Redis集群快速启动脚本程序
这段时间在深入学习redis,从单机版到与sentinel模式再到集群模式,sentinel模式倒是不难,两三天时间足够掌握,但是集群模式可不是两三天可以掌握的,光看文档就得整整一天专心致志不分心的看一整天,在这里附上我学习redis的网站redis中文官方网站,学习过程中,每天学习时间本来就不多,每次还要花十几分钟时间一个个启动服务,简直就是烦的不能再烦了,不懒的程序员不是好程序员,所以就想如何才能一键启动和关闭,刚开始是想通过java控制终端,直接用Process来执行命令并且启动,但是很遗憾的是只能启动一个,也是通过这件事情又复习了一遍面试官最爱问的"进程和线程的区别".没办法,只能通过脚本编程来实现这个功能了,所以专门花了三天时间学习脚本,这是我学习linux脚本的网站Linux Shell脚本教程,又花了两天时间写"懒人脚本",中间碰到的问题就是awk的使用,具体的教程在刚才那个网站也有介绍.
已经搭建好了的或者会搭建的看官们可以直接看第三步.
1:搭建(建议参考redis中文官方网站)
搭建集群的第一件事情我们需要一些运行在 集群模式的Redis实例. 这意味这集群并不是由一些普通的Redis实例组成的,集群模式需要通过配置启用,开启集群模式后的Redis实例便可以使用集群特有的命令和特性了.
下面是一个最少选项的集群的配置文件:
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
文件中的 cluster-enabled 选项用于开实例的集群模式, 而 cluster-conf-file 选项则设定了保存节点配置文件的路径, 默认值为 nodes.conf.节点配置文件无须人为修改, 它由 Redis 集群在启动时创建, 并在有需要时自动进行更新。
要让集群正常运作至少需要三个主节点,不过在刚开始试用集群功能时, 强烈建议使用六个节点: 其中三个为主节点, 而其余三个则是各个主节点的从节点。
首先, 让我们进入一个新目录, 并创建六个以端口号为名字的子目录, 稍后我们在将每个目录中运行一个 Redis 实例: 命令如下:
mkdir cluster-test
cd cluster-test
mkdir 7000 7001 7002 7003 7004 7005
在文件夹 7000 至 7005 中, 各创建一个 redis.conf 文件, 文件的内容可以使用上面的示例配置文件, 但记得将配置中的端口号从 7000 改为与文件夹名字相同的号码。
从 Redis Github 页面 的 unstable 分支中取出最新的 Redis 源码, 编译出可执行文件 redis-server , 并将文件复制到 cluster-test 文件夹, 然后使用类似以下命令, 在每个标签页中打开一个实例:
cd 7000
../redis-server ./redis.conf2:使用redis-trib.rb创建集群
现在我们已经有了六个正在运行中的 Redis 实例, 接下来我们需要使用这些实例来创建集群, 并为每个节点编写配置文件。
通过使用 Redis 集群命令行工具 redis-trib , 编写节点配置文件的工作可以非常容易地完成: redis-trib 位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查集群, 或者对集群进行重新分片(reshared)等工作。
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 \
127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005
这个命令在这里用于创建一个新的集群, 选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
之后跟着的其他参数则是这个集群实例的地址列表,3个master3个slave redis-trib 会打印出一份预想中的配置给你看, 如果你觉得没问题的话, 就可以输入 yes , redis-trib 就会将这份配置应用到集群当中,让各个节点开始互相通讯,最后可以得到如下信息:
[OK] All 16384 slots covered3:shell脚本
#!/bin/bash
#redis集群快速启动与关闭脚本
#条件一:当前文件夹下包括包含node开头的各个节点文件夹,节点文件夹下包含redis.conf配置文件,不可以配置成守护线程,不然启动时无法输出info到infoFile
#条件二:当前文件夹下包括redis-server,redis-cli
#条件三:请保持node文件夹后的数字与内部配置文件的端口号一致,例如node_7000文件夹的端口号为7000
#当前位置
cluster_dir=`ls`
#node节点的个数
node_size=0
#node节点数组
nodes=()
#信息文件
infoFile="infoFile"
#pid文件
pidFile="pidFile"
#创建infoFile和pidFile文件
touch infoFile
touch pidFile
#启动以node开头的文件夹下的redis节点,条件一:node开头,条件二:必须是文件夹
function starCluster(){
echo "" > $infoFile
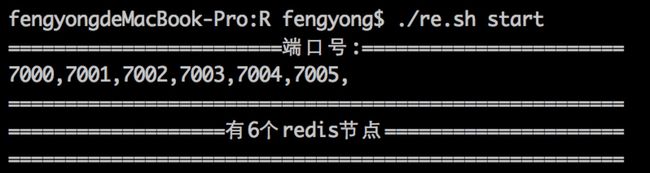
echo "========================端口号:======================="
for node in $cluster_dir
do
if [ ${node:0:4} = "node" ]
then
if [ -d ${node} ]
then
node_size=`expr ${node_size} + 1`
echo -e "${node:5:8},\c"
./redis-server ${node}/redis.conf >> $infoFile&
fi
fi
done
echo ""
echo "======================================================"
echo "===================有${node_size}个redis节点====================="
echo "======================================================"
}
#关闭所有节点
function stopCluster(){
cat $infoFile | grep "PID" | awk '{ infoSize=length($0);infoIndex=index($0,"PID");print substr($0,infoIndex+4,infoSize) }' > $pidFile
echo "===================redis集群的pid:===================="
for node in `cat $pidFile`
do
echo -e "${node}, \c}"
kill -9 ${node}&
done
echo ""
echo "======================================================"
}
case $1 in
start) starCluster
;;
stop) stopCluster
;;
esac4:使用脚本