一文读完 Machine Learning Yearning
文章目录
- 引言
- 介绍
- 设定开发集和测试集
- 训练集、开发集、测试集
- 开发集和测试集分布一致
- 开发集和测试集的大小
- 建立标量评价指标
- 何时换开发集/测试集/评价指标
- 基本错误分析
- 快速构建第一个系统,然后迭代
- 错误分析:根据开发集评估想法
- 清除错误标签和样本
- 如果开发集较大,分出部分用于错误分析
- 偏差和方差
- 两大类错误源
- 对照最优错误率
- 对付偏差和方差
- 学习曲线
- 人类水平对照
- 必要性
- 如何定义人类水平
- 超越人类水平
- 训练测试分布不同
- 何时会有这种情况
- 何时使用全部数据
- 不一致数据
- 数据加权
- 从训练集到开发集的泛化
- 数据生成
- 调试推断算法
- 优化验证测试
- 端到端深度学习
- 对比端到端和流水线系统
- 选择流水线系统:任务简单性
- 流水线系统错误分析
- 资源
引言
断断续续读完了吴恩达老师的炼丹宝典,《Machine Learning Yearning》,收获很大,但是,原书有100多页,读起来还是费不少时间的,再加上吴老师讲解细致、举例丰富,花的时间更多了。因此,我尝试记录书中的观点,说清楚,不遗漏,希望给大伙省点时间。
书中,吴老师介绍了机器学习(ML)实战中的经验,包括测试集开发集的选取、评价指标、偏差和方差、基本错误分析、学习曲线、和人类水平比较、调试、端到端深度学习等,可谓针针见血、点点到位,建议有时间的话,看看我这篇。
介绍
在机器学习实践中,一个算法表现差强人意,可能的改进方向有很多,获取更多的数据、获取多样的数据(数据覆盖范围更广)、清理数据、尝试不同的网络结构、改变优化方法、加正则化等等。若是选错了方向,可能浪费大量的时间、精力,算法性能也没有多少提升。如何有效地选择下一步策略?接着往下看。
开始之前,介绍下数据对于算法性能的影响。传统的ML算法需要的数据少,训练稳定,但是算法最终性能有限。流行的深度学习算法,拟合复杂分布能力很强,但很消耗数据和计算力,在数据够多的情况下,比传统的算法表现好。因此,要想提升性能,如果算力够,通常可以通过增加数据、使用更大的神经网络的方法。如下图所示:
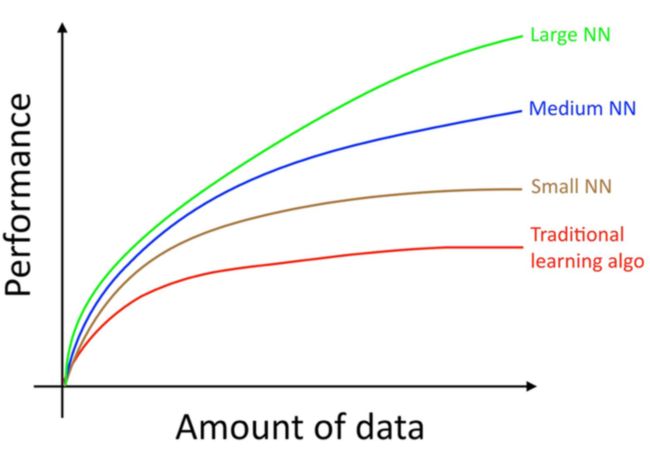
注:数据少时可能传统算法表现较好,主要看随着数据增加,不同模型的表现趋势。
设定开发集和测试集
训练集、开发集、测试集
训练集:Training set,用于算法训练,求解模型参数。
开发集:Dev set, development set, hold-out cross validation set,根据算法在开发集上的表现,寻找改进方向,如模型大小、特征选择等等。
测试集:Test set,测试算法的真正性能。测试集的分布要和真正应用时的分布一致,例如使用网络中爬取的图片作为训练,应用时输入用户上传的图片,如果划分一部分爬取图片作为测试集,可能测试结果不错,但真正算法性能可能很差,导致不能提前知道并改进。
