记一次 Redis Cluster 宕机引发的事故
关注我们,获得更多资源

导读:
Redis官方号称支持并发11万读操作,并发8万写操作。由于优异的性能和方便的操作,相信很多人都在项目中都使用了Redis,为了不让应用过分的依赖 Redis服务,Redis的作用只作为提升应用并发和降低应用响应时间存在,即使Redis出现异常,应用程序也不应该出现提供服务失败问题,对此拍拍信最近安排了一次全环境的Redis Cluster 宕机演练。
许彬:拍拍信架构负责人。
朱荣松:拍拍信架构开发工程师。
一、演练过程
Redis 集群环境:
1. 测试环境:
Redis Cluster 配置 :Redis 3主 3从 一共6个节点。
2. 预发环境:
Redis Cluster 配置 :Redis 3主 3从 一共6个节点。
下面是我们操作的时间线:
第一天
程序运行中关闭任意一台从节点,测试一天均无异常。
第二天
程序运行中关闭任意一台从节点,程序未发现异常,测试一天未发现异常。
第三天
预发环境有应用发版,出现异常程序无法启动。
……
二、问题描述
首先说明几个前提:
1. 测试与预发环境目前关闭的都是任意一台Redis从节点。
2. 测试环境经过反复测试无问题才开始关闭预发环境节点。
3. 预发环境重启被关闭的Redis节点后异常消失。
4. 连接Redis客户端使用的是Java语言中使用范围较广的Jedis。
那么为什么测试环境在经过反复测试没有问题,到预发环境会出现问题?
三、原理
分析问题前先简单解释下Redis Cluster实现原理。简单来说Redis Cluster中内置了 16384 个哈希槽,当需要在 Redis Cluster中存取一个 key或者value时,Redis 客户端先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数( 算法为:crc16(key)mod 16384),这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,值得注意的是这个计算key是在哪个槽上的操作是Redis 客户端做的操作,Java中常用的客户端为Jedis 这个也是被Spring推荐的一种客户端。
注: 如果有人好奇为什么Redis Cluster为什么会使用16384也就是2^14个槽。可以查看 Githubhttps://github.com/antirez/redis/issues/2576作者对此进行了解释。
四、分析
首先是查看程序启动异常信息,下图1为程序异常信息。
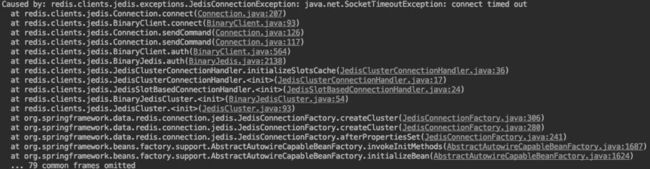
图1异常很明显抛出的是连接异常
查看了Jedis的源码后发现初始化Redis Cluster的槽信息时,调用initializeSlotsCache()方法时出现异常。图2 为此方法的具体实现,分析代码发现此代码的目的应该是需要cache Redis Cluster槽信息,由于代码中有break,所以是只需要连接Redis获取一次信息即可。细一看此代码应该是有Bug,Try 的范围没有覆盖到Jedis连接的操作,如果Jedis连接失败直接抛出连接失败异常,此循环会直接退出,与代码实际预期不符合。
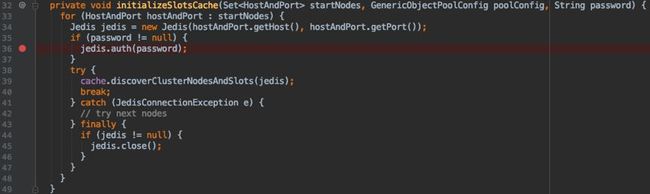
图2
由此引发另一个思考,是不是我关闭的节点正好为循环的第一个节点导致此问题。尝试关闭另外一台从节点后程序正常启动。那么Jedis加载的节点顺序是什么,似乎Jedis对节点顺序进行了排序操作。在查看源码后发现Jedis重写了Redis节点配置类的hashCode方法。

图3
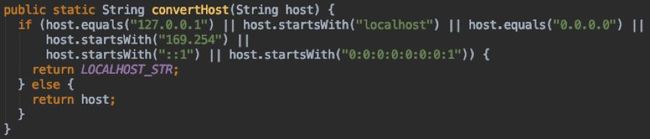
图4
下面简单测试下如果配置为:jedis-01.test.com、jedis-02.test.com、jedis-03.test.com、jedis-04.test.com、jedis-05.test.com、jedis-05.test.com输出顺序是什么。
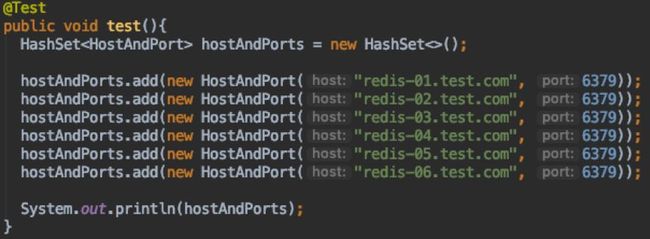
图5
输出结果:
[redis-06.test.com:6379,redis-04.test.com:6379, redis-01.test.com:6379, redis-03.test.com:6379, redis-02.test.com:6379,redis-05.test.com:6379]
