又见程序媛 | 从索引的创建角度分析热门“面试题”
关注“数据和云”获得更多内容

关于周一 Eygle 在文章《千头万绪:从一道面试题看数据库性能和安全的方方面面》讲到的 SELECT* FROM girls WHERE age BETWEEN 18 and 24 and boyfriend='no' 这个 SQL,他 从数据库 SQL优化、数据安全、SQL审核、开发规范、IN-Memory 特性方面做了深入的分析。
结合作者的分析思路,我在创建索引思路方面又进一步的做了相关研究测试,本文主要跟大家分享一下多列统计信息和创建索引的要点。
在介绍 Oracle 优化器的多列统计信息之前,先对优化器的类型 RBO 和CBO、可选择率 Selectivy、集的势 Cardinality、统计信息做一些简要说明:
1. 优化器的概念及作用发挥
优化器是 Oracle 数据库中内置的一个核心子系统,目的是按照一定的判断原则来得到它认为的目标 SQL 在当前情形下最高效的执行计划,Oracle发展至今出现了 RBO 和CBO两种优化器。
基于规则的优化器 RBO:
RBO是Rule-Based Optimizer的缩写,直译过来是基于规则的优化器,是根据一组内置的规则从目标SQL可能的执行路径中选择一条来作为SQL的执行计划。
Oracle 会在代码中事先给各个类型的执行路径定一个等级,从1-15,对 OLTP 类型的 SQL 语句而言,通过 ROWID 访问是最高效的访问路径,而全表扫描则是最低效的访问路径。
RBO 最大的问题是它是靠硬编码在一系列固定规则中来决定 SQL 的执行计划,而没有考虑目标 SQL 所涉及的对象的实际数据量、实际数据分布等情况,比如说 RBO 认为索引范围扫描然后回表的执行计划一定优于全表扫描的执行计划,但是实际上假如某个表数据量非常少,全表扫描可能更快。
基于成本的优化器 CBO:
CBO 是 Cose-Based Optimizer 的缩写,直译过来是基于成本的优化器,CBO会根据统计信息从目标 SQL 可能的执行路径中选择成本值最小的一条作为其执行计划,这里的成本是指 Oracle 根据相关对象的统计信息估算出来的一个值。
在 Oracle 未引入系统统计信息之前,CBO 计算的成本全部是基于 I/O 估算的,引入系统统计信息之后,CBO 计算的成本值依赖于目标 SQL 的对应执行步骤的 I/O 和 CPU 消耗,这就意味 CBO 认为那些消耗系统 I/O 和 CPU 资源最少的执行路径就是最佳的执行路径。
Oracle 在 10G 后已经不再对 RBO 优化器研发和技术支持,现在谈到的优化器类型都是针对 CBO 基于成本的优化器。
2. 可选择率
Selecticity 是 CBO 特有的概念,指的是施加指定的谓词条件后返回的结果集的行数占未施加任何谓词条件的原始结果集的行数的比率,取值范围是 0-1,值越小表明可选择率越好,可选择率和成本值的估算息息相关,可选择率的值越大,意味着施加的谓词条件的选择性越不好,那么返回的 Cardinality 也就越多,估算出来的成本就越大。
例如在无直方图的情况下,等值查询列的选择率参照以下计算公式:selectivy=1/num_distinct*((num_nows-num_nulls)/num_nows)
(num_distinct指的是目标列的distinct值的数量,num_rows指的是目标列的count数,num_nulls指的是目标列null值的数量)。
3. 集的势
Cardinality 也是 CBO 特有的概念,直译过来就是集的势,表示对目标 SQL 的某个具体执行步骤返回的结果集的估算,如果某个执行步骤对应的 Cardinality 越大,那么对应的成本值往往就越大,这个执行步骤所在执行路径的总得成本值也就越大。