开发集和测试集分布一致
开发集主要用于调整算法,如果和测试分布不一致,就不能保证开发集上的性能有提升,测试集上的性能也会跟着提升,不注意这点很坑人,会浪费大量的时间。
开发集和测试集的大小
开发集要足够大,以保证能够识别性能的提升。如果开发集只有100个样本,分类准确率提升1%,意味着仅仅多预测对一个样本,这很可能是误差和噪音带来的。如果开发集大小1000,区分0.1%的性能提升也是不准的。
同理,测试集也要足够大。
建立标量评价指标
实际任务可能有多个评价指标,比如识别图片是否有癌症,有分类准确率和召回率指标,光准确率高不够,召回率要高,有癌症的都能预测出来才行。要是都预测为有癌症,召回率高了,准确率却低了,老板该不高兴了。这时,只要定义一个数值指标,比如F1,朝着这个目标去,不用折腾别的了。团队可以快速迭代模型、评价性能提升、生活有奔头。
除了F1,还可以用加权的方式,将多个指标融入最终目标。
何时换开发集/测试集/评价指标
如果开发集有些过拟合,其上的性能提升不能代表真实的性能提升,换。
如果发现测试集和真实分布有出入,换。
如果发现评价指标有冗余,比如没有必要考虑召回率,准确率就够了,换。
基本错误分析
快速构建第一个系统,然后迭代
一上来就着手复杂的系统、最好的模型、想要面面俱到,不是一个好的方法。刚开始阶段,对问题了解的还不够,数据有哪些问题还不知道,有哪些坑,最值得投入的方向是什么都不清楚。应该先构建一个简单的模型,但是要快,从中发现问题、寻找灵感、改进模型,不断迭代。而且,简单模型可以用作基准,为后续模型提供参考。
错误分析:根据开发集评估想法
错误分析:通过检查样本出错情况,分析模型性能和改进方向的方法。
分析模型在开发集上的预测结果,归类错误类型,优先投入到提升空间大的想法。以识别图片是否有猫为例,如果对于狗的图片,模型预测为有猫的概率5%,再去改善这类错误,提升空间不是很大,浪费大量时间。可如果因为猫太小,没有识别到的错误率50%,应优先解决。
发现有多个并行的改进想法,人力够的话,可以同时实现,加快团队进度。
清除错误标签和样本
开发集可能含有错误标签和样本。如果错误占比较大,比如30%,影响了模型的评估,应当加以解决。如果错误占比1%,模型目前的错误率30%,还是算了吧,先别在这里浪费时间。
如果开发集较大,分出部分用于错误分析
开发集比较大的话,都看一遍太耗费精力,可以专门抽取一部分,从中吸取灵感,另外一部分仍可用来调参、模型选择等。
分出部分要足够大,使得找出的错误类型有普遍性。像猫识别的例子,如果猫太小导致的错误占比10%,但是只有1张,这跟开玩笑似的。
偏差和方差
两大类错误源
偏差:Bias,指的是算法建模的错误倾向。举个例子,如果真实的样本服从, 用去建模,然后求解,无论如何拟合错误都很大,称为高偏差。如果发现分类训练准确率只有70%,数据也够,任务也简单,别人都是90%多,考虑是不是使用的模型太简单了,换个复杂的试试。
