Numpy & Pandas入门
Numpy & Pandas入门
- Numpy & Pandas入门
- 安装
- numpy
- 基础运算1
- array()
- 属性
- 指定数据类型
- 创建全零矩阵
- 创建全1矩阵
- 创建全空矩阵
- arange()
- reshape改变数据的形状
- linspace创建等差数列
- 基础运算2
- 乘法:
- axis参数
- 最小元素索引与最大元素索引
- 累加函数
- 累差函数
- nonzero()
- sort()
- 转置
- newaxis()
- 换轴心transpose()
- clip()
- 索引
- 一维索引
- 二维索引
- flatten
- flat
- 合并矩阵
- np.vstack((A, B))
- np.hstack((A, B))
- concatenate()
- 分割矩阵
- vsplit()
- hsplit()
- array_split() 不等量分割矩阵
- copy & deep copy
- 赋值“=”
- copy
- NaN
- 切片
- 张量
- random
- 基础运算1
- Pandas
- Series
- DataFrame
- 选择数据
- 简单筛选:
- 根据标签:loc
- 根据序列:iloc
- 序列与标签的混合:ix
- 根据判断来筛选
- 设置值
- 根据索引或者标签改变值:
- 根据条件来设置:
- 按行、列设置
- 添加数据
- 处理丢失数据
- 去掉NaN
- 用其他值填补NaN
- isnull()
- isna()
- 数据导入导出
- 数据合并 concat
- axis方向
- 重置index:
- join
- join_axes
- append
- 合并 merge
- 依据一组key合并
- 依据两组key合并。
- Indicator
- 依据index合并。
- 画图
- plot
- 散点图 plot.scatter
学习莫烦PYHTHON的简单学习笔记
安装
pycharm –> preference –> project Interpreter –> 左下角的加号 –> 弹出搜索框搜索 –> install Package
所有第三方模块的安装都可以通过这种办法。
版本是pycharm 2018.1.1
numpy
基础运算1
array()
将传入的参数转化为矩阵
A = np.array([[1,2,3],[5,6,7]])
属性
print(A.ndim) #维度
print(A.shape) #行数, 列数
print(A.size) #元素个数
指定数据类型
A = np.array([[1,2,3],[5,6,7]], dtype=int)
numpy有很多数据类型,可以在此指定。
创建全零矩阵
a = np.zeros((3, 4))
创建全1矩阵
a = np.ones((3, 4))
创建全空矩阵
a = np.empty((5, 6))
其中的元素都是接近于0的数。
arange()
创建连续数组,可指定步长
reshape改变数据的形状
https://blog.csdn.net/xiaoqinting2015/article/details/69936952
如果shape参数的最后边是0,代表可以自动推测出该数值大小。
np.reshape(a,(2, -1))
linspace创建等差数列
print(np.linspace(0,10,5))
基础运算2
乘法:
a * b 点乘
numpy.dot(a, b)矩阵乘法
a.dot(b)矩阵乘法
b**2b矩阵各个元素的平方,双星符号
axis参数
在sum()、min()、max()中,参数axis:
axis = 0:按列查找
axis = 1:按行查找
最小元素索引与最大元素索引
print(np.argmin(A))
print(np.argmax(A)) 这个索引是从第一个元素开始,按照行排序,如下所示:
0 1 2 3
4 5 6 7[[ 2 3 4 5]
[ 6 7 8 9]
[10 11 12 13]]所以这个矩阵的输出结果是:
0
11但是还有一套索引,分为一维索引和多维索引。见下。
累加函数
a.cumsum()
numpy.cumsum(a)
原矩阵首项加到对应项的元素之和。
是一个行向量,元素个数与原矩阵元素个数相同。
累差函数
每一行,后一项与前一项之差。
比原矩阵少一列。
numpy.diff(a)
nonzero()
B = np.nonzero(A)
将矩阵A的所有非零元素提出来,将这些非零元素的行坐标作为一个行向量,非零元素的列坐标作为第二个行向量。
(array([0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2]), array([0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3]))
#前一个是行,后一个是列sort()
对矩阵按行排序。
也就是对每一行进行排序。行与行之间不排序。
np.sort(A)
转置
两种转置:
np.transpose(A)
A.transpose()
A.T
A.T不支持一维数组的转置。
np.transpose(A)也不支持,因为一维数组就一个轴。
四种一维数组转置的办法:
#一种一维矩阵的转置方法
#不懂这种玩法
D = np.arange
print(D)
F = np.transpose([D]) # []
print(F) #reshape转置一维向量
A = np.array([1,2,3])
