ubuntu中使用docker从零开始搭建hadoop、spark的集群环境
一、Docker环境搭建
二、Docker镜像操作
查看当前仓库中的镜像
docker images

远程拉取镜像
如果当前本地仓库中没有ubuntu镜像,可以从远程仓库中拉取(https://hub.docker.com)
或者使用其他ubuntu镜像,如
docker pull daocloud.io/ubuntu
使用镜像创建容器
使用ubuntu镜像创建一个容器,并进入
docker run -it daocloud.io/ubuntu /bin/bash
退出容器返回
exit
Docker常用命令

三、安装JDK1.8
apt-get install software-properties-common python-software-properties
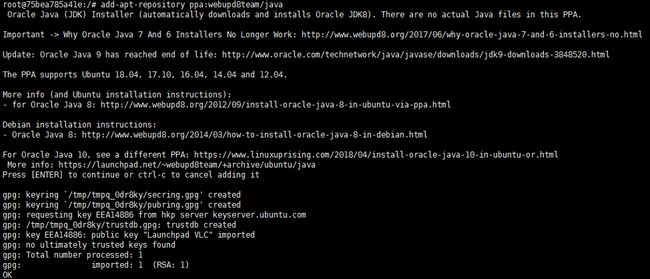
add-apt-repository ppa:webupd8team/java
apt-get update
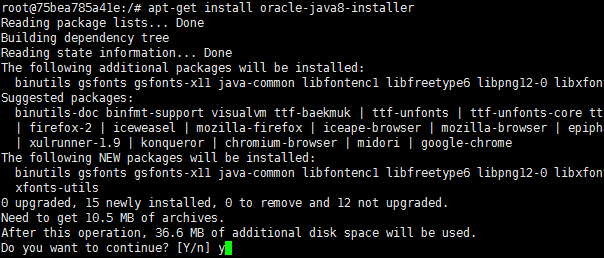
apt-get install oracle-java8-installer

update-java-alternatives -s java-8-oracle
java –version

安装vim文本编辑器
apt-get install vim
配置java环境变量(以后的环境变量也这样配置)。使用命令:
vim /etc/profile
增加如下字段
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
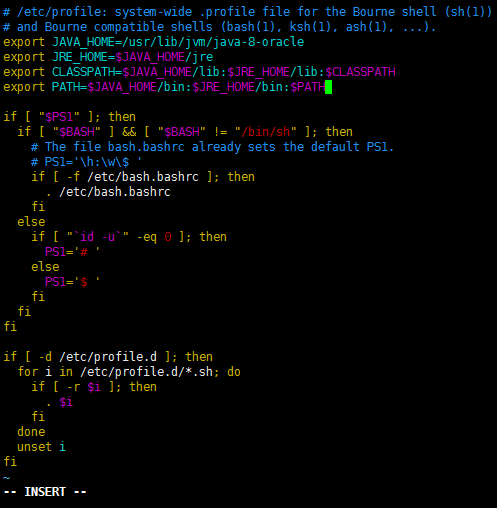
保存并退出(escàshift : àwqàenter)
使环境变量生效
source /etc/profile
检查是否生效

至此已配好java环境,将此时容器的状态保存为镜像。
四、保存容器状态为本地镜像
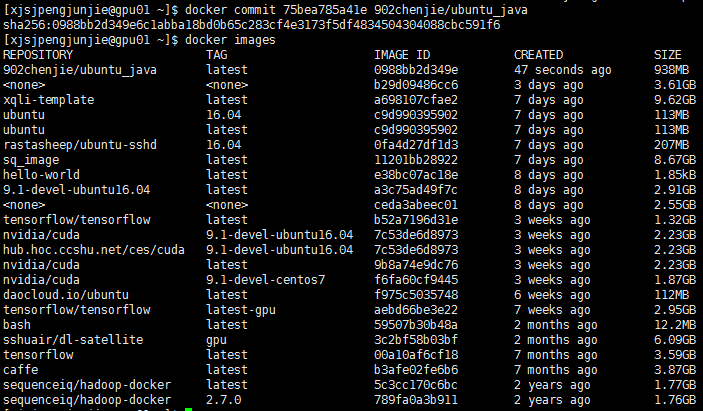
另起一个窗口ssh进gpu01结点,使用docker ps命令查看当前运行的容器,可以看到容器的ID为75bea785a41e。