方差:Variance,指的是算法对于训练集样本波动的敏感性。如果算法很容易根据样本的噪声信息,区分训练样本,测试结果会很差,称为高方差。如果测试准确率70%,训练准确率90%,可能出现了高方差,试试正则化方法、获取更多数据等。
过拟合:Overfitting,低偏差、高方差
欠你和:Underfitting,高偏差、低方差
如果你发现模型的偏差较高,方差也不低,这时就能体会到,我经常遇到这种事是什么心情了。
对照最优错误率
最优错误率,通常以人类错误率、当前论文中SOTA结果等为准,根据它知道模型还有多少提升空间。
如果分类人类错误率14%,训练集错误率15%,开发集错误率30%,则再进行调整偏差,收获最多1%,提升不大,若减小方差,收获最多15%,可以着手去做。
对付偏差和方差
偏差和方差权衡:控制方差和偏差的折衷。减小偏差的同时,可能会增大方差,比如模型的复杂了,拟合能力变强,但更倾向于过拟合。缩小方差,也可能误伤到偏差,比如减小模型尺寸。
应对偏差:增大模型大小(神经网络层数、层数)、修改模型结构、增加输入特征(从错误分析中获取灵感)、减轻或消除正则化。
应对方差:增加数据、使用正则化、Early Stopping、特征选择(减少无用特征)、减小模型尺寸、修改模型结构、改变输入特征。
学习曲线
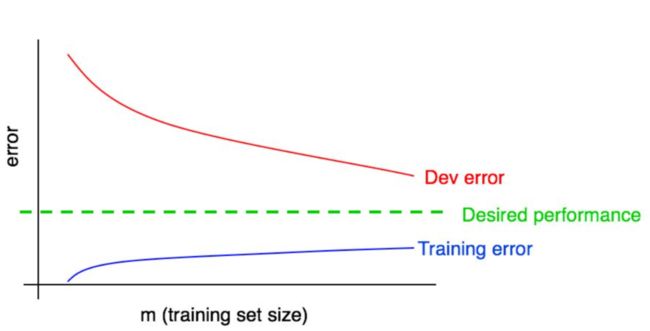
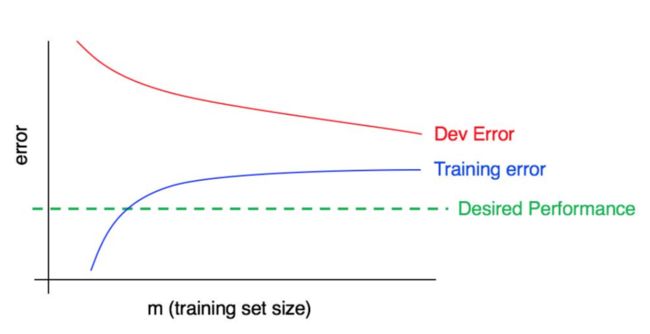
学习曲线:错误率随训练数据多少的变化趋势图。可以有效地诊断偏差和方差,辅助决定是否加入更多的数据。画学习曲线的时候,可以将训练数据采样部分出来,如果结果扰动厉害,采样多次,取结果的均值。
如下图所示,一般来说:
-
训练错误率要低于开发集错误率。
-
数据越少,越容易过拟合,方差越大。
-
数据增多,训练集和开发集错误缺口变小,方差减小。如果已经趋于平缓,表明没必要再增加数据了。
-
如果训练错误比期望表现高不少,说明偏差较大,考虑减小偏差。
人类水平对照
必要性
为什么和人类水平对照?通常来说,人容易完成的任务,做起来相对容易:
-
容易获取标注数据
-
容易进行错误分析
-
容易估计最优表现
人很难完成的任务,在上述方面做起来都有难度,决定做之前要慎重!
如何定义人类水平
对于同一个任务,不同人群水平不一样,拿识别图片是否有癌症来说,普通人的错误率10%,一般医生5%,而顶级专家可能只有1%。这时将5%作为人类水平来说合适,因为找一批医生来标注数据、错误分析等都很容易,找顶级专家来标多话,人家不会理你。
超越人类水平
如果模型已经和人类水平相当了,该如何继续提高?这时仍然可以提高模型某些方面的表现。比如语音识别,如果模型表现不错,可以通过错误分析,接着找出模型有哪些不足,若发现模型在噪音环境下不如人类,考虑下,如何进一步改进模型?人在噪声环境下如何识别的?有哪些灵感可以利用?