也就是说如果关闭redis-06.test.com:6379这台节点,程序就会出现启动失败问题。
五、解决
问题定位后首先去Github上的查看相关问题是否有人遇到,在查询后发现此问题有人在去年11月提了PR解决了此问题,链接如下:
https://github.com/xetorthio/jedis/pull/1633
官方目前释放出了2.10.0-m1和3.0.0-m1中解决了此问题,但是由于不是Release版本使用还得注意。解决的办法为图6,和图2对比可以发现图6对Jedis的实例化也进行了try catch。
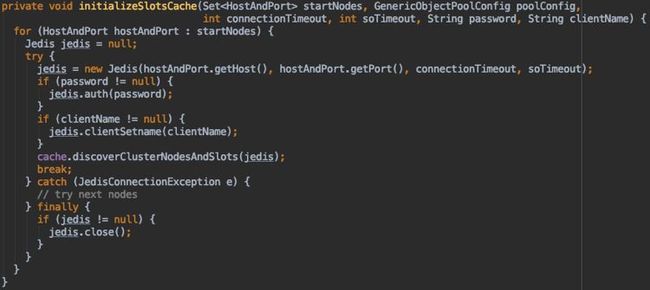
图6
六、思考
Redis Cluster由于使用去中心化思想 ,图7 显示了Redis Cluster集群的状态,所以Redis Cluster 中如果有部分节点异常就会导致整个集群异常。
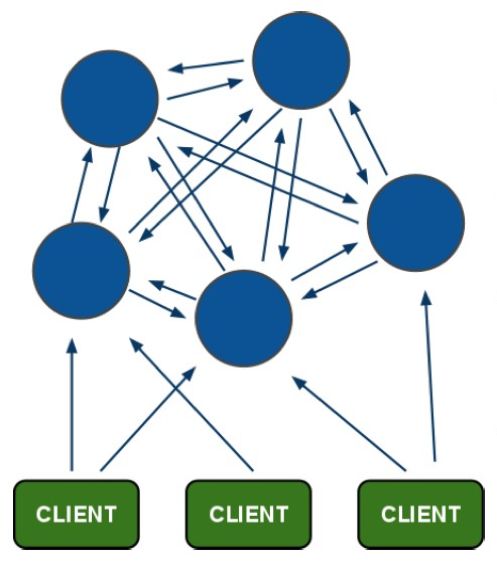
图7
那么问题来了多少节点异常会导致程序读写操作出现异常,下面我们也做了个简单的测试用于统计程序运行中,关闭Redis节点后程序的出错情况,以下测试表1仅供参考。
场景 |
操作(多节点均同时操作) |
Redis写总量 |
Redis读总量 |
错误量 |
总耗时(s) |
错误率 |
程序运行中 |
关主(关任一主) |
100000 |
100000 |
3084 |
100 |
0.031 |
关主(关任一主) |
100000 |
100000 |
1482 |
102 |
0.015 |
|
关主(关任一主) |
100000 |
100000 |
3053 |
97.6 |
0.031 |
|
关从(关任一从) |
100000 |
100000 |
0 |
109.2 |
0 |
|
关从(关任一从) |
100000 |
100000 |
0 |
90.1 |
0 |
|
关从(关任一从) |
100000 |
100000 |
0 |
88.9 |
0 |
|
主从一起关(关任一对) |
100000 |
100000 |
32613 |
210.1 |
0.326 |
|
主从一起关(关任一对) |
100000 |
100000 |
29148 |
169.8 |
0.291 |
|
主从一起关(关任一对) |
100000 |
100000 |
32410 |
173.7 |
0.324 |
|
所有主全关 |
100000 |
100000 |
100000 |
353.4 |
1 |
|
所有从全关 |
100000 |
100000 |
0 |
87.7 |
0 |
|
只留一台主 |
100000 |
100000 |
100000 |
357.1 |
1 |
表1
从测试结果看,集群Master的选举过程是由Master参与选举的。
1. 如果半数以上 Master 处于关闭状态那么整个集群处于不可用状态。
2. 关闭任意一对主从节点会导致部分(大约为整个集群的1/3)失败。
3. 关闭任意一主,会导致部分写操作失败,是由于从节点不能执行写操作,在Slave升级为Master期间会有少量的失败。
4. 关闭从节点对于整个集群没有影响。
转载自:技术琐话。
资源下载
关注公众号:数据和云(OraNews)回复关键字获取
2018DTCC , 数据库大会PPT
2018DTC,2018 DTC 大会 PPT
DBALIFE ,“DBA 的一天”海报
DBA04 ,DBA 手记4 电子书
122ARCH ,Oracle 12.2体系结构图
2018OOW ,Oracle OpenWorld 资料
PRELECTION ,大讲堂讲师课程资料
近期文章企业数据架构的云化智能重构和变革(含大会PPT)
Oracle研发总裁Thomas Kurian加盟Google Cloud
变与不变: Undo构造一致性读的例外情况
Oracle 18c新特性:动态 Container Map 增强 Application Container 灵活性
Oracle 18c新特性:Schema-Only 帐号提升应用管理安全性
Oracle 18c新特性:多租户舰队 CDB Fleet (含PPT)
为什么看了那么多灾难,还是过不好备份这一关?