使用上面的ID提交镜像,为镜像取一个名字
docker commit 75bea785a41e 902chenjie/ubuntu_java
查看镜像
docker images
五、下载hadoop、spark、scala、hive、hbase、zookeeper
5.1 下载并解压安装包
下载hadoop安装包(如果下面的地址下载不了,可以到http://archive.apache.org/dist/hadoop/common/找到所有版本的下载地址)
wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz
解压安装包
tar -zxvf hadoop-2.7.6.tar.gz
下载spark安装包并解压(如果下面的地址下载不了,可以到http://archive.apache.org/dist/spark/找到所有版本的下载地址)
wget http://mirrors.shu.edu.cn/apache/spark/spark-2.0.2/spark-2.0.2-bin-hadoop2.7.tgz
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz
下载scala安装包并解压
wget https://downloads.lightbend.com/scala/2.11.11/scala-2.11.11.tgz
tar -zxvf scala-2.11.11.tgz
下载hive安装包并解压(如果下面的地址下载不了,可以到http://archive.apache.org/dist/hive找到所有版本的下载地址)
wget http://mirrors.shu.edu.cn/apache/hive/hive-2.3.3/apache-hive-2.3.3-bin.tar.gz
tar -zxvf apache-hive-2.3.3-bin.tar.gz
下载hbase安装包并解压(如果下面的地址下载不了,可以到http://archive.apache.org/dist/hbase找到所有版本的下载地址)
wget http://mirrors.shu.edu.cn/apache/hbase/1.2.6/hbase-1.2.6-bin.tar.gz
tar -zxvf hbase-1.2.6-bin.tar.gz
下载zookeeper(如果下面的地址下载不了,可以到http://archive.apache.org/dist/zookeeper找到所有版本的下载地址)
wget http://mirrors.shu.edu.cn/apache/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz
tar -zxvf zookeeper-3.4.11.tar.gz
可选:删掉安装包

