数据结构与算法--静态链表
链表的实现依赖于指针(在Java中称作对象引用可能更准确),如果某编程语言没有指针呢?那就只好使用数组来实现咯。数组里的每一个元素都对应一个由data和next组成的对象。data存放该结点的数据,next存放下一个结点所在的数组下标,链表末尾是例外,其next为0,指示着这是链表的最后一个结点了。这和单链表中Node的定义差不多嘛。只不过变成了下面这样。
private class Node {
E data;
int next;
}
那么这个数组则可以表示成Node,其中Item是静态链表的泛型参数,如下。由于Node是内部类,为了不至于混淆,Node使用了E而不是Item。当然Node也可以指定成static。
public class StaticLinkedList- implements Iterable
- {}
像这种由数组描述的链表,叫做静态链表;由于数组初始化必须指定长度,所以和其他链表实现相比,静态链表的容量固定。除非使用类似resize的方法在需要的时候调整容量。
和之前单链表、双向链表的Node类不一样,这次Node也添加了泛型参数,直接使用StaticLinkedList的泛型参数不可以吗?我们来看
private class Node {
Item data;
int next;
}
private Node[] a = new Node[capacity]; // Error, Generic Array Creation
如果Node没有指定泛型参数,那么数组应该像最后一行那样创建,然而这会报错,原因是创建泛型数组,因为Node里的data是泛型变量。所以还是乖乖加上吧,那数组的创建应该变成下面代码最后一行那样。有警告,可不必理会。需要注意的是,注释里面的两种数组初始化方法是错误的。
private class Node {
E data;
int next;
}
private Node- [] a = (Node
- []) new Node[capacity]; // Uncheked, from Node[] to Node
- []
// private Node
- [] a = new Node<>[capacity];
// private Node
- [] a = new Node
- [capacity];
此时数组只是规定了大小,里面其实还没有内容。所以需要进行初始化,用new Node<>填充数组的每一个位置。data域初始化为null就行,next域的初始化就有讲究了。按照约定,数组的第一个位置a[0]和最后一个位置a[length - 1]不表示结点,不仅data为null,next表达的意义也比较特殊。如果将未使用的数组元素称为备用链表,那么a[0]的next始终指向备用链表第一个结点的下标——也就是第一个空闲元素的下标。a[length - 1]的next始终指向链表第一个结点的下标。由于刚开始还没有结点,链表为空。所以a[0].next自然是第一个空闲元素a[1]的下标1,a[length - 1].next则应该等于0,为什么是0下面会解释。
private Node- [] a;
// 初始化数组
public StaticLinkedList(int capacity) {
a = (Node
- []) new Node[capacity];
for (int i = 0; i < capacity - 1; i++) {
a[i] = new Node<>();
a[i].next = i + 1;
}
a[capacity - 1] = new Node<>();
a[capacity - 1].next = 0;
}