print(A.reshape(len(A), -1)) A = np.array([1,2,3])
print(A[:, None]) 第二种、第三种、第四种办法(下边的newaxis)是给矩阵增加了一个轴。矩阵仍然是原来的那个矩阵,A和B仍然指向同一个地址。改变A,输出B,结果根据A的改变发生变化。
第一种办法复制了另一个矩阵出来。
A = np.array([1,2,3])
print(A.shape)
B = A[:, None]
print(B.shape) 输出:
(3,)
(3, 1)newaxis()
axis是轴心的意思。
对于一维向量。可以利用newaxis()完成转置。
D = np.arange(30, 10, -2)
print(D)
print(D[np.newaxis, :]) # 轴心不变,不转置
print(D[:, np.newaxis]) # 轴心变到另一个纬度,转置 换轴心transpose()
转置是换轴心的一种情况。
https://blog.csdn.net/u012762410/article/details/78912667
clip()
clip(Array,Array_min,Array_max)
把矩阵中比最小值小对元素变成最小值;比最大值大对变成最大值。剪掉了蛇的头和尾巴。剃头。
索引
下标都是从0开始的。
一维索引
对一维向量:
a[2]就是从左往右第三个元素。
对二维矩阵:
a[2]是第三行。
对三维矩阵:
…
二维索引
对二维矩阵:
二维索引定位到一个元素
可以利用切片
for循环是按行输出矩阵。
如果要按列输出矩阵,可以先将矩阵转置。
flatten
将矩阵展开成一个一维向量。
a.flatten()
flat
和flatten功能一样,但是flat是一个迭代器,需要的时候才迭代输出元素。
for item in A.flat
print(item) 输出:
2
3
4
5
6
7
8
9
10
11
12
13合并矩阵
np.vstack((A, B))
将两个矩阵上下合并。
np.vstack((A, B))
np.hstack((A, B))
将两个矩阵左右合并。
np.hstack((A, B))
concatenate()
合并矩阵
concatenate((A, B), axis = 0)
axis = 0 :上下合并;
axis = 1 :左右合并;
分割矩阵
np.split()
A = np.arange(2, 14).reshape((3, 4
print(np.split(A, 4, axis=1)) axis = 0 :横向分割
axis = 1 :纵向分割
中间的参数叫indices or sections,也就是分的块数。
只能等量分割。一个一行四列的矩阵不能纵向分割成三块。
vsplit()
np.vsplit(A, 3)
split的axis为0的情况。
hsplit()
np.hsplit(A, 2)
split的axis为1的情况。
array_split() 不等量分割矩阵
np.array_split()
A = np.arange(2, 14).reshape((3, 4))
print(np.array_split(A, 3, axis=1)) copy & deep copy
赋值“=”
所有变量指向一个地址。
copy
就是复制一个一模一样的矩阵出来。
NaN
not a number, 非数。
inf - inf 会引发NaN。
涉及到无穷大无穷小的运算有可能出现NaN。
有NaN参与的运算,也会引发NaN。
NaN == NaN 的结果是false。
切片
numpy 中的切片,不是复制一个子矩阵,而是将变量指向了同一片内存中的子矩阵部分。所以切片后原矩阵的相应位置发生变化,子矩阵也会变化。
而python的切片是一种浅拷贝。
张量
一维向量叫一阶张量。
二维矩阵叫二阶张量。
n维矩阵叫n阶张量。
random
https://www.jianshu.com/p/214798dd8f93
Pandas
两种数据结构:Series 和 DataFrame
Series
#pandas
p = pd.Series([1, 54, np.inf, np.nan])
print(p)
#numpy
n = np.array([1, 54, np.inf, np.nan])
print(n) 输出:
0 1.000000
1 54.000000
2 inf
3 NaN
dtype: float64
[ 1. 54. inf nan]和array相比,series有索引。
DataFrame
df = pd.DataFrame(np.random.randn(5,3), index = ['a', 'b', 'c', 'd', 'e'], columns=[1, 2, 3])
print(df) 输出:
1 2 3
a -0.575799 -0.199744 0.218526
b -1.953569 0.694882 -0.218284
c 0.264646 0.852670 -0.798378
d 1.457002 -0.940384 -0.707806
e 1.246967 0.732388 1.863687表格型数据结构。每一列存储的数据类型可以不同。
print(df[1]) 输出:
a 0.258160
b 0.680918
c -1.001002
d 2.985772
e -0.049686
Name: 1, dtype: float64创建不给定行标签和列标签的DataFrame。
df1 = pd.DataFrame(np.arange(11, 26).reshape(5, 3)) 0 1 2
