pandas基础知识详解
pandas基础
首先导入库,别名

pandas有两种数据结构: Series 和 DataFrame
那么怎么生成一个序列?要生成一个序列,使用的是pd.Series。记得Series首字母大写,如果要生成缺失值,可以用np.nan生成NaN值

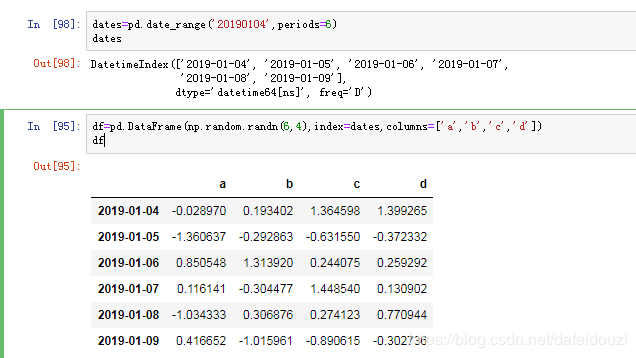
也可以生成一组日期数据,用的是pd.date_range(),periods表示要生成日期的个数

那么如何生成一个DataFrame,感觉DataFrame用得比较多
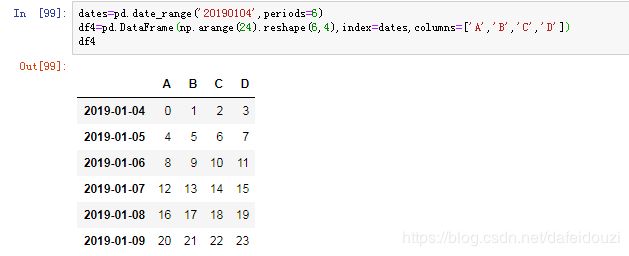
下面的DataFrame中的index用的是上面的dates,生成一个服从正态分布的dataframe,该数据维度是6x4
也可以自定义一个范围,用的是np.arange(),reshape()表示的是生成一个几行几列的数据