还是先给出全部代码,再一一解释吧。
package Chap3;
import java.util.Iterator;
/**
* 可以使用数组代替指针(一般不这样做)。数组的每个元素包含两个值,一个是data,另外一个是下一元素的下标值
* 由于是数组实现,故长度固定
*/
public class StaticLinkedList- implements Iterable
- {
private class Node
{
E data;
int next;
}
private int N;
private Node- [] a;
public boolean isEmpty() {
return N == 0;
}
public int size() {
return N;
}
// 初始化数组
public StaticLinkedList(int capacity) {
a = (Node
- []) new Node[capacity];
for (int i = 0; i < capacity - 1; i++) {
a[i] = new Node<>();
a[i].next = i + 1;
}
a[capacity - 1] = new Node<>();
a[capacity - 1].next = 0;
}
public StaticLinkedList(Item... items) {
this(512);
for (Item item : items) {
add(item);
}
}
private int getSpace() {
// a[0]的next所指就是第一个空闲元素的下标
int i = a[0].next;
a[0].next = a[i].next;
return i;
}
private void checkRange(int index) {
if (index < 0 || index >= N) {
throw new IndexOutOfBoundsException(index + "");
}
}
private void checkRangeForInsert(int index) {
if (index < 0 || index > N) {
throw new IndexOutOfBoundsException(index + "");
}
}
private Node
- index(int index) {
// 最后一个元素的next就是第一个结点所在的下标
int k = a.length - 1;
for (int i = 0; i <= index; i++) {
k = a[k].next;
}
return a[k];
}
public void insert(int index, Item item) {
checkRangeForInsert(index);
// 即使index为0,也能正确处理
Node
- e = index(index - 1);
int i = getSpace();
a[i].data = item;
// 表示新结点的下一个结点为插入处
a[i].next = e.next;
// 表示插入处前一结点的下一个结点变成了新插入的结点
e.next = i;
N++;
}
public Item get(int index) {
checkRange(index);
Node
- e = index(index);
return e.data;
}
public void set(int index, Item item) {
checkRange(index);
Node
- e = index(index);
e.data = item;
}
public Item remove(int index) {
checkRange(index);
// 移除和插入一样需要定位到前一元素
Node
- e = index(index - 1);
int j = e.next;
Item item = a[e.next].data;
// 帮助垃圾回收
a[e.next].data = null;
// p.next = p.next.next
e.next = a[e.next].next;
// 这里不要填入e.next,因为在上句已经被改变
freeSpace(j);
N--;
return item;
}
// 让被移除的位置成为下一个插入的位置
private void freeSpace(int index) {
// 表示index之后才轮到原备用表第一个元素
a[index].next = a[0].next;
// 再将备用表第一个元素换成被删除的位置。优先填入这个后,再填入上步中原来的备用表第一位置
a[0].next = index;
}
// 链表的末尾插入
public void add(Item item) {
int index = a.length - 1;
// 到0表示链表的末尾
while (a[index].next != 0) {
index = a[index].next;
}
int i = getSpace();
a[i].data = item;
// 找出最后一个元素, 将最后一个结点的下标给
a[index].next = i;
// 末尾元素的next为0
a[i].next = 0;
N++;
}
// 链表的开头插入
public void push(Item item) {
int i = getSpace();
a[i].data = item;
a[i].next = a[a.length - 1].next;
a[a.length - 1].next = i;
N++;
}
// 弹出表头
public Item pop() {
int index = a[a.length - 1].next;
Item item = a[index].data;
a[a.length - 1].next = a[index].next;
// 帮助垃圾回收
a[index].data = null;
freeSpace(index);
N--;
return item;
}
public void clear() {
for (int i = 0; i < a.length - 1; i++) {
a[i].next = i + 1;
a[i].data = null;
}
a[a.length - 1].next = 0;
a[a.length - 1].data = null;
N = 0;
}
public int indexOf(Item item) {
int index = 0;
if (item != null) {
for (int i = a[a.length - 1].next; i != 0; i = a[i].next) {
if (a[i].data.equals(item)) {
return index;
}
index++;
}
} else {
for (int i = a[a.length - 1].next; i != 0; i = a[i].next) {
if (a[i].data == null) {
return index;
}
index++;
}
}
return -1;
}
public boolean contains(Item item) {
return indexOf(item) >= 0;
}
@Override
public Iterator
- iterator() {
return new Iterator
- () {
int index = a[a.length - 1].next;
@Override
public boolean hasNext() {
return index != 0;
}
@Override
public Item next() {
Item item = a[index].data;
index = a[index].next;
return item;
}
};
}
@Override
public String toString() {
Iterator
- it = iterator();
if (!it.hasNext()) {
return "[]";
}
StringBuilder sb = new StringBuilder();
sb.append("[");
while (true) {
Item item = it.next();
sb.append(item);
if (!it.hasNext()) {
return sb.append("]").toString();
}
sb.append(", ");
}
}
public static void main(String[] args) {
StaticLinkedList
a = new StaticLinkedList<>(1000);
a.push("123");
a.push("456");
a.push("789");
a.clear();
a.push("456");
a.push("123");
a.add("789");
a.add("10");
a.remove(1); // 456
a.pop(); // 123
System.out.println(a.get(1)); // 10
a.set(1, "1011");
a.insert(0, "234");
a.insert(2, "456");
System.out.println(a.contains("789")); // true
System.out.println(a.size()); // 4
for (String each : a) {
System.out.println(each);
}
System.out.println(a.indexOf("1011")); // 3
StaticLinkedList b = new StaticLinkedList<>(1, 2, 32, 434);
System.out.println(b);
}
}
首先是范围检查,访问链表时候当然是限定在[0, N - 1]。如checkRange方法那样。不过插入操作时,略有不同。我们允许在链表的末尾插入结点,即允许在a[N]处插入。所以在checkRangeForInsert当index == N并不会抛出异常。
再就是定位方法了,Node方法返回index处的Node对象。它甚至能正确处理index(index - 1)时,index 为0的情况,此时index(-1)返回的是数组最后一个元素,我们知道该元素的next才指向第一个结点。
get、set方法主要就是用了index方法实现,比较简单就不讲了。
当添加结点的时候,放进数组的哪个位置呢,自然是备用链表的第一个元素了。同时备用链表的第二个元素变成了第一个元素。用代码表示如下
private int getSpace() {
// a[0]的next所指就是第一个空闲元素的下标
int i = a[0].next;
a[0].next = a[i].next;
return i;
}

