角的y坐标,用于计算下一行牌子的位置
- placardHorizontalDistance和placardVerticalDistance,牌子之间上下的距离和左右的距离
- maxChar,最大的输入字符数
- rowLength,一行有多少个字符
- outputName,结果(图片)的输出位置
- margin,边距
第一个小人的绘制位置是已知的,随便在哪个位置都可以,而下一个小人的位置,及下一行第一个小人的位置,可以根据以上提供的参数计算出来。看图理解计算过程,依然是三角函数游戏,灰色是牌子:
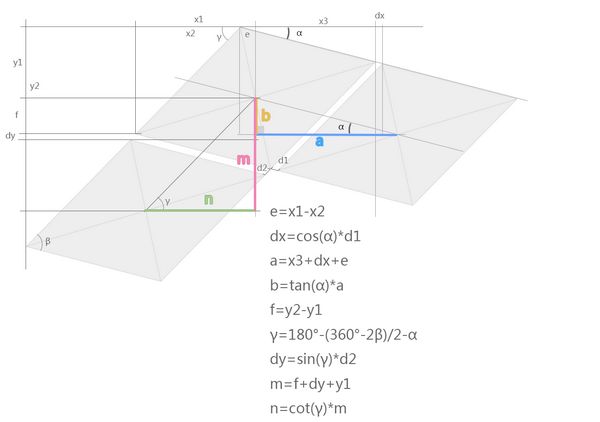
结果a,是下一个小人对于前一个小人的x增量
结果b,是下一个小人对于前一个小人的y增量
结果n,是下一行第一个小人的x增量
结果m,是下一行第一个小人的y增量
以下是完整的计算方法代码:
private void calculateBoyPositionIncrement(){
//从PlacardBoys.properties取得配置值
double afa = config.getPlacardRotateDegree();
double beta = config.getPlacardShearInnerDegree();
double d1 = config.getPlacardHorizontalDistance();
double d2 = config.getPlacardVerticalDistance();
double x1 = config.getPlacardCenterX();
double y1 = config.getPlacardCenterY();
double x2 = config.getPlacardLeftTopCornerX();
double y2 = config.getPlacardLeftBottomCornerY();
double x3 = config.getBoyImgWidth() - x1;
double e = x1 - x2;
double dx = Math.cos(Math.toRadians(afa))*d1;
double a = x3 + dx + e;
//下一个小人的位置
this.nextPlacardIncrementX = rounding(a);
this.nextPlacardIncrementY = rounding(Math.tan(Math.toRadians(afa))*a);
double f = y2 - y1;
double gama = 180 - ((360-2*beta)/2) - afa;
double dy = Math.sin(Math.toRadians(gama)) * d2;
double m = f + dy + y1;
//下一行第一个小人的位置
this.nextLinePlacardIncrementX = rounding(m/Math.tan(Math.toRadians(gama)));
this.nextLinePlacardIncrementY = rounding(m);
}
所以,小人要站哪里,得看前一个小人。如果小人是站行首的,得看上一行第一个小人。
如果只是这样简单的排,会出现一个小问题,假如英文单词太长,它会“断开”,单词的后半部分丢到第二行,如图:

当然你也可以觉得不是问题,不同的人不同喜好罢了。
小人如何站?
要解决这种单词“断开”的情况,在发现剩余位置不够单词使用时,换行即可。所以首先要做的,是对整个字符串进行分词。如果是字符串“I love china”,则分成i、空格、love、空格和china这5组,每组是一个单词或空格。然后依次插入到一个二维数组a[][]里,每个a元素代表一个字符显示的位置。例如a[0][0]就是第一行第一个字符,a[1][2]就是第二行第三个字符。
此过程中,每轮到一个单词,就检查单词是否大于行长度,且剩余的位置是否足够使用,我第一次写的算法,处理这三种情况。
第一种情况,单词比较短,剩余位置够用,就不换行。
第二种情况,单词比较长,但不长过行的长度,剩余位置不够,就换行。例如轮到china时,剩余行只有一个位置,不够china这个单词使用,就换行,将c放到a[1][0],h放到a[1][1],如此类推,得到下图的效果:

第三种情况,单词十分长,长过行的长度,就索性不换行了。这也是为了兼容中文句式,中文句式没有空格:

可是后来发现了第二情况的极端情况,就是极短单词跟标点符号的字符串,原算法把标点符号的前和后当一个整体处理,且这个整体又刚好不超过行长度,就造成了显示不均衡的情况。虽然可以通过增加行长度(PlacardBoys.properties的rowLength属性)来减少这种情况的发生。

后来我改进分词算法,不只是分空格,连标点呼号都分。算法完整代码如下:
private String[] splitWord(String text){
text = text.trim();
//标点符号只加了逗号和句号,还可以添加其他标点符号
Pattern p = Pattern.compile(",| |\\.|,|。");
StringBuilder tempWord = new StringBuilder();
List tempResult = new ArrayList();
for(int i = 0;i< text.length();i++){
char c = text.charAt(i);
String s = String.valueOf(c);
if((p.matcher(s)).matches()){
tempResult.add(tempWord.toString());
tempResult.add(s);
tempWord.delete(0, tempWord.length());
}else{
tempWord.append(s);
}
}
if(tempWord.length()>0){
tempResult.add(tempWord.toString());
}
System.out.println(tempResult);
String[] sa = new String[tempResult.size()];
sa = tempResult.toArray(sa);
return sa;
}
如果字符串是“oh no,她要分手”,此方法返回的数组是
- sa[0] = oh
- sa[1] = 空格
- sa[2] = no
- sa[3] = 逗号
- sa[4] = 她要分手
标点符号的前和后不再被当一个整体进行处理。
换行条件也加了一个,新加的条件就是前一个单词是空格时,才换行。
//词长度小于行长度,且词长度大于行剩余空间,且前一个词是空格,换行
if(wordLength < rowLength && wordLength > rowLength - used && " ".equals(preWord)){
used = 0; //已用位置清0
rowNumber++; //二维数组的行号
}
最终结果:

完
至此,表白神器关键的地方都说完了。其余细节,看源码。
最后要声明的是,本人没有这些素材的版权,仅作演示用,不提供下载。如果你有自己的素材,依然可以用我这个表白神器,它高度可配置,参照PlacardBoys.properties各属性的描述填写素材各项参数即可。(不过我不保证100%通用,因为我没试过套用其他素材,99%通用应该还是有的,哈哈)
感觉这个程序还有优化的空间,例如我没有做素材缓存,I/O太多。又例如用户使用自己的素材时,要提供太多素材参数,不知道可不可以减少几个。