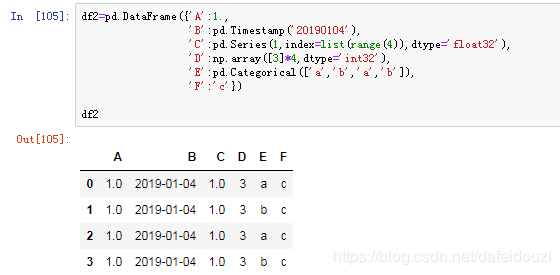
也可以将字典数据转换成数据框
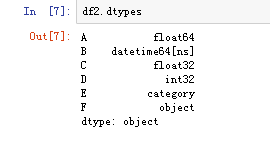
可以用data.dtypes查看每一列的数据类型
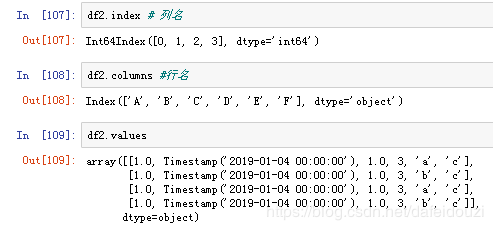
如果想要提取这个dataframe的列名,可以使用data.index
提取行名用的是data.columns
提取dataframe中的值用的是data.values
可以用data.describe()得到每列的描述统计信息
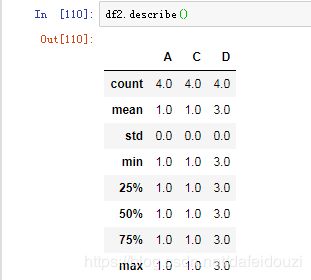
转置用的是data.T
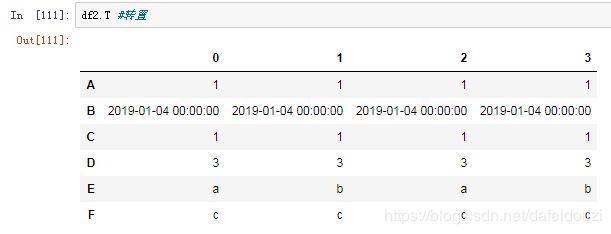
如果要根据列名排序,用的是data.sort_index(axis=1,ascending=False)。axis=1表示按列,ascending=False表示降序
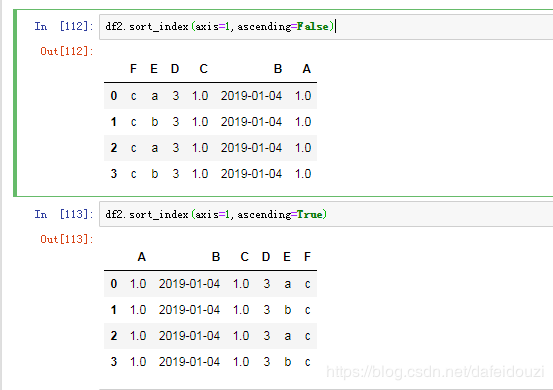
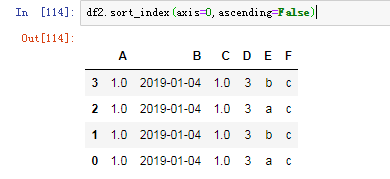
也可以按行排序,令axis=0就好了
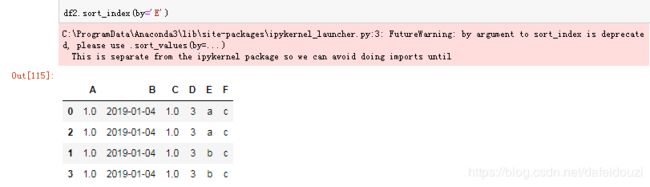
也可以指定某一列进行排序,用的是by这个参数
pandas 选择数据
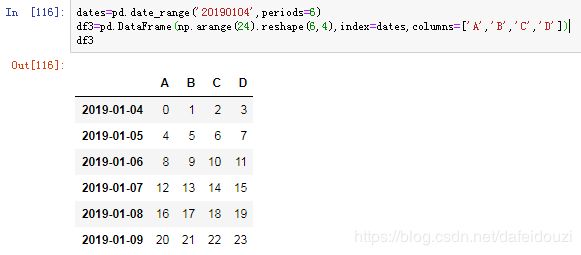
先生成一个dataframe
我想要提取A这一列数据,可以用df3['A'],也可以用df3.A,这两种表示方式得到的结果是一样的

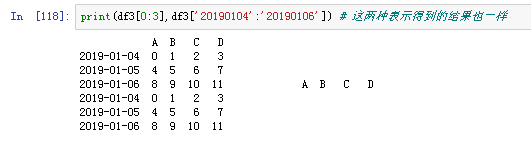
如果我要提取前3行的数据,可以用以下两种表示方式
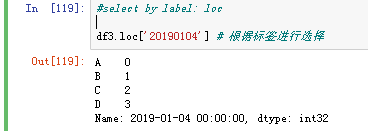
可以通过标签选择数据
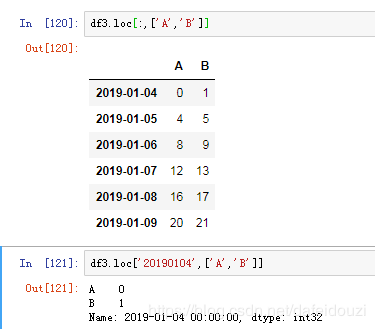
除了通过标签选择数据,也可以通过位置选择