4. 统计信息
表的统计信息用于描述 Oracle 数据库中表的详细信息,它包含了一些典型的维度,如记录数 ROWS、表的数据块数量 BLOCKS、平均行长 AVG_ROW_LEN等,AVG_ROW_LEN 的计算方法是用目标表的所有行记录占用的字节数(不算行头)除以目标表的总行数,它可能被 Oracle 用来计算目标表所对应的结果集所占用内存的大小。
ORACLE 里的统计信息分为以下6种类型:
1 表的统计信息
2 索引的统计信息
3 列的统计信息
4 系统统计信息
5 数据字典统计信息
6 内部对象统计信息
多列统计信息
前面简单介绍了优化器的一些基础知识,现在回归到目标 SQL 语句的优化上,来看一下昨天的 SQL:
SELECT * FROM girls WHERE age BETWEEN 18 and 24 and boyfriend='no'
Oracle默认认为SQL语句where条件中的各个字段间彼此是独立没有关联关系的,所以对于AND连接的各列,where条件的组合选择率就是各个字段经过各自谓词过滤后的可选择率的乘积。上述 where 组合条件的选择率为:selectivy(age between 18 and 24) * selectivy(boyfreind='no')
因为Oracle在收集统计信息时默认只会收集各个单列的统计信息,但是表中的数据分布并不一定是严格按照各个字段的选择率来分布的。比如满足age between 18 and 24条件的数据有100万行,其中60万行是满足boyfreind='no'的,还有40万行是不满足该条件,即使此时数据列boyfriend有直方图,也无法估算出在满足age between 18 and 24条件下的数据分布比例,直方图能够给出的只是表girls的所有数据boyfriend的数据分布。
为了解决这个问题,Oracle推出了动态采样和多列统计信息能够直接估算出多列条件的选择率,而不再使用各个列的选择率来进行相乘。
我们来做一个关于多列统计信息的测试:
eygle@TEST>create table test as select trunc(dbms_random.value(18,30)) a1,trunc(dbms_random.value(0,50)) a2 from dba_objects where rownum<10001;
Table created.
使字段a1、a2有关联关系
eygle@TEST>update test set a1=a2;
10000 rows updated.
eygle@TEST>commit;
Commit complete.
eygle@TEST>exec dbms_stats.gather_table_stats(ownname=>'EYGLE',tabname=>'TEST',method_opt=>'for all columns size 1');
PL/SQL procedure successfully completed.
eygle@TEST>select COLUMN_NAME,NUM_DISTINCT,DENSITY,NUM_BUCKETS,HISTOGRAM,SAMPLE_SIZE,num_nulls from dba_tab_col_statistics where owner='EYGLE' and table_name='TEST';
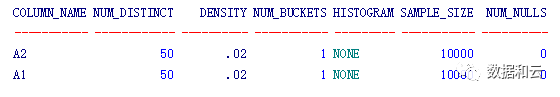
优化器估算返回的行数是4,而实际返回的数据是219
eygle@TEST>select * from TEST where a1=40 and a2=40;
219 rows selected.