0 11 12 13
1 14 15 16
2 17 18 19
3 20 21 22
4 23 24 25也可以每一列的数据类型都不一样。
查看每一列数据的类型。
print(df1.dtypes) 0 int64
1 int64
2 int64
dtype: object 查看行号:
print(df.index) Index([u'a', u'b', u'c', u'd', u'e'], dtype='object') 查看列号:
print(df.columns) Int64Index([1, 2, 3], dtype='int64') 仅查看值:
print(df.values) 输出:
[[ 0.42982166 -0.55080003 -0.10371232]
[ 2.3667385 -0.43756513 -0.3424525 ]
[-0.10979349 -0.53370558 -0.64822069]
[ 0.1075425 1.07475297 -0.63868565]
[-1.49984813 -0.76088915 -0.45541864]]数据的总结:
print(df.describe()) 输出:
1 2 3
count 5.000000 5.000000 5.000000
mean 0.121067 0.564224 -0.056302
std 1.028792 1.019358 0.802618
min -1.378450 -0.405442 -0.911906
25% -0.226405 -0.318945 -0.477632
50% 0.353885 0.446713 -0.440411
75% 0.424473 1.058898 0.509519
max 1.431831 2.039897 1.038921 表格转置:
print(df.T) 输出:
a b c d e
1 -0.888418 -0.756006 0.631100 -0.114169 -1.522898
2 -0.508815 2.006081 1.534958 0.959365 -2.361547
3 -0.402582 -0.625021 -1.508425 2.113198 -0.537411按照index排序:
print(df.sort_index(axis=1,ascending=False)) 输出:
3 2 1
a 0.905230 -0.367712 0.126473
b -0.919645 -1.087937 0.948357
c -1.198343 -1.058886 -0.208211
d -0.943338 -0.257365 0.248873
e 0.714267 0.956977 -1.387111值排序:
print(df.sort_values(by=2)) 输出:
1 2 3
b 0.425399 -1.417989 0.739348
c -0.579914 -0.747744 0.027091
e -0.388667 -0.674340 0.457087
d 1.050316 -0.047161 -1.090049
a 0.444147 0.124354 -1.195624选择数据
#生成数据
dates = pd.date_range('20180504', periods=6)
df = pd.DataFrame(np.arange(24).reshape(6, 4), index=dates, columns=['A', 'B', 'C','D'])
print(df) 输出:
A B C D
2018-05-04 0 1 2 3
2018-05-05 4 5 6 7
2018-05-06 8 9 10 11
2018-05-07 12 13 14 15
2018-05-08 16 17 18 19
2018-05-09 20 21 22 23简单筛选:
print(df.A)
print(df['A']) 输出:
2018-05-04 0
2018-05-05 4
2018-05-06 8
2018-05-07 12
2018-05-08 16
2018-05-09 20
Freq: D, Name: A, dtype: int64筛选多行:
df[1:4]最后保留的是前三个,即1、2、3;
df['2018-05-05':'2018-05-07']会把从 '2018-05-05'到'2018-05-07'的所有保留,包括'2018-05-07'
这两个的区别就是,前者不要最后一项,左闭右开;后者要最后一项,左闭右闭。
print(df[1:4])
print(df['2018-05-05':'2018-05-07']) 输出:
A B C D
2018-05-05 4 5 6 7
2018-05-06 8 9 10 11
2018-05-07 12 13 14 15根据标签:loc
print(df.loc['20180505']) 输出:
A 4
B 5
C 6
D 7
Name: 2018-05-05 00:00:00, dtype: int64print(df.loc[:,['A', 'B']]) 输出:
A B
2018-05-04 0 1
2018-05-05 4 5
2018-05-06 8 9
2018-05-07 12 13
2018-05-08 16 17
2018-05-09 20 21根据序列:iloc
print(df.iloc[2:4, 2:4]) 输出:
C D
2018-05-06 10 11
2018-05-07 14 15print(df.iloc[2, 3])