至此我们解压的软件及版本如下:
apache-hive-2.3.3-bin
hadoop-2.7.6
hbase-1.2.6
scala-2.11.11
spark-2.0.2-bin-hadoop2.7
zookeeper-3.4.11
5.2 配置环境变量
vim /etc/profile
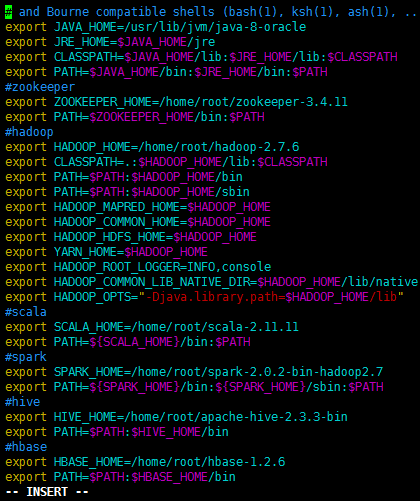
增加如下内容:
#zookeeper
export ZOOKEEPER_HOME=/root/zookeeper-3.4.11
export PATH=$ZOOKEEPER_HOME/bin:$PATH
#hadoop
export HADOOP_HOME=/root/hadoop-2.7.6
export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
#scala
export SCALA_HOME=/root/scala-2.11.11
export PATH=${SCALA_HOME}/bin:$PATH
#spark
export SPARK_HOME=/root/spark-2.0.2-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH
#hive
export HIVE_HOME=/root/apache-hive-2.3.3-bin
export PATH=$PATH:$HIVE_HOME/bin
#hbase
export HBASE_HOME=/root/hbase-1.2.6
export PATH=$PATH:$HBASE_HOME/bin
保存并退出
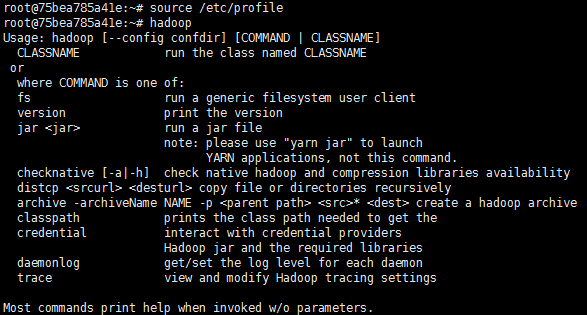
使环境变量生效
source /etc/profile
验证
hadoop
5.3 网络环境配置
安装网络工具,以方便后面配置集群网络
apt-get install net-tools
apt-get install inetutils-ping
安装SSH服务
更新下软件库
apt-get update
安装ssh服务
apt-get install openssh-server
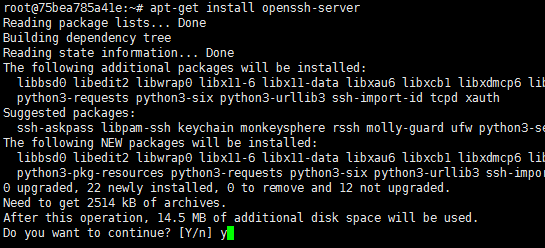
启动服务
service ssh start
![]()
查看服务是否启动
ps -e |grep ssh
![]()
生成公钥(一路回车)
ssh-keygen -t rsa
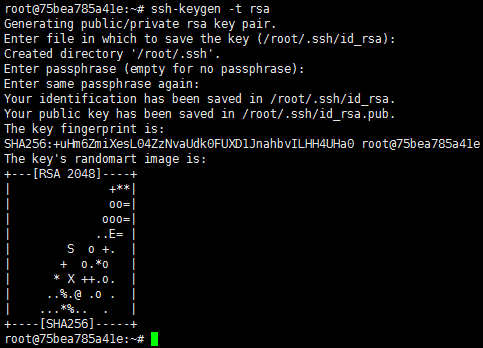
将本机公钥放到本机认证的密钥中,使得本机ssh本机不需要密码
cat /root/.ssh/id_rsa.pub >>/root/.ssh/authorized_keys
ssh本机测试
ssh localhost
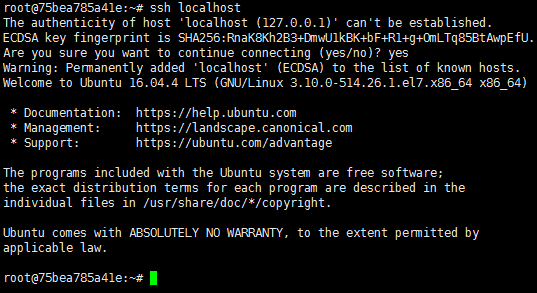
六、初步配置上述组件
6.1 Hadoop初步配置
切换到hadoop配置文件目录
cd ~/hadoop-2.7.6/etc/hadoop/
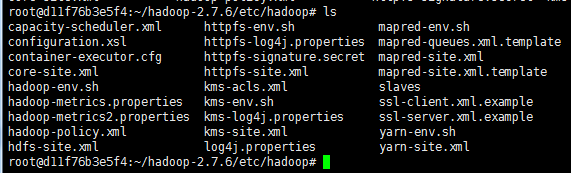
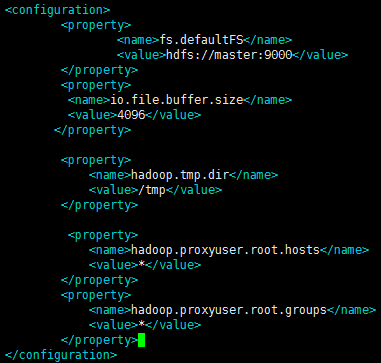
修改core-site.xml如下:
fs.defaultFS
hdfs://localhost:9000
io.file.buffer.size
4096
hadoop.tmp.dir
/tmp
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
修改hadoop-env.sh
vim hadoop-env.sh
增加:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle