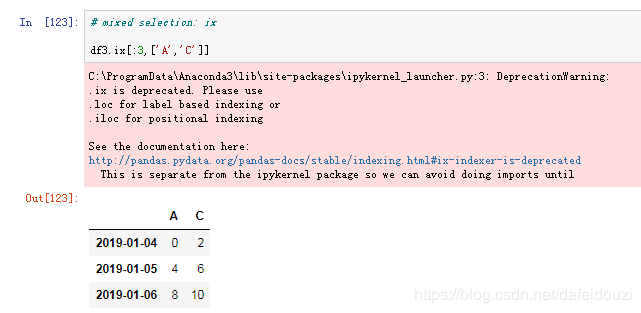
那么能不能同时根据标签和位置选取数据呢?答案是肯定的,混合使用的时候用的是data.ix()
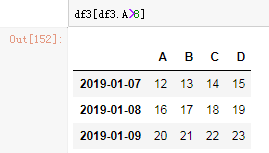
根据值去选取数据也可行,下面提取的是A这一列的值大于8的所有数据
pandas 设置值
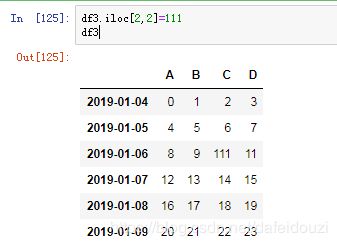
可以将dataframe中的某个值用别的值去替换
首先需要用索引定位要替换值的位置,然后对其进行赋值
我要在index里添加多 一行,并给B这列对应的位置处赋值一个数,没有数的位置用NaN填充
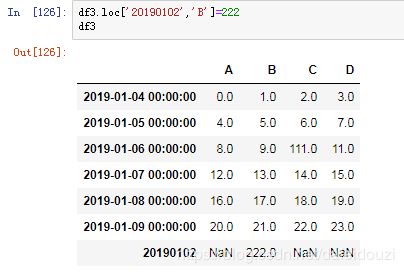
也可以用前面根据值选择数据的方式去设置值
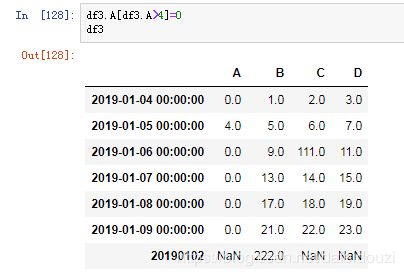
比如我要把dataframe中A这一列中大于4的值都替换成0
同样可以根据标签选择数据的方式去设置值,下面的代码是选取了F这一列,然后用NaN替换
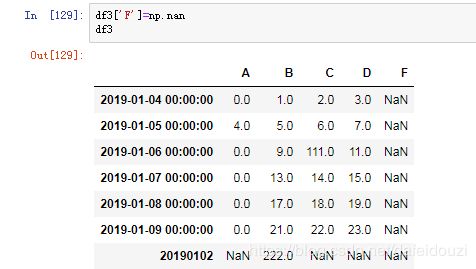
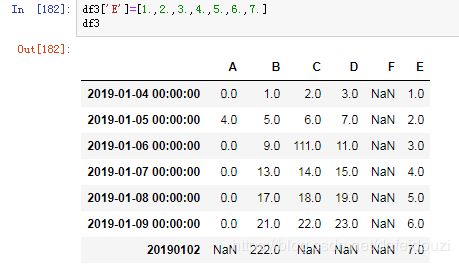
我想在原来数据的基础上添加多一列
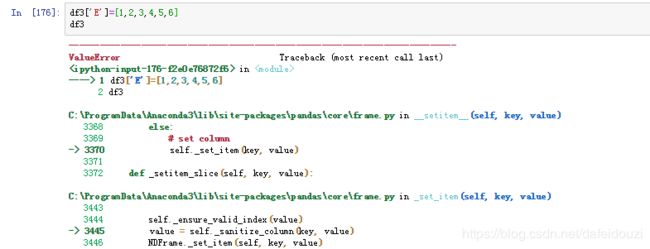
但是这里出错了,这是为什么呢?有没有看到原来数据的数据类型都是float,但是我们添加的数据都是int,还有数据的长度不一样
