原生DOM入门
本文转载自:https://zhuanlan.zhihu.com/p/32692487
原生DOM接口挺多的,需要花点时间研究下,不过先把基础整好,后面框架估计好学点。
1. DOM是啥
1.1 知识回顾
先回顾一下HTML的基本结构
<html lang="zh-Hans">
<head>
head>
<body>
body>
html>
以上就是最简单的HTML 5的结构。一般我们会把它处理成一棵树,一棵节点树。
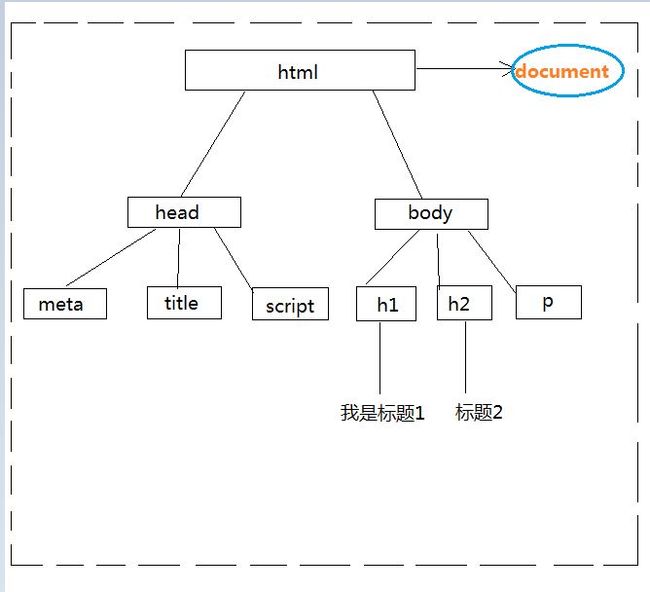
以上就是一棵树,浏览器把html渲染成的树,也就是Document结构。每个框就是一个Element、标题等文本内容是Text。
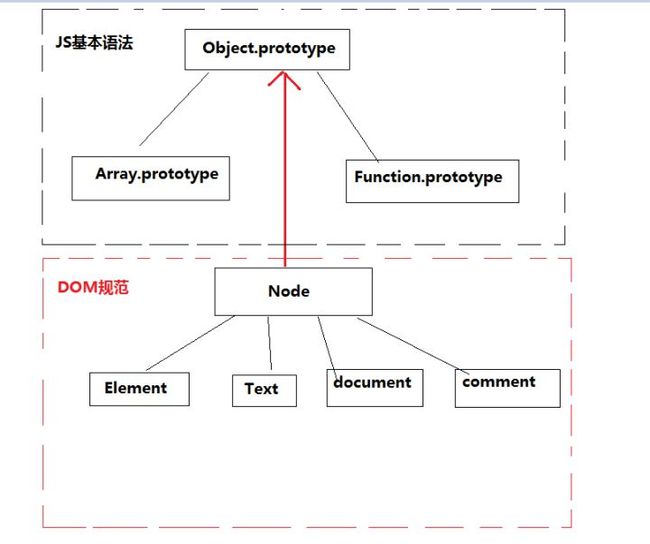
Document、Element、Text 的祖先都是Node。以下是MDN的继承树

可是在内存中,存的不是html树,是一棵对应html各个节点的对象树,而且对象树的节点是与html树的节点一一对应的。
以上是内存中的对象树。这些对象应该怎么定义,是由DOM规范规定的。
也可以如下这么理解
页面中的节点,根据Element、Text、Document、Comment这些构造函数,构造出对象来,内存就理解了。
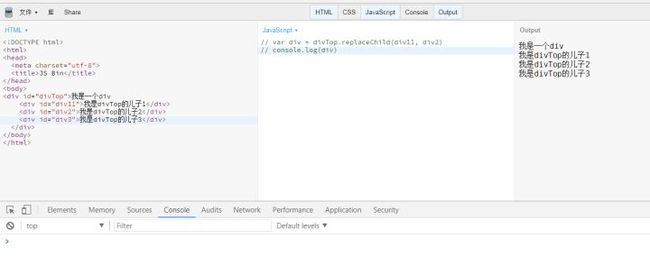
比如构造div
var div = document.createElement('div')
undefined
div
//打印结果
createElement就是构造函数。
把DOM的对应和JS基本语法联系起来。
1.2 DOM的真面目
前面的基础分析完了,就可以知道什么是DOM了。
DOM就是完整的把Document和Object映射到一起,符合DOM规范的结构,所以具备很多的API。
DOM 是 JavaScript 操作网页的接口,全称为“文档对象模型”(Document Object Model)。它的作用是将网页转为一个 JavaScript 对象,从而可以用脚本进行各种操作(比如增删内容)。
浏览器会根据 DOM 模型,将结构化文档(比如 HTML 和 XML)解析成一系列的节点,再由这些节点组成一个树状结构(DOM Tree)。所有的节点和最终的树状结构,都有规范的对外接口。所以,DOM 可以理解成网页的编程接口。DOM 有自己的国际标准,目前的通用版本是 DOM 3,下一代版本 DOM 4正在拟定中。
严格地说,DOM 不属于 JavaScript,但是操作 DOM 是 JavaScript 最常见的任务,而 JavaScript 也是最常用于 DOM 操作的语言。
规范里的DOM模型竟然有多达31个接口,我先只挑Node接口和Document接口学习。
2. 原生DOM API
DOM是一棵树,树上有Node,Node分为Document、Element、Text,其他的可以忽略。
由前面的继承图可知Node的研究价值很高,我们先来看Node接口的属性和方法。下面是MDN对Node接口的解释
Node是一个接口,许多DOM类型从这个接口继承,并允许类似地处理(或测试)这些各种类型。