修改hdfs-site.xml
vim hdfs-site.xml
增加如下内容:
dfs.replication
2
dfs.namenode.name.dir
/root/hadoop-2.7.6/hdfs/name
dfs.datanode.data.dir
/root/hadoop-2.7.6/hdfs/data
dfs.permissions
false
修改mapred-site.xml
vim mapred-site.xml
增加如下内容:
mapreduce.framework.name
yarn
修改slaves文件,记录hadoop的datanode地址
vim slaves
增加如下内容:
localhost
修改yarn-site.xml
vim yarn-site.xml
增加如下内容:
The hostname of the RM.
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
6.2 Spark初步配置
切换到spark配置文件目录
cd ~/spark-2.0.2-bin-hadoop2.7/conf

修改slaves文件
vim slaves
增加如下内容:
localhost
修改spark-defaults.conf
vim spark-defaults.conf
增加如下内容:
spark.master spark://localhost:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://localhost:9000/historyserverforSpark
spark.yarn.historyServer.address localhost:18080
spark.history.fs.logDirectory hdfs://localhost:9000/historyserverforSpark
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 4g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
修改spark-env.sh
vim spark-env.sh
增加如下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export SCALA_HOME=/root/scala-2.11.11
export HADOOP_HOME=/root/hadoop-2.7.6
export HADOOP_CONF_DIR=/root/hadoop-2.7.6/etc/hadoop
export SPARK_MASTER_IP=localhost
export SPARK_WORKER_MEMORY=4g
export SPARK_EXECUTOR_MEMORY=4g
export SPARK_DRIVER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_MEM=4G
6.3 保存容器状态为本地镜像
保存当前准备好安装包的容器状态镜像,以后配置集群每个节点都在此镜像上修改配置。
在另一个窗口
docker commit 75bea785a41e 902chenjie/ubuntu_bigdata
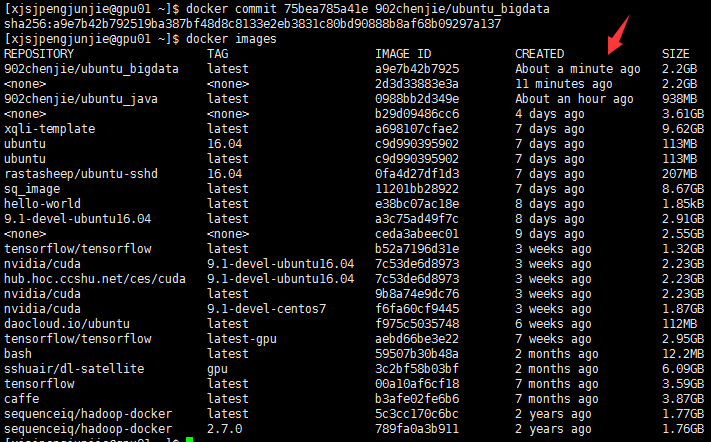
七、集群配置
7.1 使用镜像创建容器
使用此前保存的本地镜像创建几个容器,其中一个作为master,另外几个作为slave。
以2台结点的集群创建为例:
分别新建3个ssh连接到gpu01结点,每个连接创建1个容器,共创建3个容器:
docker run -it 902chenjie/ubuntu_bigdata /bin/bash



可以看到三个容器的主机名分别为d6ab2641dcf3、a15ae831e68b、207343b5d21d
7.2 网络相关设置
对于每个容器,查看其IP,执行
ifconfig