要想不出错,可以把添加的数据改成float类型的,还有数据长度要一样
pandas 处理丢失数据
先生成一个6x4的dataframe,数值范围从[0,24)
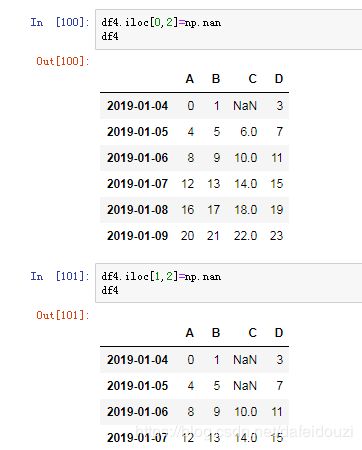
前面提过了值的替换,以及np.nan表示NaN值,所以把上面那个dataframe中第一行第三列和第2行第2列的数值改成NaN
处理缺失值的方式有哪些?有删除、填充、插值
这里只讲删除和填充
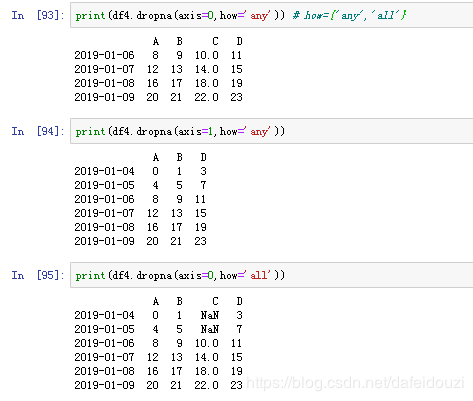
首先是删除,用的是dropna(axis,how),axis=0/1表示按行/列,how={any’,'all'},how='any'表示只要有一个缺失就删除那一行/列,how='all'表示一行/列全是缺失的时候才会删除掉那一整行/列
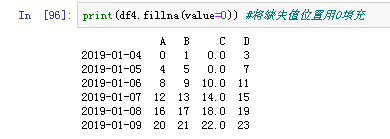
接着是填充fillna(),下面代码表示用0填充缺失值位置
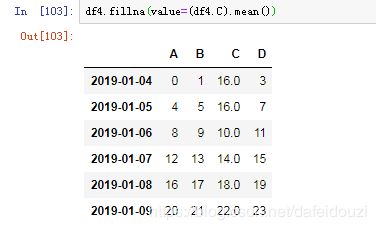
我打算用C这一列的均值去填充缺失的位置,结果如下:
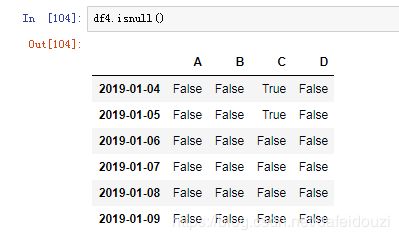
如果你拿到一个数据,你想知道这个数据里面有没有缺失,可以用data.isnull()去查看缺失值,不过这个函数返回的是布尔值
如果数据很多的话看起来不太方便,所以可以用np.any(data.isnull()==True),这串代码表示只要数据中有一个缺失值,就会返回True。