以下接口都从Node继承其方法和属性:Document, Element, CharacterData (which Text, Comment, and CDATASection inherit), ProcessingInstruction, DocumentFragment, DocumentType, Notation, Entity, EntityReference
2.1 Node的属性
DOM树的最小单位就是节点(node)。文档的树形结构就是有各个不同列类型的节点组成的,每个节点都可以看做是这棵DOM树的叶子
常见的七种node类型
|名字 | 作用|
|------------|--------------------------------------|
|Document | 整个文档树的顶层节点 但不是根节点|
|DocumentType | doctype标签|
|Element | 网页的其他各种标签|
|Attribute | 标签的属性|
|Text | 标签与标签之间的文本|
|Comment | 注释|
|DocumentFragment| 文档的片段|
我们只关心Document、Element、Text
2.1.1 node之间的关系属性
- 一个最顶层的节点 document,代表整个文档。
- 一个根节点 html,是文档里面最高的一层,是根节点。其他所有的html标签都是他的下级
- 其他节点与周围节点的关系
- parentNode: 直接的那个上级的节点
- childNodes: 直接的下一级的节点
- sibling:拥有同一个父节点的节点
Node.childNodes
返回一个NodeList集合,成员包括当前节点的所有子节点。注意,除了HTML元素节点,该属性返回的还包括Text节点和Comment节点。如果当前节点不包括任何子节点,则返回一个空的NodeList集合。由于NodeList对象是一个动态集合,一旦子节点发生变化,立刻会反映在返回结果之中。
- childNodes
注意: childNodes会把text也打印出来,也就是两个标签之间的换行符。
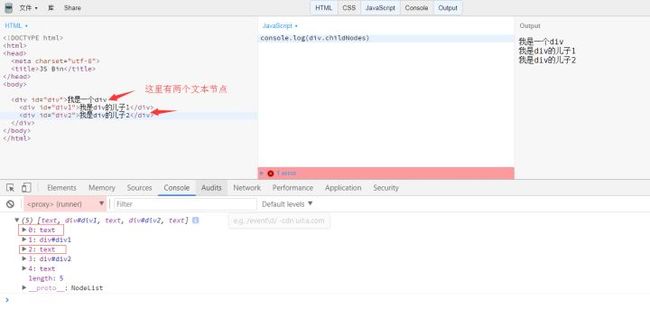
而且childNodes返回一个伪数组。这个伪数组对象的每一个元素依然都是html元素,如果想操作元素的内容还要用元素的其他属性。
- document的childNodes只有两个
document.childNodes
(2) [, html]
0:
1:html
length:2
__proto__: NodeList
- 所以我们不想打印出text节点,可以使用
children属性啊
ParentNode.children //ParentNode要是一个HTMLCollection
上述children属性会返回 一个Node的子elements 而没有text节点。
Node.firstChild和Node.lastChild
firstChild属性返回当前节点的第一个子节点,如果当前节点没有子节点,则返回null(注意,不是undefined)。
Node.lastChild属性返回当前节点的最后一个子节点,如果当前节点没有子节点,则返回null。
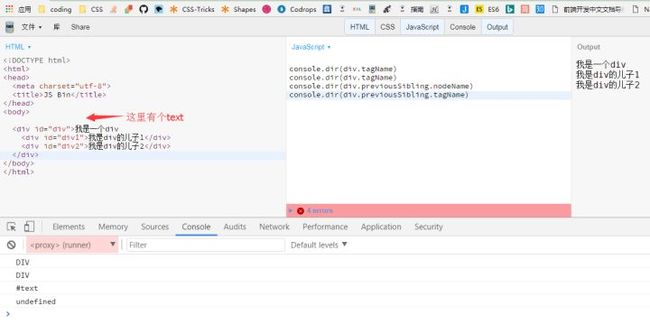