我们来看看这个rows 4是如何计算而来的:
selectivy=selectivy(条件a1=40) * selectivy(条件a2=40) = (1/50) * (1/50) = 1/2500
cardinality=selectivy * num_rows = 1/2500 * 10000 = 4
查看10053也可以看到估算cardinality返回4行数据
***************************************
SINGLE TABLE ACCESS PATH
Single Table Cardinality Estimation for TEST[TEST]
SPD: Return code in qosdDSDirSetup: NOCTX, estType = TABLE
Column (#1): A1(NUMBER)
AvgLen: 3 NDV: 50 Nulls: 0 Density: 0.020000 Min: 0.000000 Max: 49.000000
Column (#2): A2(NUMBER)
AvgLen: 3 NDV: 50 Nulls: 0 Density: 0.020000 Min: 0.000000 Max: 49.000000
Table: TEST Alias: TEST
Card: Original: 10000.000000 Rounded: 4 Computed: 4.000000 Non Adjusted: 4.0000
估算cardinality返回4行数据
Scan IO Cost (Disk) = 7.000000
Scan CPU Cost (Disk) = 1842428.800000
Total Scan IO Cost = 7.000000 (scan (Disk))
+ 0.000000 (io filter eval) (= 0.000000 (per row) * 10000.000000 (#rows))
= 7.000000
Total Scan CPU Cost = 1842428.800000 (scan (Disk))
+ 510000.000000 (cpu filter eval) (= 51.000000 (per row) * 10000.000000 (#rows))
= 2352428.800000
Access Path: TableScan
Cost: 7.059244 Resp: 7.059244 Degree: 0
Cost_io: 7.000000 Cost_cpu: 2352429
Resp_io: 7.000000 Resp_cpu: 2352429
Best:: AccessPath: TableScan
Cost: 7.059244 Degree: 1 Resp: 7.059244 Card: 4.000000 Bytes: 0.000000
***************************************
而实际上表中的数据分布并不如此,我们前面对a1和a2做了关联update test set a1=a2,换句话说就是a1=40的数据中a2也是等于40的。
为表中有关联关系的列 a1 和 a2 创建组合列并收集多列统计信息:
eygle@TEST>exec dbms_stats.delete_table_stats(ownname=>'EYGLE',tabname=>'TEST');
PL/SQL procedure successfully completed.
eygle@TEST>declare
2 cg_name varchar2(32);
begin cg_name:=sys.dbms_stats.create_extended_stats(ownname=>'EYGLE',tabname=>'TEST',extension=>'(a1,a2)');
4 end;
5 /
PL/SQL procedure successfully completed.
eygle@TEST>exec dbms_stats.gather_table_stats(ownname=>'EYGLE',tabname=>'TEST',method_opt=>'for all columns size 1');
PL/SQL procedure successfully completed.
Oracle 在 test 表上已经创建了一个名为SYS_STU$BSXWYIMOAA45XM0L_V4R6D 的组合列,可以从dba_stat_extensions 中查到关于目标表中组合列的详情
eygle@TEST>select extension_name,extension from dba_stat_extensions where table_name='TEST';