训练测试分布不同
何时会有这种情况
开发集和测试集要和真实分布一致,但是训练集不一定能够获取足量的真实分布数据。例如手机App识别猫图片,一开始获取用户上传10000张图片作为测试,训练数据不够,需要从网络中爬取大量的图片加入训练。
何时使用全部数据
如果有5k图片来自真实分布,50k图片来自网络爬取,要不要将50k图片全部加入训练?一般来说,加入额外的数据,神经网络表现会更好,这是假设神经网络的能力足够强,能hold住更多的图片。如果模型的容量有限,加入50k图片,可能导致模型把精力放在爬取图片上,而忽略了真实分布的特性。
不一致数据
有的时候额外获取的数据和真实数据有些关联,但要注意数据间是否一致,不一致的数据只会拖后腿。拿预测北京的房价来说,别净弄些印度泰国、缅甸老挝的房价数据,一点用没有。
数据加权
如果额外的数据较多,假设每条数据同等权重,会导致模型轻重失衡、本末倒置。计算损失的时候,加入的数据权重减小、真实数据权重增大,让模型兼顾不同数据。
从训练集到开发集的泛化
如果加入了额外的数据,结果训练集开发集表现差别较大,可能的原因有:
-
训练集上表现不好,这时偏差较大。
-
训练集上表现可以,和训练数据分布一致的数据上测试效果差,这时方差大。
-
训练集上表现可以,开发集上表现较差,这时训练数据和开发集数据不一致的影响较大。可以尝试理解训练集和开发集上数据间的差别,看看能否让训练数据和真实数据更匹配。
数据生成
如果数据不够,可以人工生成数据进行训练。若语音识别系统在车声中不准,可以跟老板申请买个车,用手机多录点。但要注意一点,一个车不够,因为模型可能学习到这个车的声音,换了其他车又不行了,还是坐出租较划算,可以假装打电话,实际上在录音。如果你是老板,要注意了,模型是否真的需要有车背景的语音?有可能模型已经做的不错了,再或者来了数据也没有大用,提前弄清楚,不然到时搭几辆车就亏大了。
调试推断算法
优化验证测试
很多优化目标对应着,比如机器翻译,给定了源语言句子A,找出最合适的目标语言句子S*, 表示模型对于预测句子为S的打分。
这类求解通常包含一个搜索算法,比如beam search,来应对指数级别搜索空间,和一个打分模型,评价不同的输出的好坏。这两部分的错误率,决定了整体的错误率。如果模型表现较差,但是对于大部分的S,,说明打分模型没问题,搜索算法需要调整。反之,说明需要适当调整模型。
端到端深度学习
对比端到端和流水线系统
流水线系统:Pipeline system,输入经过多个组件,得到输出。比如下图的语音识别系统。流水线系统每个组件实现的任务较简单,需要的数据量较少,训练方便、鲁棒。但是,数据经过每个组件,会损失一些信息,比如第一层,进行特征提取的同时,丢失了语音信号的原始特征。另外,各个组件之间的耦合不一定最优,而且他们相互依赖。在第二部分的音素识别,人耳的语音识别中并不存在,如果性能不好,直接影响到后续组件和整体的性能。总的来说,流水线系统经过优化后,性能不错。如果每个组件都有数据来进行训练,又相对简单,考虑使用流水线系统。

端到端系统:End-to-end system,没有叠加的多个组件,输入经过模型一步得到输出。比如神经机器翻译。这类系统省去了设计组件的烦恼,不会因为组件间的限制影响了整体性能。但是数据需求大,必须覆盖范围足够广才行。拿神经机器翻译来说,要想端到端进行训练,数据必须支持模型学到各种各样的语言特征,包括两种语言的词对应、不同语境下词义的区分、每种语言的句法和转换关系等等,很复杂。只有数据够多了,才考虑进行端到端系统的设计。
选择流水线系统:任务简单性
设计组件任务的时候,考虑其难易,如果组件任务较难,存在较大的错误率,势必会影响后续处理。而且,简单任务需要的数据也少,训练也快。如下图,识别是否有暹罗猫,先识别猫的位置,再识别猫的种类,比直接识别是否有暹罗猫要简单。
流水线系统错误分析
流水线系统有多个组件,要分析每一个组件的错误类型,先解决提升空间大的错误。一个组件的输入来自前面组件的输出,在分析其错误情况的时候,要把上个组件的错误排除。如上图,识别猫种类时,发现上个组件框错了猫的位置,可以手动调整,再输入当前组件,得到真正的错误率。对于单独组件的分析,可以按前面提到的方法进行,比如统计错误类型、比对最优错误率、检查样本寻找灵感等等。
如果每个组件各自的性能都不错,但是整体表现不佳,考虑是否是流水线系统设计的有问题?人是如何判断的?是否是漏了什么信息?
资源
-
原书
-
中文翻译
-
Bias and Variance Tradeoff
注:文章中观点为我对原书的理解,难免有错误,您要是发现了,可以参考原书相应章节,烦请也通知我。