【caffe源码研究】第三章:源码篇(4) :Solver
一个典型的solver文件如下
# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: CPUSolver通过协调Net的前向推断计算和反向梯度计算(forward inference and backward gradients),来对参数进行更新,从而达到减小loss的目的。Caffe模型的学习被分为两个部分:由Solver进行优化、更新参数,由Net计算出loss和gradient。
caffe 支持的solvers包括:
- Stochastic Gradient Descent (type: “SGD”),随机梯度下降
- AdaDelta (type: “AdaDelta”)
- Adaptive Gradient (type: “AdaGrad”),自适应梯度
- Adam (type: “Adam”)
- Nesterov’s Accelerated Gradient (type: “Nesterov”)
- RMSprop (type: “RMSProp”)
solver作用有
- 提供优化日志支持、创建用于学习的训练网络、创建用于评估的测试网络
- 通过调用forward / backward迭代地优化,更新权值
- 周期性地评估测试网络
- 通过优化了解model及solver的状态
每一个Solver都会继承Solve和Step函数,而每个Solver中独有的仅仅是ApplyUpdate这个函数里面执行的内容不一样,接口是一致的,这也就类似于工厂生产出来的产品一样功能一样,细节上有差异。接下里我们看看Solver中的关键函数。
核心代码如下:
/**
* @brief An interface for classes that perform optimization on Net%s.
*
* Requires implementation of ApplyUpdate to compute a parameter update
* given the current state of the Net parameters.
*/
template <typename Dtype>
class Solver {
public:
explicit Solver(const SolverParameter& param,
const Solver* root_solver = NULL);
explicit Solver(const string& param_file, const Solver* root_solver = NULL);
void Init(const SolverParameter& param);
void InitTrainNet();
void InitTestNets();
...
// The main entry of the solver function. In default, iter will be zero. Pass
// in a non-zero iter number to resume training for a pre-trained net.
virtual void Solve(const char* resume_file = NULL);
inline void Solve(const string resume_file) { Solve(resume_file.c_str()); }
void Step(int iters);
...
protected:
// Make and apply the update value for the current iteration.
virtual void ApplyUpdate() = 0;
...
SolverParameter param_;
int iter_;
int current_step_;
shared_ptr > net_;
vector<shared_ptr 说明:
shared_ptr为训练网络的指针,vector为测试网络的指针组,可见测试网络可以有多个- 一般来说训练网络跟测试网络在实现上会有区别,但是绝大部分网络层是相同的。
- 不同的模型训练方法通过重载函数ComputeUpdateValue( )实现计算update参数的核心功能
- caffe.cpp中的train( )函数训练模型,在这里实例化一个Solver对象,初始化后调用了Solver中的Solve( )方法。而这个Solve( )函数主要就是在迭代运行下面这两个函数。
ComputeUpdateValue();net_->Update();
每一次迭代过称中:
- 调用Net的前向过程计算出输出和loss;
- 调用Net的后向过程计算出梯度(loss对每层的权重w和偏置b求导);
- 根据Solver方法,利用梯度更新参数;
- 根据学习率(learning rate),历史数据和求解方法更新solver的状态,使权重从初始化状态逐步更新到最终的学习到的状态。solvers的运行模式有CPU/GPU两种模式。
Solver中Solve函数的流程图如下:

Solver类中Step函数流程图:
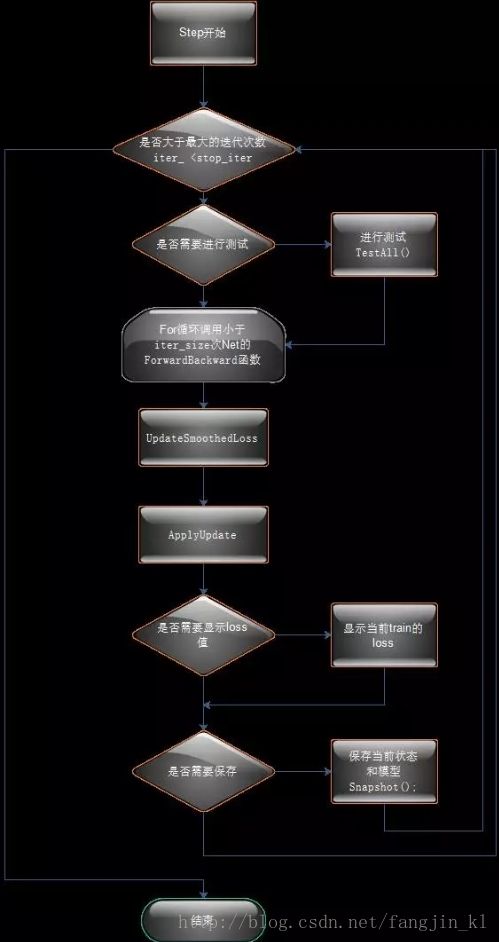
总结一下Solve执行中的关键步骤
其中Step步骤
其中
Net::ForwardBackward()函数如下,在Net小节中再详细介绍。
Dtype ForwardBackward(const vector说明:
- 前向计算。计算网络损失loss.
- 反向传播。计算loss关于网络权值的偏导.
而不同的Solver子类实现不同的ApplyUpdate函数。例如SGDSolver的函数实现如下
template <typename Dtype>
void SGDSolver<Dtype>::ApplyUpdate() {
CHECK(Caffe::root_solver());
//得到学习率
Dtype rate = GetLearningRate();
if (this->param_.display() && this->iter_ % this->param_.display() == 0) {
LOG(INFO) << "Iteration " << this->iter_ << ", lr = " << rate;
}
ClipGradients();
for (int param_id = 0; param_id < this->net_->learnable_params().size();
++param_id) {
Normalize(param_id);
Regularize(param_id);
ComputeUpdateValue(param_id, rate);
}
this->net_->Update();
}优化目标是
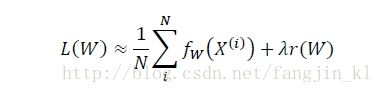
Normalize是归一化操作。Normalize核心代码如下
template <typename Dtype>
void SGDSolver::Normalize(int param_id) {
// Scale gradient to counterbalance accumulation.
const vector 其中caffe_scal 函数:
void caffe_scal<float>(const int N, const float alpha, float *X) {
cblas_sscal(N, alpha, X, 1);
}功能:X = alpha*X, N: X中element的个数
其中net_params 就是需要学习更新的参数。
Regularize函数大致类似。L2正则执行的是
下面看ComputeUpdateValue函数。
计算公式
void SGDSolver::ComputeUpdateValue(int param_id, Dtype rate) {
const vector 最后一步是执行this->net_->Update();更新参数,计算公式
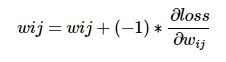
关键代码
template <typename Dtype>
void Net::Update() {
for (int i = 0; i < learnable_params_.size(); ++i) {
learnable_params_[i]->Update();
}
}
其中,learnable_params_是一个blob的vector,它的update核心如下
caffe_axpy(count_, Dtype(-1),
static_cast<const Dtype*>(diff_->cpu_data()),
static_cast(data_->mutable_cpu_data()));