TensorFlow tf.keras.layers.RNN
参数
| 参数 | 描述 |
|---|---|
| cell | |
| input_shape | (timestep, input_dim),timestep可以设置为None,由输入决定,input_dime根据具体情况 |
| return_sequences | 返回最后序列最后一个词,或者所有词 |
| return_state | |
| go_backwards | |
| stateful | |
| unroll | |
| time_major |
输入形状
n维的张量(batch_size, timesteps, input_dim)
例如:
1.100个句子,每个句子20个词,每个词80维度的向量,那么形状就是(100,20,80)
2.如果是简单的时间序列,则input_dime为1,也就是说该step的值就是它的特征
一个两个步长的序列表示为:[[1],[2]]
输出形状
return_sequences:
False:(batch_size, output_size)
True:(batch_size, timesteps, output_size)
init
__init__(
cell,
return_sequences=False,
return_state=False,
go_backwards=False,
stateful=False,
unroll=False,
time_major=False,
**kwargs
)
理论
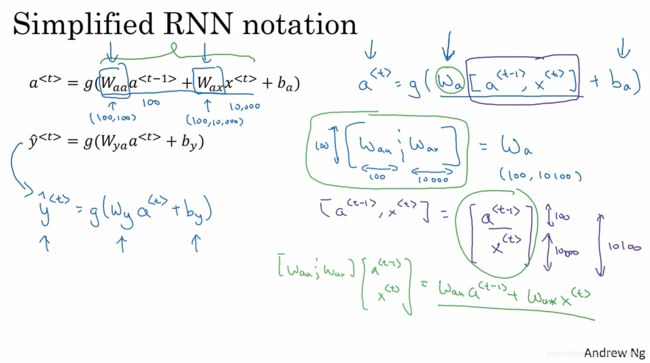
W a a W_{aa} Waa是指上一个时间步的权重矩阵,形状是( c e l l ∗ c e l l cell*cell cell∗cell),就是该循环层的隐藏单元(输入是上一时间步的输出cell,输出是这一个时间步的cell);
W a x W_{ax} Wax是这个时间步特征的权重矩阵(和全连接层相同),形状是( f e a t u r e s ∗ c e l l features*cell features∗cell).features是上一层的输入,比如一句话中一个单词的词向量维度, c e l l cell cell是本层的隐藏单元
b a b_a ba是偏置量,形状是( c e l l cell cell),有多少个隐藏单元就有多少个偏置量
所以权重的个数计算是(特征权重+上一个时间步输出权重+偏置量)
c e l l ∗ f e a t u r e s + c e l l ∗ c e l l + c e l l cell*features+cell*cell+cell cell∗features+cell∗cell+cell
当然这个公式也可以简化为( w a [ a < t − 1 > , x < t > ] + b a w_a[a^{<t-1>},x^{<t>}]+b_a wa[a<t−1>,x<t>]+ba):
c e l l ∗ ( f e a t u r e s + c e l l ) + c e l l cell*(features+cell)+cell cell∗(features+cell)+cell
参考:
官网
LSTM神经网络输入输出究竟是怎样的?
如何理解lstm的输入输出
完全解析RNN, Seq2Seq, Attention注意力机制
循环神经网络RNN打开手册