#输出:
11print(df.iloc[[1, 3, 4], 1:3])
#输出:
B C
2018-05-05 5 6
2018-05-07 13 14
2018-05-08 17 18序列与标签的混合:ix
print(df.ix[:3, ['A', 'B']])
#输出:
A B
2018-05-04 0 1
2018-05-05 4 5
2018-05-06 8 9前边是根据序列,选择前三行,后边是根据标签选择列。
根据判断来筛选
print(df[df.B > 9])
#输出:
A B C D
2018-05-07 12 13 14 15
2018-05-08 16 17 18 19
2018-05-09 20 21 22 23 设置值
根据索引或者标签改变值:
df.iloc[2, 3] = 111
df.loc['2018-05-09', 'D'] = 222 根据条件来设置:
df.B[df.A > 5] = 0
#A列大于5的位置,对应的B列的相应位置改变成0
#输出:
A B C D
2018-05-04 0 1 2 3
2018-05-05 4 5 6 7
2018-05-06 8 0 10 11
2018-05-07 12 0 14 15
2018-05-08 16 0 18 19
2018-05-09 20 0 22 23按行、列设置
df['F'] = np.nan
#加了一列'F',并将值设置为NaN。
#输出:
A B C D F
2018-05-04 0 1 2 3 NaN
2018-05-05 4 5 6 7 NaN
2018-05-06 8 9 10 11 NaN
2018-05-07 12 13 14 15 NaN
2018-05-08 16 17 18 19 NaN
2018-05-09 20 21 22 23 NaNdf[1:2] = np.nan
df['20180505':'20180505'] = np.nan
#输出:
A B C D
2018-05-04 0.0 1.0 2.0 3.0
2018-05-05 NaN NaN NaN NaN
2018-05-06 8.0 9.0 10.0 11.0
2018-05-07 12.0 13.0 14.0 15.0
2018-05-08 16.0 17.0 18.0 19.0
2018-05-09 20.0 21.0 22.0 23.0添加数据
df['E'] = pd.Series(['a', np.inf, 2, 55, 43, 6 ], index=pd.date_range('20180504', periods=6))
#输出:
A B C D E
2018-05-04 0 1 2 3 a
2018-05-05 4 5 6 7 inf
2018-05-06 8 9 10 11 2
2018-05-07 12 13 14 15 55
2018-05-08 16 17 18 19 43
2018-05-09 20 21 22 23 6处理丢失数据
有些数据中可能含有NaN。要删除或者填补。
创建一个有NaN的矩阵:
dates = pd.date_range('20180504', periods=6)
df = pd.DataFrame(np.arange(24).reshape(6, 4), index=dates, columns=['A', 'B', 'C', 'D'])
df['E'] = pd.Series(['a', np.nan, 2, 55, 43, 6 ], index=pd.date_range('20180504', periods=6))
print(df)
#输出:
A B C D E
2018-05-04 0 1 2 3 a
2018-05-05 4 5 6 7 NaN
2018-05-06 8 9 10 11 2
2018-05-07 12 13 14 15 55
2018-05-08 16 17 18 19 43
2018-05-09 20 21 22 23 6去掉NaN
df.dropna()
print(df.dropna())
#输出:
A B C D
2018-05-05 4 5.0 6 7.0
2018-05-07 12 13.0 14 15.0
2018-05-08 16 17.0 18 19.0
2018-05-09 20 21.0 22 23.0print(df.dropna()) # 每行只要有nan,就删除该行
print(df.dropna(axis=1)) # 每列只要有nan,就删除该列
print(df.dropna(how='all')) # 'any' 或者默认参数'any',只有要nan就可以删除;'all' 必须全部是nan才可以删除
print(df.dropna(thresh=2)) # ???用其他值填补NaN
print(df.fillna(value='haha'))
#输出:
A B C D
2018-05-04 0 haha 2 3
2018-05-05 4 5 6 7
2018-05-06 8 9 10 haha
2018-05-07 12 13 14 15
2018-05-08 haha haha haha haha
2018-05-09 20 21 22 23isnull()
Detect missing values (NaN in numeric arrays, None/NaN in object arrays)
isna()
Return a boolean same-sized object indicating if the values are NA.
