Hive SparkSql rank() over,dense_rank() over,row_number() over的使用与区别
一、建表语句
create table student(
name string,
course string,
score int
)ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE二、测试数据
li shi,Chinese,96
wang er,English,71
zhang san,Chinese,92
zhang san,Math,86
wang wu,English,72
li shi,Math,88
wang er,Chinese,91
zhang san,English,72
wang er,Math,85
wang wu,Chinese,92
li shi,English,76
wang wu,Math,88三、使用方法
1、rank() over
--成绩相同的,并列名次,下一个名次空出被占用的名次
select name
,course
,score
,rank() over (partition by course order by score desc) rank
from student ; 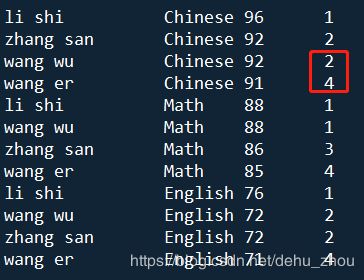
2、dense_rank()
--成绩相同的,并列名次,下一个名次不空出被占用的名次
select name
,course
,score
,dense_rank() over (partition by course order by score desc) rank
from student ; 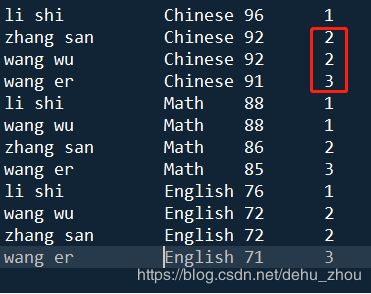
3、row_number over
--不管是否并列,都进行连续排名
select name
,course
,score
,row_number() over(partition by course order by score desc) rank
from student ; 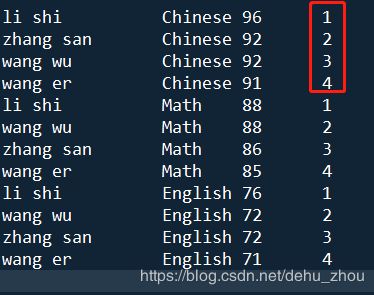
注意: 使用rank() over的时候,空值是最大的,如果排序字段为null,可能造成null字段排在最前面,影响排序结果。可以这样:
rank() over(partition by course order by score desc nulls last)来规避这个问题。