优化器默认将多列组合的伪列信息写入到数据字典中
eygle@TEST>select COLUMN_NAME,NUM_DISTINCT,DENSITY,NUM_BUCKETS,HISTOGRAM,SAMPLE_SIZE from dba_tab_col_statistics where owner='EYGLE' and table_name='TEST';

创建多列统计信息后估算的返回行数是200,与实际返回的行数219非常接近
eygle@TEST>select * from TEST where a1=40 and a2=40;
219 rows selected.
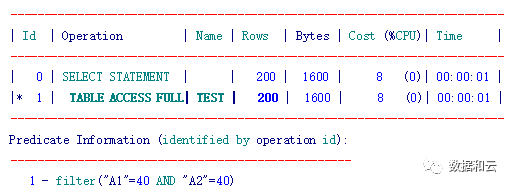
查看10053:
***************************************
SINGLE TABLE ACCESS PATH
Single Table Cardinality Estimation for TEST[TEST]
SPD: Return code in qosdDSDirSetup: NOCTX, estType = TABLE
Column (#1): A1(NUMBER)
AvgLen: 3 NDV: 50 Nulls: 3 Density: 0.020000 Min: 0.000000 Max: 49.000000
Column (#2): A2(NUMBER)
AvgLen: 3 NDV: 50 Nulls: 3 Density: 0.020000 Min: 0.000000 Max: 49.000000
Column (#3): SYS_STU$BSXWYIMOAA45XM0L_V4R6D(NUMBER)
AvgLen: 12 NDV: 50 Nulls: 3 Density: 0.020000 多列a1、a2的density是0.02,NDV50表示有50个不同值
ColGroup (#1, VC) SYS_STU$BSXWYIMOAA45XM0L_V4R6D
Col#: 1 2 CorStregth: 50.00
ColGroup Usage:: PredCnt: 2 Matches Full: #1 Partial: Sel: 0.019994
Table: TEST Alias: TEST
Card: Original: 10003.000000 Rounded: 200 Computed: 200.000000 Non Adjusted: 200.000000 估算cardinality返回200行数据
Scan IO Cost (Disk) = 8.000000
Scan CPU Cost (Disk) = 1871424.560000
Total Scan IO Cost = 8.000000 (scan (Disk))
+ 0.000000 (io filter eval) (= 0.000000 (per row) * 10003.000000 (#rows))
= 8.000000
Total Scan CPU Cost = 1871424.560000 (scan (Disk))
+ 510153.000000 (cpu filter eval) (= 51.000000 (per row) * 10003.000000 (#rows))
= 2381577.560000
Access Path: TableScan
Cost: 8.059978 Resp: 8.059978 Degree: 0
Cost_io: 8.000000 Cost_cpu: 2381578
Resp_io: 8.000000 Resp_cpu: 2381578
Best:: AccessPath: TableScan
Cost: 8.059978 Degree: 1 Resp: 8.059978 Card: 200.000000 Bytes: 0.000000
***************************************
结论:
通过以上测试可以看出,在对有关联关系的两个列A1、A2做了组合列并对其收集多列统计信息后,Oracle可以根据多列的统计信息评估出多列条件的可选择率,相比单列可选择率相乘会更加准确。
创建索引的要点
上面我们简单介绍了多列统计信息,那么关于SQL语句
select * from girls where age between 18 and 24 and boyfreind='no'应该如何创建索引?
有以下几种思路:
1 创建age单列索引+boyfriend单列索引
2 创建age+boyfriend组合索引
3 创建boyfriend+age组合索引
分别测试以上几种情况:
eygle@TEST>create table girls (age number,boyfriend varchar2(32));
Table created.
eygle@TEST>select age,boyfriend,count(*) from girls group by age,boyfriend order by age;
AGE BOYFRIEND COUNT(*)
---------- ------------------------------ ----------
0 yes 493502
1 yes 493154
2 yes 492928
3 yes 493204
4 yes 493017
5 yes 492835
6 yes 493319
7 yes 493825
8 yes 492328
9 yes 494090
10 yes 493264
11 yes 494120
12 yes 493524
13 yes 493997
14 no 1
14 yes 494402
15 no 1
15 yes 492978
16 no 1
16 yes 494116
17 no 1
17 yes 1
18 no 1
18 yes 1
19 no 1
19 yes 1048576
20 no 1
20 yes 1
21 no 1
21 yes 1
22 no 1
22 yes 1
23 no 1
23 yes 1
24 no 1
24 yes 1
25 no 1048576
25 yes 1
26 no 1
26 yes 1
27 no 1
27 yes 1
28 no 1
28 yes 1
29 no 1
29 yes 1
30 no 1
30 yes 1
1. 创建单列索引age和单列索引boyfriend
在执行计划中可以看到index$_join$_001,也就是使用到了索引合并。
这里解释一下index_join,这是一个针对单表的hint,目的是让优化器对目标表上的多个索引执行索引合并操作,index_join能够成立的前提条件是查询的所有列都能够从目标表的索引中获的,即通过扫描目标表的索引就可以得到所有查询列而不用回表。index join hint的格式如下所示:
/*+ index_join(目标表 目标索引1 目标索引2...目标索引n) */
/*+ index_join(目标表) */
select * from girls where age between 18 and 24 and boyfriend='no';能走上索引合并是因为girls表只有两列age和boyfriend,而这两列都可以从girls表的两个索引中获得;如果girls表有其他列,那么就没法走上index join了,可能就会走上index merge或者其他的执行计划,这又是另外一个问题了。
我们来分析一下index join的具体过程:首先分别扫描目标表中指定的索引IDX_GIRLS_AGE和IDX_GIRLS_BOYFRIEND,得到的结果集分别计做结果集1和结果集2,然后将这两个结果集做hash连接,连接条件就是(结果集1.ROWID=结果集2.ROWID),这样得到的最终连接结果就是SQL执行的结果。
可以结合下面的图片理解:
步骤1:扫描索引1,条件是age between 18 and 24,结果集记为结果集1
步骤2:扫描索引2,条件是boyfriend=no,结果集记为结果集2
步骤3:将结果集1和结果集2按照rowid做hash连接,取出合适的数据