print(df.isnull())
print(df.isna())
#输出:
A B C D
2018-05-04 False True False False
2018-05-05 False False False False
2018-05-06 False False False True
2018-05-07 False False False False
2018-05-08 True True True True
2018-05-09 False False False False数据导入导出
可以读取和导出很多种形式的数据。
# coding:utf-8
import pandas as pd
data = pd.read_csv('student.csv')
print(data)
data.to_pickle('student.pickle')数据合并 concat
axis方向
默认值是0。
df1 = pd.DataFrame(np.ones((3, 4))*0, columns=['A', 'B', 'C', 'D'])
df2 = pd.DataFrame(np.ones((3, 4))*2, columns=['A', 'B', 'C', 'D'])
df3 = pd.concat([df1, df2], axis=0)
print(df3)
#输出:
A B C D
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
0 2.0 2.0 2.0 2.0
1 2.0 2.0 2.0 2.0
2 2.0 2.0 2.0 2.0重置index:
默认值是False。
df3 = pd.concat([df1, df2], axis=0, ignore_index=True)
print(df3)
#输出:
A B C D
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 2.0 2.0 2.0 2.0
4 2.0 2.0 2.0 2.0
5 2.0 2.0 2.0 2.0join
outer为预设值,也就是按照列(column)的方式,相同的column对齐,其他地方补NaN。
inner,只要column相同的部分,column的交集。
df1 = pd.DataFrame(np.ones((3, 4))*0, columns=['A', 'B', 'C', 'D'])
df2 = pd.DataFrame(np.ones((3, 4))*2, columns=['B', 'C', 'D', 'E'])
df3 = pd.concat([df1, df2], join='outer')
print(df3)
#输出:
A B C D E
0 0.0 0.0 0.0 0.0 NaN
1 0.0 0.0 0.0 0.0 NaN
2 0.0 0.0 0.0 0.0 NaN
0 NaN 2.0 2.0 2.0 2.0
1 NaN 2.0 2.0 2.0 2.0
2 NaN 2.0 2.0 2.0 2.0join_axes
合并按照某一个资料集的index或者columns。没有的地方补NaN。axis为0时,应该按照columns。axis为1时,应该按照index。不写这个参数的时候,在axis方向上的标签取并集。
df1 = pd.DataFrame(np.ones((3, 4))*0, index=[1, 2, 3], columns=['A', 'B', 'C', 'D'])
df2 = pd.DataFrame(np.ones((3, 4))*2, index=[2, 3, 4], columns=['B', 'C', 'D', 'E'])
df3 = pd.concat([df1, df2], axis=1, join_axes=[df1.index])
print(df3)
#输出:
A B C D B C D E
1 0.0 0.0 0.0 0.0 NaN NaN NaN NaN
2 0.0 0.0 0.0 0.0 2.0 2.0 2.0 2.0
3 0.0 0.0 0.0 0.0 2.0 2.0 2.0 2.0append
只有纵向。变长。
没有横向。没有变胖。