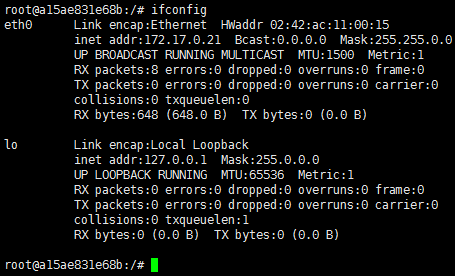
整理得到IP地址、主机名对应列表
计划作为master 172.17.0.19 d6ab2641dcf3
计划作为slave 172.17.0.21 a15ae831e68b
计划作为slave 172.17.0.25 207343b5d21d
修改每个容器的hosts文件
vim /etc/hosts
增加如下内容:
172.17.0.19 d6ab2641dcf3
172.17.0.21 a15ae831e68b
172.17.0.25 207343b5d21d
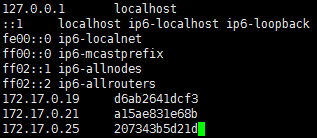
保存并退出。
对于每个节点:启动ssh服务:
service ssh start
对于每个节点,将其ssh公钥拷贝到其它节点的认证密钥中:
ssh-copy-id -i ~/.ssh/id_rsa.pub 其它节点的主机名或者IP


…
可选:对于每个节点,ssh其它节点验证是否能免密登录:
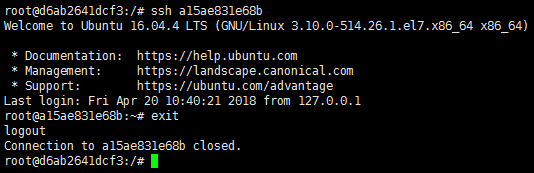
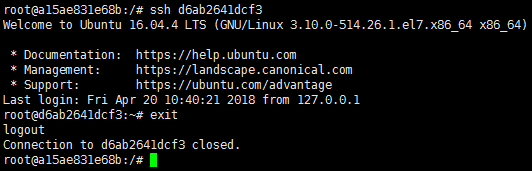
7.3 hadoop集群配置
对于其中一个节点,修改hadoop配置文件。
修改vim core-site.xml
vim core-site.xml
将master修改为计划的master的主机名,如d6ab2641dcf3
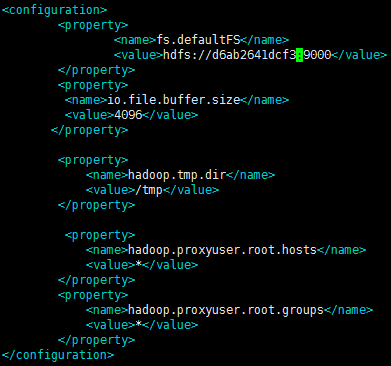
修改slaves文件,将要作为slaves的主机名写入其中,如a15ae831e68b、207343b5d21d
vim slaves
修改为:
a15ae831e68b
207343b5d21d
修改yarn-site.xml
vim yarn-site.xml
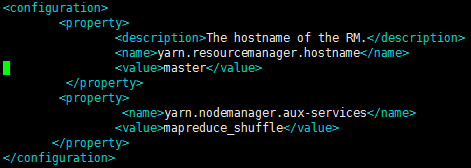
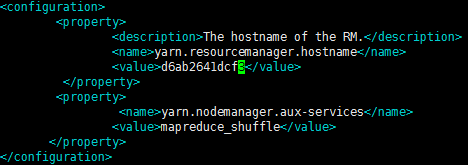
将这些配置拷贝覆盖到其它节点
scp -r ~/hadoop-2.7.6/etc/hadoop/ root@a15ae831e68b:/root/hadoop-2.7.6/etc/

执行source /etc/profile使环境变量生效
source /etc/profile
在master上初始化namenode
hadoop namenode -format

切换到hadoop sbin目录
cd ~/hadoop-2.7.6/sbin
![]()
启动hadoop集群
./start-all.sh

在master上使用jps查看进程,应该有如下:

在slave上使用jps查看进程,应该有如下:

使用hdfs命令创建一个目录以及文件测试hdfs功能
hadoop fs -mkdir /chenjie
新建一个本地文本文件,并上传到hdfs中
vim test.txt
输入任意内容并保存退出
上传文件到hdfs
hadoop fs -put test.txt /chenjie