Node.nextSibling和Node.previousSibling
Node.nextSibling属性返回紧跟在当前节点后面的第一个同级节点。如果当前节点后面没有同级节点,则返回null。
previousSibling属性返回当前节点前面的、距离最近的一个同级节点。如果当前节点前面没有同级节点,则返回null。
以上的三组属性使用时一定要注意结果会有text的影响。
Node.parentNode
document.parentNode
null
parentNode属性返回当前节点的父节点。对于一个节点来说,它的父节点只可能是三种类型:element节点、document节点和documentfragment节点。
而且document节点和documentfragment节点,它们的父节点都是null。另外,对于那些生成后还没插入DOM树的节点,父节点也是null。
Node.parentElement
parentElement属性返回当前节点的父Element节点。如果当前节点没有父节点,或者父节点类型不是Element节点,则返回null。
注意: 在IE浏览器中,只有Element节点才有该属性,其他浏览器则是所有类型的节点都有该属性。
ownerDocument属性返回当前节点所在的顶层文档对象,即document对象
2.1.2 node自身的属性
nodeName和nodeType
nodeName返回node的名字,如果是element那名字是大写的,其他的名字前面写上#。nodeType返回node的类型,一般用数字表示,1表示element(也可以用Node.ELEMENT_NODE来表示),3表示text(Node.TEXT_NODE)。
- 如果是element,那么nodeName === tagName
- 如果是text,那么nodeName = #text, tagName = undefined
关于nodeType有个详细的表格,应该查看MDN记住。对照表
nodeValue
nodeValue属性返回或设置当前节点的值。对于text, comment节点来说, nodeValue返回该节点的文本内容,对于 attribute 节点来说, 返回该属性的属性值,而对于document和element节点来说,返回null。 貌似没个卵用,最常见的element都是null,还是用下面的textContent吧
textContent和innerText之争
火狐推出的textContent,获得一个节点及其后代的文本内容,一般用这个获得元素的内容。
IE推出的innerText,两者有很大的区别。
关于textContent、innerText、innnerHTML之间的区别请看MDN
2.2 Node的方法
Node.appendChild()
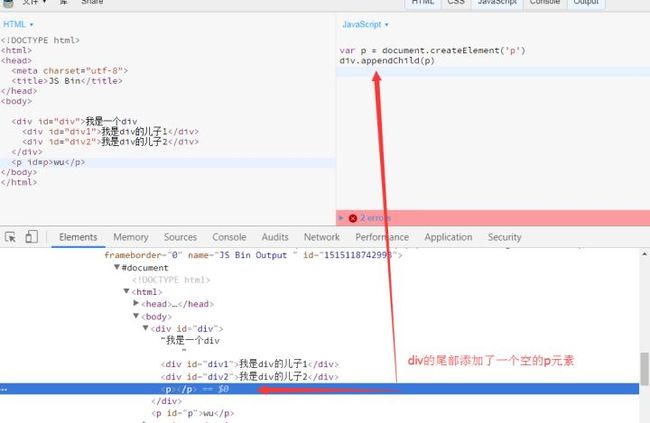
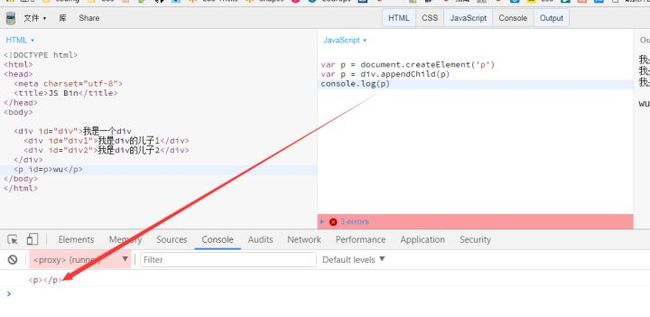
Node.appendChild() 方法将一个节点添加到指定父节点的子节点列表的末尾。
var child = node.appendChild(child);
node是要插入子节点的父节点.child即是参数又是这个方法的返回值.