df1 = pd.DataFrame(np.ones((3, 4)) * 0, index=[1, 2, 3], columns=['A', 'B', 'C', 'D'])
s1 = pd.Series([1, 2, 3, 4], index=['A', 'B', 'C', 'D'])
print(df1.append(s1, ignore_index=True))
#输出:
A B C D
0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0
3 1.0 2.0 3.0 4.0合并 merge
merge和concat的区别是:merge靠的是key。
合并的时候有4种办法:how = ['left', 'right', 'outer', 'inner'],预设值how='inner'。
依据一组key合并
# coding:utf-8
import pandas as pd
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key': ['K0', 'K2', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
print(left)
print(right)
res = pd.merge(left, right, on='key')
print(res)
#输出:
A B key
0 A0 B0 K0
1 A1 B1 K1
2 A2 B2 K2
3 A3 B3 K3
C D key
0 C0 D0 K0
1 C1 D1 K2
2 C2 D2 K2
3 C3 D3 K3
A B key C D
0 A0 B0 K0 C0 D0
1 A2 B2 K2 C1 D1
2 A2 B2 K2 C2 D2
3 A3 B3 K3 C3 D3依据两组key合并。
差不多。
Indicator
将合并的记录放在新的一列。
依据index合并。
res = pd.merge(left, right, left_index=True, right_index=True, indicator=True)
#输出:
A B key_x C D key_y _merge
0 A0 B0 K0 C0 D0 K0 both
1 A1 B1 K1 C1 D1 K2 both
2 A2 B2 K2 C2 D2 K2 both
3 A3 B3 K3 C3 D3 K3 both画图
plot
# coding:utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.Series(np.random.randn(1000))
cumdata = data.cumsum()
cumdata.plot()
plt.show()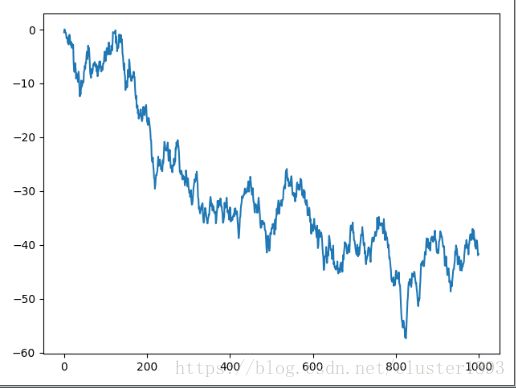
data = pd.DataFrame(np.random.randn(1000, 4), index=np.arange(1000), columns=list('ABCD'))
print(data)
cumdata = data.cumsum()
cumdata.plot()
plt.show()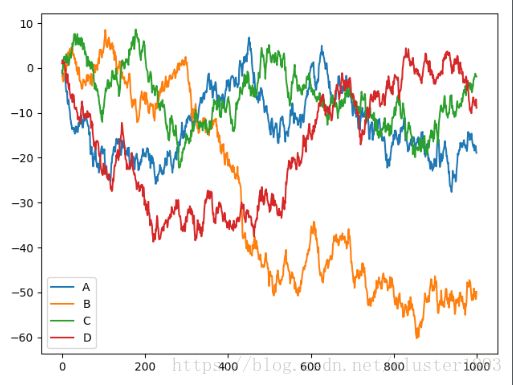
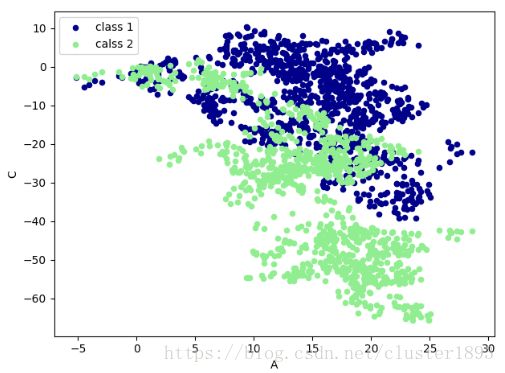
散点图 plot.scatter
# coding:utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.DataFrame(np.random.randn(1000, 4), index=np.arange(1000), columns=list('ABCD'))
data = data.cumsum()
ax = data.plot.scatter(x='A', y='B', color='DarkBlue', label='class 1')
data.plot.scatter(x='A', y='C', color='LightGreen', label='calss 2', ax=ax)
plt.show()