使用Padding(cudaMallocPitch)的二维数组
使用Padding(cudaMallocPitch)的二维数组
有关为什么使用Padding的二维数组,在此篇已说明(为了对齐访问)
本篇就已实验来验证,Padding的必要性。
代码附在后面。
前言
本文的内容:
- 介绍CUDA API
cudaMallocPitch和cudaMemcpy2D。 - 实例代码实现
cudaMallocPitch和cudaMemcpy2D。 - 实验验证Padding的好处
- 探索全局内存访问的模式
Padding的步骤
- 修改申请内存的API
- 修改拷贝内存的API
- 修改核函数中对内存的访问的width–>pitch(控制仍用width)
- 修改拷贝API
核函数几乎不改,要注意的是拷贝,拷贝前后对象的width和pitch
CUDA APIcudaMallocPitch
cudaMallocPitch(
(void**)&devPtr,
size_t* &pitch,
size_t width*sizeof(type),
size_t height
);- pitch
size_t* &pitch这个参数是程序自己返回的值,不是自己设定的,一般是128字节的倍数,原本pitch的设计就是为了让访问对齐,因为在默认环境下,GTX1050Ti的取的内存事物颗粒是16字节,写是32字节。(怎么算参考我之前的一篇文章),之前的sm框架都是存取都是32字节,启动一级缓存之后为128字节。为了让128字节对齐,所以pitch返回的128的倍数,具体多少要看二维数组的宽width。
注:pitch是字节数。
不能整除128:
pitch = (width×sizeof(type)+ 127/128)×128
能整除128:
pitch = width×sizeof(type)
即:
int iDivUp(int a, int b) { return (a%b != 0) ? (a/b + 1) : (a/b); }
pitch = (width*sizof(type),128);再次说明pitch是CUDA API自己算的,其值是上面的公式。
2. size_t width*sizeof(type),
是原始width的字节数
3. height
height是数组的行数,是数不是字节数,区别前面的几个参数。(想一想,有了每一行的字节数ptich,只需要行数就可以了,所以不是字节。)
CUDA APIcudaMemcpy2D
cudaMemcpy2D 有从主机拷到设备,或由设备拷回主机。其中需要注意的是,你不必担心,把原始数据列放大到pitch,拷回来自己还要处理其中的填充Padding,其实cudaMemcpy2D 已经做好这方面工作,会让你进去的时候是多大,出来就是多大。
cudaMemcpy2D(
void * dst,
size_t dpitch,
const void * src,
size_t spitch,
size_t width,
size_t height,
enum cudaMemcpyKind kind
);- dst目标内存,可以是设备或主机
- dpitch 目标的pitch,如果是恢复原本的width,就是width所占的字节数
- src 拷贝的源
- spitch 源的pitch,单位字节
- width 源的width,单位字节
- height 源的htight 单位是数
- cudaMemcpyKind 拷贝的方向
实验代码
#include >>(d_A, pitch/sizeof(float),w,h);
cudaGetLastError();
// Copy the device result vector in device memory to the host result vector
// in host memory.
printf("Copy output data from the CUDA device to the host memory\n");
cudaMemcpy2D(h_A, sizeof(float)*w,d_A, pitch, sizeof(float)*w, h, cudaMemcpyDeviceToHost);
#endif
#ifndef PADDING
////////////////////////////////////////////////////////
/// no padding
////////////////////////////////////////////////////////
cudaMalloc((void **)&d_A,size);
cudaMemcpy(d_A,h_A,size,cudaMemcpyHostToDevice);
dim3 threadsPerBlock(32,8);
dim3 blocksPerGrid((w+threadsPerBlock.x-1)/threadsPerBlock.x,(h+threadsPerBlock.y-1)/threadsPerBlock.y);
vectorAdd1<<>>(d_A,w,h);
cudaGetLastError();
cudaMemcpy(h_A,d_A,size,cudaMemcpyDeviceToHost);
#endif
int a = 0;
// Verify that the result vector is correct
for (int i = 0; i < w*h; ++i)
{
if(h_A[i] != 4)
printf("err ");
a++;
}
printf("sum : %d \n",a);
// Free device global memory
cudaFree(d_A);
// Free host memory
free(h_A);
printf("Done\n");
return 0;
}
实验分析
当w = 512时,即对齐的情况下:
padding:

unpadding:
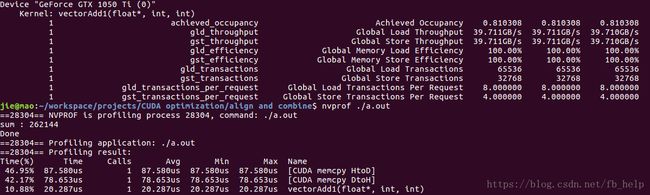
分析:在数据访问是对齐的情况下(数据是内存事物颗粒数的整倍数),两者性能基本相同。
但当w = 511时,即访问不对齐的情况下:
padding:

可以看到内存效率为99.8%
估计了其计算方法:(针对写操作)
数据本身的内存事务请求数:511*512*4/32 = 32704
实际的内存事物请求数:512*512*4/32 = 32768
内存效率:32704/32768 = 0.998046875
unpadding:
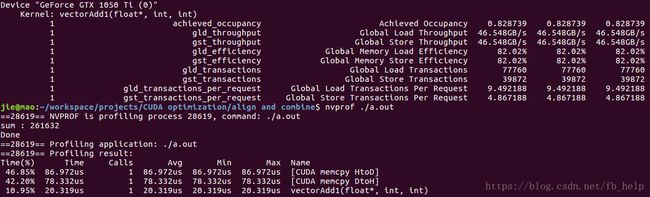
可以看到内存效率是82.2%
估计了其计算方法:(针对写操作)
数据本身的内存事务请求数:511*512*4/32 = 32704
实际的内存事物请求数:(512/32)*4+510*512*32*5×39/40 = 39844
(其计算是这样的:第一行64个内存事物请求,之后每32个元素有5个内存事物请求,在这些内存请求中有5*8个内存事物请求就有多出来的一个128字节可以被4个内存事物处理,但还是没和39872相等,不知道遗漏了什么)
内存效率:32704/39844 = 0.8208
所以发现,当没对齐的情况发生时又没有使用Padding,内存效率变为了82%
结论
- 可以通过图片发现,其实读取内存的内存事物数是写的2倍,但其效率却与写的相同,说明其内存颗粒虽然可以按16来算,但其实,它在外表上还是与32位的操作相同,猜想,在读操作时,线程束是按一半为单位读取的,但整体还是已线程束为单位操作的(显示与读是32位相同)。
- 发现虽然内存效率为82%但发现其读取带宽是46GB/s,而内存效率为99%的带宽是40G/s,这是它们两个速度差不多的原因,但暂时不能解释原因,可能是占用率不同导致的吧
- 由于操作简单,发现存取带宽之和为90G/s,与理论峰值112G/s相近
- 虽然padding增加了内存效率,但也增加了稀有资源显存的浪费(由于填充了一些没有计算的内存),它的大小,与width/128的余数和heght有关。
启用一级缓存
当w = 511时,即访问不对齐的情况下:
padding:

undding:

当w = 512时,即访问对齐的情况下:
padding:
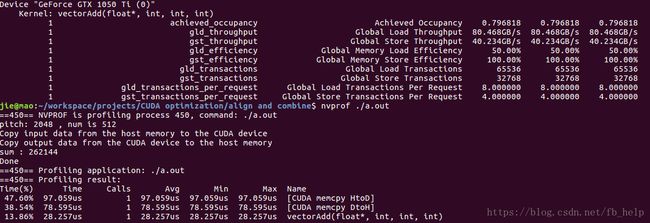
undding:

增大数据量
当将w变为3251,h变为4511
发现两种方式padding和unpadding的速度相同,但unpadding的内存效率依然是82%,padding的内存效率依然是99%,但在存取带宽上,unpadding却总是超过padding,使得unpadding与padding在性能表现上几乎一样。这与之前做平移的结果几乎一样。
对齐的访问依然存在
为什么要说依然,因为我曾一度认为,对齐的访问在现在的GPU框架不需要了,因为其内部的优化,原因出自CUDA优化实例(二)对齐与合并,当时的offset不改变性能GPU性能,让对内存访问的模式产生了怀疑,但其实其内部的访问方式还是没变,本篇就证明了对全局内存的访问还是没有变。但在性能上,对齐访问好像没有什么提高,这是现代GPU的优化,但为了兼容计算能力较弱的GPU,对齐访问还是有必要写出来向下兼容的。