eygle@TEST>create index idx_girls_age on girls(age);
Index created.
eygle@TEST>create index idx_girls_boyfriend on girls(boyfriend);
Index created.
eygle@TEST>select /*+ index_join(girls,idx_girls_age,idx_girls_boyfriend) */ * from girls where age between 18 and 24 and boyfriend='no';
7 rows selected.
Elapsed: 00:00:02.49

2. 创建age + boyfriend组合索引
从执行计划中可以看到在索引的前缀字段age传入的是范围值的情况下,后缀字段boyfriend='no'会在access和filter中都出现(access方式是指根据该行执行计划的执行方式去定位记录,而filter方式是指在该执行方式完毕后再次过滤数据)。
那么为什么boyfriend='no'会同时出现在access和filter中呢?下面我们用目标SQL来分析一下:
在用where age between 18 and 24 and boyfriend='no'条件进行索引范围扫描时,Oracle会首先定位到age=18和boyfriend='no'的叶块位置,从左往右对叶块进行遍历,一直到大于(age=24和boyfriend='no')的第一个索引键值出现才结束遍历。
但是这个索引范围查询的遍历过程中会有{age=18 and boyfriend='yes'}、{age=19 and boyfriend='yes'}......{age=24 and boyfriend='yes'}等索引键值存在,而这些索引键值都是不满足boyfriend='no'的条件的,所以需要对索引范围扫描的结果再次进行filter过滤boyfriend='no'。
可以参考下面的图片理解:
步骤1:扫描符合(age between 18 and 24) 的数据,boyfriend=no用来共同确定范围扫描的起点
步骤2:扫描出来的结果集再用boyfriend=no过滤数据

那么为什么当出现了前缀字段的范围查询,后缀字段的查询条件就失去意义呢?这与索引的结构有关:索引的树形结构使得索引支持等值查询,也就是通过索引的根节点、树枝节点最终定位到索引的叶子节点,而索引的相邻叶子节点之间是双向链表结构,使得索引范围扫描可以实现。当索引根据前缀字段开始范围扫描时,显然没有办法根据后缀字段的值在链表结构中跳跃执行,因此后缀的限制条件只能变成FILTER过滤条件。
eygle@TEST>create index idx_girls_ageboy on girls(age,boyfriend);
Index created.
eygle@TEST>select /*+ index(girls,idx_girls_ageboy) */ * from girls where age between 18 and 24 and boyfriend='no';
7 rows selected.
Elapsed: 00:00:00.85

将范围查询等价改写为IN
Eygle 周一的文章中说假设 age 是整数的话,可以将 between and 改写为 in,下面我们来测试一下:可以看到使用IN查询的时候优化器将IN等价改成成了OR,走了INLIST ITERATOR的执行计划。INLIST ITERATOR是Oracle处理IN后面是常量集合的一种方法,此时优化器会遍历IN后面的常量的每一个值然后做比较,看结果集中是否存在和这个值匹配的记录。如果索引的前缀字段是数量不多的IN查询,那么执行计划会变成INLIST ITERATOR方式的扫描,方式类似循环中的相等条件查询。
INLIST ITERATOR相当于将select * from girls where age in(18,19,20,21,22,23,24) and boyfriend='no';等价改写为select * from girls where (age=18 and boyfriend='no') or (age=19 and boyfriend='no') or ...... or (age=24 and boyfriend='no'),可以参考以下图片理解。

eygle@TEST>select /*+ index(girls,idx_girls_ageboy) */ * from girls where age in(18,19,20,21,22,23,24) and boyfriend='no';
7 rows selected.
Elapsed: 00:00:00.03