相应的,当有结点被移除,被移除处成为优先插入位置,即如有新结点要插入,先插入到刚刚被移除结点的位置,接着再插入到原备用链表的第一个元素处。
// 让被移除的位置成为下一个插入的位置
private void freeSpace(int index) {
// index的下一个才是原备用链表第一个空闲元素
a[index].next = a[0].next;
// 备用链表变成:第一个空闲元素为index处
a[0].next = index;
}

来看push方法,先获得备用链表的第一个空闲位置。因为是在表头插入,所以新结点的next指向原链表的第一个结点(即数组最后一个元素的next处所在结点),接着数组最后一个元素的next应该变成新结点的下标。如果第一次添加结点到链表中,那么这个元素也是链表的尾结点。由于刚初始化后数组a的最后一个元素的next为0,根据push的实现,新结点的next为0。这和我们定义的链表尾结点的next约定为0符合,所以现在知道为什么初始化的时候要令a[capacity - 1].next = 0了吧。同时数组最后一个元素的next指向新插入结点的下标。

对于add方法也一样适用,第一次添加结点的时候,while循环不会执行,最后一个元素的next指向刚添加结点的下标,手动将第一个结点的next置为0;对于之后的add操作,则是通过while循环找到链表的尾结点,该结点的next指向新结点的下标,表示刚添加的结点成为了新的尾结点。再手动将尾结点的next置为0。

然后是pop方法,用index变量保存了第一个结点的索引,一会儿要调用freeSpace来更新备用链表。然后数组最后一个元素的next指向原链表的第二个结点,这样它也就成了链表的第一个结点。

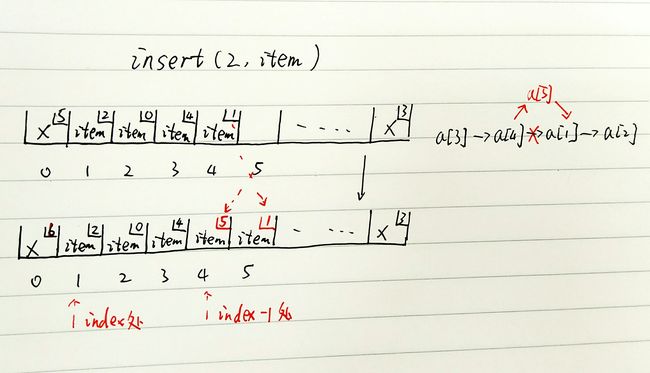
insert方法,可以在链表尾结点之后的a[N]处插入。先定位到插入处的前一个结点index - 1处,因为新插入的结点实际上会位于index -1与index之间。让新结点的next指向index处的结点,再让index - 1处的结点的next指向新结点。同样这两句的顺序不能反。因为如果先执行第二句,e.next的值就已经改变了,造成逻辑混乱,插入失败。
a[i].next = e.next;
e.next = i;
remove方法,同样需要定位到插入处的前一个结点index - 1处。只需让index - 1处的结点的next直接连上index的下一个结点就行了(跳过了index处的结点)。因为有结点被移除,所以调用freeSpace更新备用链表。

clear方法就是把数组中每个Node对象的data置为null,然后重新初始化next的值至空链表时的样子。
注意indexOf和iterator方法,它们遍历整个链表的方式其实是一样的。从第一个结点即a[a.length - 1].next处开始,只要当前结点的下标不为0,就说明还没有遍历到链表末尾,继续循环。试想在尾结点处,index还不为0,访问到这个结点后,下一次index = a[index].next = 0,条件不满足,所以循环终止,刚好把整个链表遍历了一遍。
虽然静态链表是数组实现的,但是本质上它还是链表。什么意思?我们确实是划分了一段连续的内存空间没错,但并不是按照数组下标顺序存储的。举个例子,a[5]可能存的是链表的第一个结点,a[2]存的链表第二个结点,a[4]可能存的又是链表的最后一个结点...很多种情况。其实这些结点的位置还是分散的,不论位于数组中哪个位置都可以,只要能确定它下一个结点位于数组的哪个位置,最终还是能写出链表的正确顺序(虽然在数组中看是跳跃的)。所以set、get方法时间复杂度还是和单链表一样是O(n),
可以看出用数组实现链表挺麻烦的,如果可以使用指针或对象引用的方式,就最好不要数组来实现了...
by @sunhaiyu
2017.8.8