pandas 合并concat
先生成3个维数一样,列名一样的dataframe
如果要合并这三个dataframe,就可以使用pd.concat()这个函数,下面按行合并了这三组数据
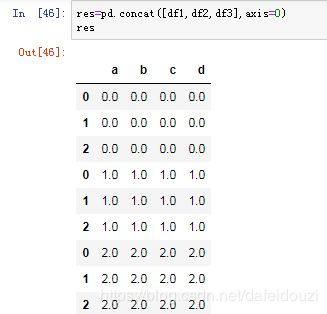
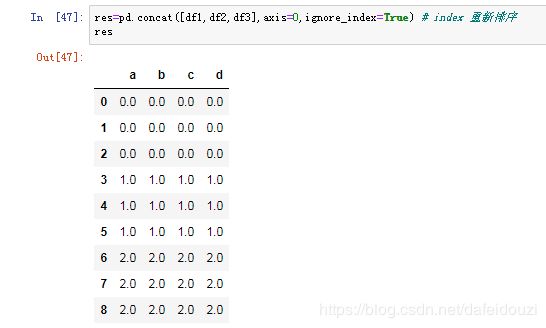
但是可以看到,合并之后的index没有改变,那要怎么做?这时候就要引入参数ignore_index,当这个参数等于True的时候,表示将Index重新排序
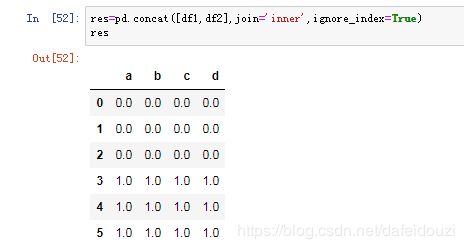
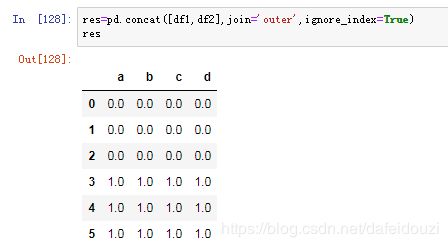
合并的方式有:'inner'、'outer'
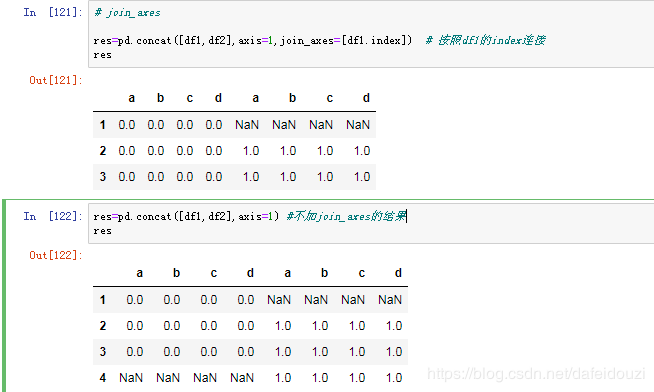
比如下面通过改变join的方式去合并df1,df2
也可以自定义根据某个dataframe种的index去合并,使用的是join_axes,下面是加join_axes和不加join_axes的结果对比,你能发现什么
pandas 合并append
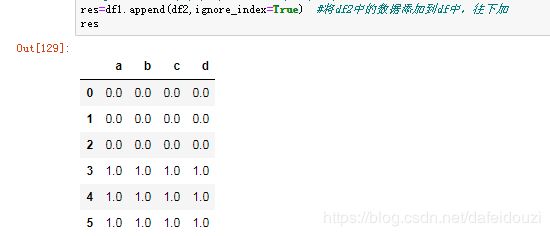
当然也可以直接将df2的数据直接添加到df1中去,用的是data.append()
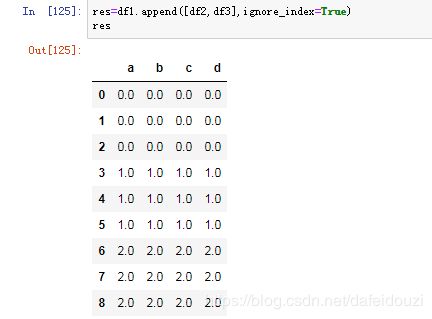
将df2、df3的数据都往df1中加,得到下面的结果
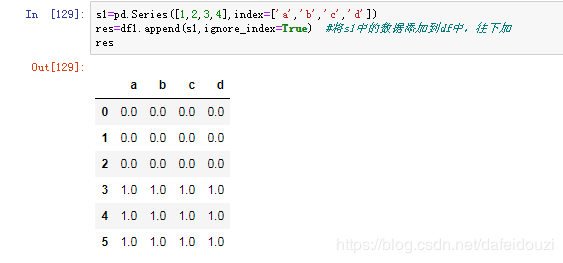
重新生成一个序列,往df1中加,结果如下
pandas 合并merge
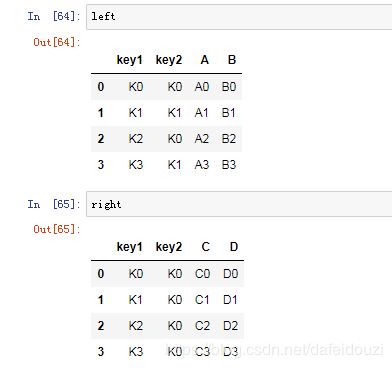
生成两个dataframe,它们的column,values有相同也有不同的