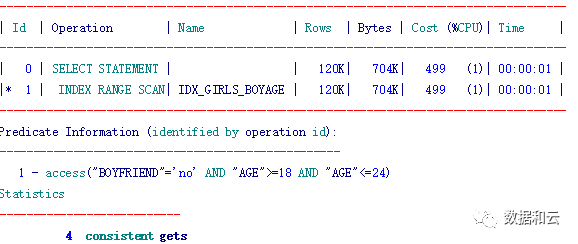
3. 创建boyfriend + age组合索引
索引的前缀字段boyfriend是等值,后缀字段age也可以走上索引的access扫描方式,对比age + boyfriend组合索引逻辑读、执行时间降低明显。
可以参考下面的图片理解:
直接扫描符合boyfriend =no and (age between 18 and 24)的数据

eygle@TEST>create index idx_girls_boyage on girls(boyfriend,age);
Index created.
eygle@TEST>select /*+ index(girls,idx_girls_boyage) */ * from girls where age between 18 and 24 and boyfriend='no';
7 rows selected.
Elapsed: 00:00:00.02
各种创建索引方式逻辑读消耗对比如下:
索引方式 |
查询字段类型 |
逻辑读 |
执行时间 |
单列索引age+单列索引boyfriend |
age范围查询,boyfriend等值 |
6777 |
2.49秒 |
age+boyfriend组合索引 |
age范围查询,boyfriend等值 |
4621 |
0.85秒 |
age IN查询, boyfriend等值 |
17 |
0.03秒 |
|
boyfriend+age组合索引 |
age范围查询,boyfriend等值 |
4 |
0.02秒 |
综上所述,在创建索引的时候:
如果查询的列都可以从表中各个索引中获取,尽量将这些索引改造成组合索引
为什么组合索引相比单列索引大部分情况下都要高效呢?这是因为组合索引中保存了索引键值按照顺序存放的所有列,直接在索引键值上多列进行过滤筛选,无论是access还是filter;
而多个单列索引合并的时候,是需要在多个索引段之间进行跳跃的,而且假设满足age=18的条件有1行,满足boyfriend=no的条件有1000行,将这两个结果集根据rowid=rowid做关联后的结果集只有1行,最坏的情况是age=18的这一行在boyfriend列的最后面,这样需要扫描完boyfriend的1000行才能找到需要的数据,这种情况下单列索引再合并效果会很低。
尽量将等值查询字段作为索引前缀,范围查询的字段放在索引字段的最后
如果范围查询的字段查询的范围比较小的话可以改写为IN,这样可以走上INLIST ITERATOR的执行计划
原创:刘娣
投稿:有投稿意向技术人请在公众号对话框留言。
转载:意向文章下方留言。
更多精彩请关注 “数据和云” 公众号 。
资源下载
关注公众号:数据和云(OraNews)回复关键字获取
2018DTCC , 数据库大会PPT
2017DTC,2017 DTC 大会 PPT
DBALIFE ,“DBA 的一天”海报
DBA04 ,DBA 手记4 电子书
122ARCH ,Oracle 12.2体系结构图
2017OOW ,Oracle OpenWorld 资料
PRELECTION ,大讲堂讲师课程资料
近期文章仅仅使用AWR做报告? 性能优化还未入门
实战课堂:一则CPU 100%的故障分析
杨廷琨:如何编写高效SQL(含PPT)
一份高达555页的技术PPT会是什么样子?
大象起舞:用PostgreSQL解海盗分金问题
ProxySQL!像C罗一样的强大
高手过招:用SQL解决环环相扣刑侦推理问题