Node.cloneNode()
这个方法就是克隆一个node,分为浅拷贝和深拷贝。
- 浅拷贝,
Node.cloneNode()只克隆元素节点本身,而不会克隆它的子节点。包括它的文本节点 - 深拷贝,
Node.cloneNode(true)克隆元素的所有属性以及子节点
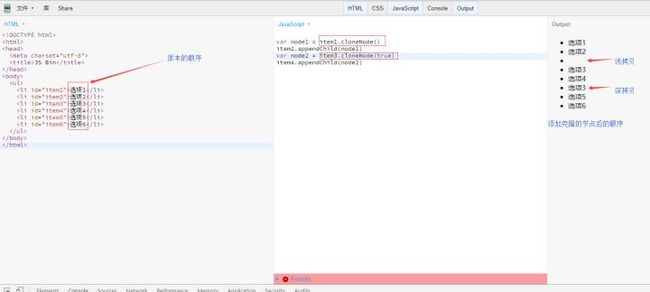
注意:为了防止一个文档中出现两个ID重复的元素,使用cloneNode()方法克隆的节点在需要时应该指定另外一个与原ID值不同的ID
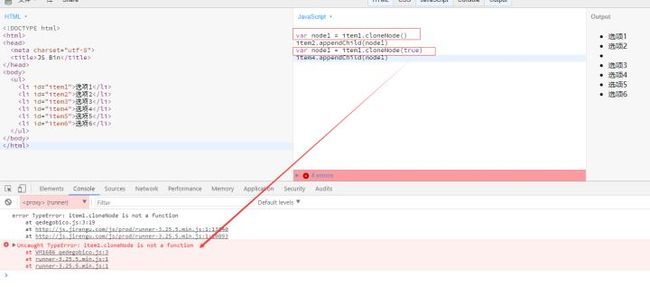
如果你想克隆同一个id的元素到不同的元素后面,会报错。
Node.contains()
判断一个节点是不是另一个节点的子节点。
div.contains(div1)
div1是div的子节点就返回true。
Node.hasChildNodes()
div.hasChildNodes()
判断div节点是否还有子节点,有子节点就返回true。
Node.insertBefore()
在当前节点的某个子节点之前再插入一个子节点。
var insertedElement = parentElement.insertBefore(newElement, referenceElement);
在parentElement节点的子节点referenceElement前面插入一个newElement节点。
如果referenceElement为null则newElement将被插入到子节点的末尾。如果newElement已经在DOM树中,newElement首先会从DOM树中移除。
没有 insertAfter 方法。可以使用 insertBefore 方法和 nextSibling 来模拟它。
parentDiv.insertBefore(sp1, sp2.nextSibling);
只要sp2.nextSibling === null,那么就可以在parentDiv的末尾添加sp1元素。
Node.isEqualNode()和Node.isSameNode()
两者都是比较两个node是否相等。不过isEqualNode()是两个node看起来相等就返回true,isSameNode()严格使用===判断,而且该方法已被废弃,如果要严格判断两个node是否指向同一个对象,直接用node1 === node2。