运行wordcount测试
切换到~/hadoop-2.7.6/share/hadoop/mapreduce
cd ~/hadoop-2.7.6/share/hadoop/mapreduce

运行wordcount
hadoop jar hadoop-mapreduce-examples-2.7.6.jar wordcount /chenjie/test.txt /out

hadoop fs -lsr /
hadoop fs -text /out/part-r-00000

7.4 spark集群配置
master切换到spark的conf目录
cd ~/spark-2.0.2-bin-hadoop2.7/conf
修改slaves文件为:
a15ae831e68b
207343b5d21d
修改spark-defaults.conf文件

为

修改spark-env.sh
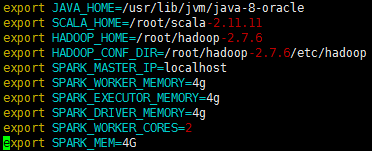
为
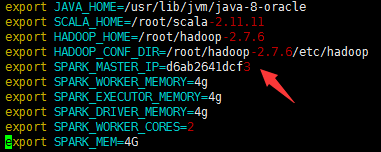
将这些配置发送到其它节点
scp -r ~/spark-2.0.2-bin-hadoop2.7/conf root@a15ae831e68b:/root/spark-2.0.2-bin-hadoop2.7/
scp -r ~/spark-2.0.2-bin-hadoop2.7/conf root@207343b5d21d:/root/spark-2.0.2-bin-hadoop2.7/
切换到master的sbin目录
cd ~/spark-2.0.2-bin-hadoop2.7/sbin
创建spark的history目录
hadoop fs -mkdir /historyserverforSpark
启动spark集群
./start-all.sh

Master上查看进程
jps
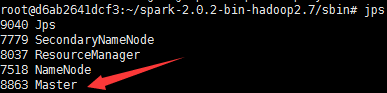
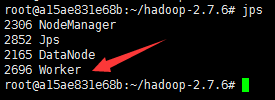
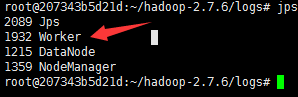
Slaves上查看进程
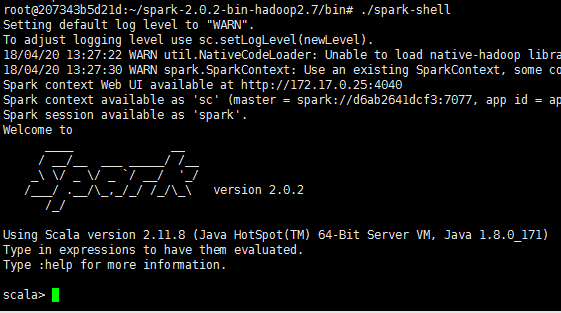
切换到master的bin目录
cd ~/spark-2.0.2-bin-hadoop2.7/bin
scala环境测试,进入spark-shell
./spark-shell
输入以下代码:
val test = sc.textFile("hdfs://d6ab2641dcf3:9000/chenjie/test.txt")
test.first()

Python环境测试
进入pyspark
./pyspark
输入如下代码:
test = sc.textFile("hdfs://d6ab2641dcf3:9000/chenjie/test.txt")
test.first()

八、集群环境的使用
容器 |
镜像 |
IP |
hadoop |
spark |
d6ab2641dcf3 |
ubuntu_bigdata |
172.17.0.19 |
master |
master |
a15ae831e68b |
ubuntu_bigdata |
172.17.0.21 |
slave |
slave |
207343b5d21d |
ubuntu_bigdata |
172.17.0.25 |
slave |
slave |
在gpu01结点进入某个容器:例如207343b5d21d
docker exec -it 207343b5d21d /bin/bash
![]()
切换到spark的bin目录下
cd ~/spark-2.0.2-bin-hadoop2.7/bin

使用./pyspark或者./spark-shell启动spark的shell环境,使用./spark-submit提交作业。