我要合并这两个dataframe,用的是pd.merge(),因为它们中key这一列名是相同的,所以我要根据这一列去合并,代码中的on这个参数就表示要根据那一列去合并

那如果是有两个key呢?也就是那两个dataframe中有两个列名是一样的,就比如下面的

key1、key2是一样的,所以我们要按照这两个column去合并,用列表的方式概括key1、key2

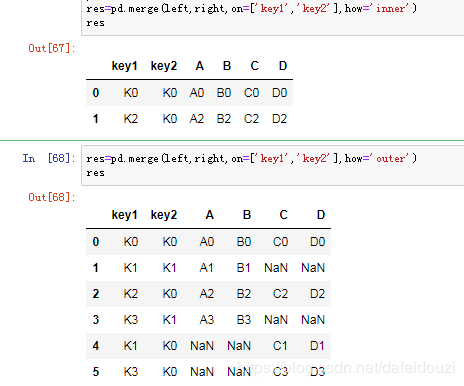
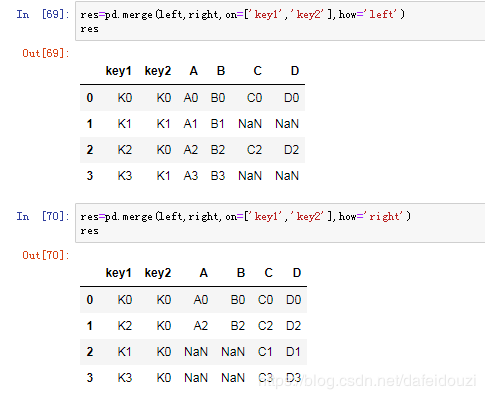
关于merge()合并的方式有4种:how=['left','right','outer','inner'],表示左连接、右连接、外连接、内连接,它们之间的区别之处可以自己Google或者百度一下。我理解的是,在下面的例子中,how=‘inner’:内连接,得到的是两个数据框的交集;how=‘outer’:外连接,得到的是两个数据框的并集;how=‘left’:左连接,表示按照left这个dataframe中的index来合并,how=‘right':右连接,表示按照right这个dataframe中的index来合并。
pandas plot画图
导入库,别名
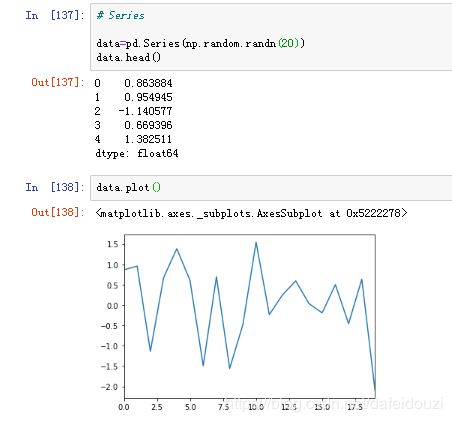
1.对序列画图,画图的时候直接用data.plot()就可以了
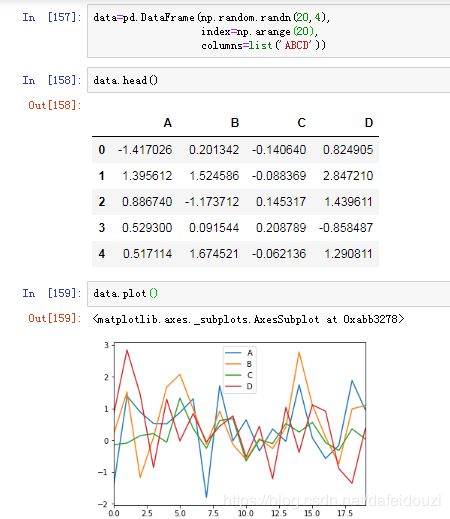
2.对dataframe绘图,直接data.plot()得到的是每一列对应的线图
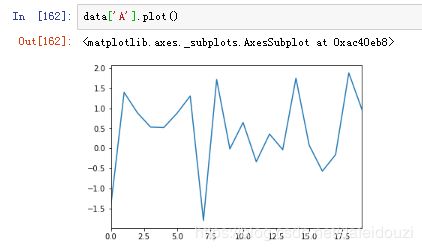
也可以单独选取dataframe中的一列绘图,比如A这一列
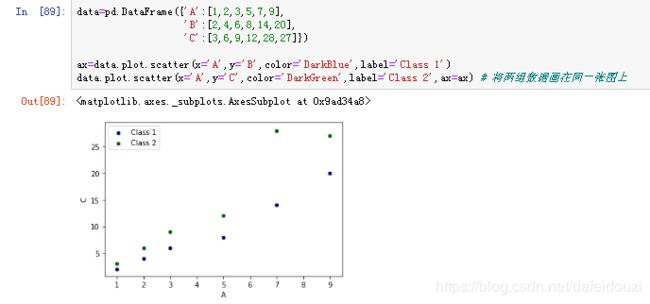
如果将两组横坐标相同的数据画出来的图展示在同一张图上,可以用下面的方法
这是看了莫烦python之后整理出来的~~~有需要的可以去看一下他的视频