Node.normalize()
就是规范化的意思。什么是规范化,在一个"规范化"后的DOM树中,不存在一个空的文本节点,或者两个相邻的文本节点。
var wrapper = document.createElement("div");
wrapper.appendChild(document.createTextNode("Part 1 "));
wrapper.appendChild(document.createTextNode("Part 2 "));
// 这时(规范化之前),wrapper.childNodes.length === 2
// wrapper.childNodes[0].textContent === "Part 1 "
// wrapper.childNodes[1].textContent === "Part 2 "
wrapper.normalize();
// 现在(规范化之后), wrapper.childNodes.length === 1
// wrapper.childNodes[0].textContent === "Part 1 Part 2"
以上是MDN的例子,很好懂。
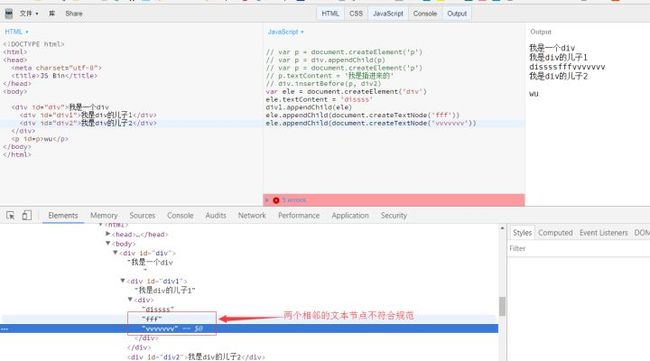
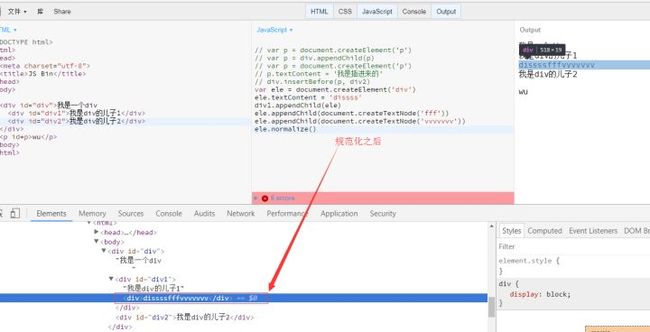
以上是自己模仿的demo
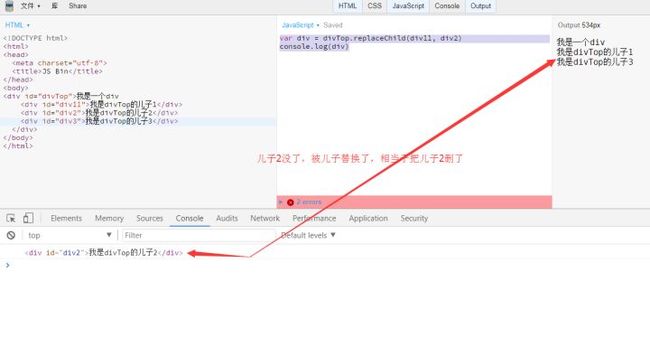
Node.removeChild()和Node.replaceChild()
Node.removeChild()是从当前节点删除一个子节点,不过内存里面依然存在,只不过不在页面显示了,返回的就是被移除的那个节点。所以说一个节点移除以后,依然可以使用它,比如插入到另一个节点下面。
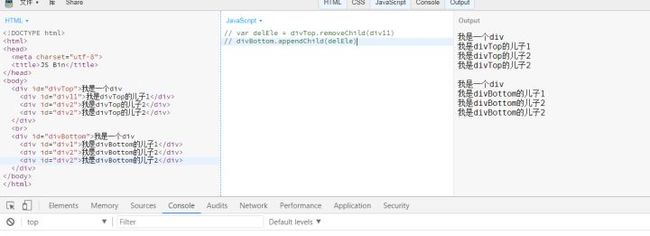
以上是我做的demo
Node.replaceChild方法用于将一个新的节点,替换掉当前节点的一个子节点。它接受两个参数,第一个参数是用来替换的新节点,第二个参数将要被替换走的子节点。它返回被替换走的那个节点。