hbase原理
在HBase的概念中,HRegionServer对应集群中的一个节点,一个HRegionServer负责管理多个HRegion,而一个HRegion代表一张表的一部分数据。在HBase中,一张表可能会需要很多个HRegion来存储数据,每个HRegion中的数据并不是杂乱无章的。HBase在管理HRegion的时候会给每个HRegion定义一个Rowkey的范围,落在特定范围内的数据将交给特定的Region,从而将负载分摊到多个节点,这样就充分利用了分布式的优点和特性。另外,HBase会自动调节Region所处的位置,如果一个HRegionServer过热,即大量的请求落在这个HRegionServer管理的HRegion上,HBase就会把HRegion移动到相对空闲的其它节点,依次保证集群环境被充分利用。
基本架构
HBase由HMaster和HRegionServer组成,同样遵从主从服务器架构。HBase将逻辑上的表划分成多个数据块即HRegion,存储在HRegionServer中。HMaster负责管理所有的HRegionServer,它本身并不存储任何数据,而只是存储数据到HRegionServer的映射关系(元数据)。集群中的所有节点通过Zookeeper进行协调,并处理HBase运行期间可能遇到的各种问题。HBase的基本架构如下图所示:

Client:使用HBase的RPC机制与HMaster和HRegionServer进行通信,提交请求和获取结果。对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC。
Zookeeper:通过将集群各节点状态信息注册到Zookeeper中,使得HMaster可随时感知各个HRegionServer的健康状态,而且也能避免HMaster的单点问题。
HMaster:管理所有的HRegionServer,告诉其需要维护哪些HRegion,并监控所有HRegionServer的运行状态。当一个新的HRegionServer登录到HMaster时,HMaster会告诉它等待分配数据;而当某个HRegion死机时,HMaster会把它负责的所有HRegion标记为未分配,然后再把它们分配到其他HRegionServer中。HMaster没有单点问题,HBase可以启动多个HMaster,通过Zookeeper的选举机制保证集群中总有一个HMaster运行,从而提高了集群的可用性。
HRegion:当表的大小超过预设值的时候,HBase会自动将表划分为不同的区域,每个区域包含表中所有行的一个子集。对用户来说,每个表是一堆数据的集合,靠主键(RowKey)来区分。从物理上来说,一张表被拆分成了多块,每一块就是一个HRegion。我们用表名+开始/结束主键,来区分每一个HRegion,一个HRegion会保存一个表中某段连续的数据,一张完整的表数据是保存在多个HRegion中的。
HRegionServer:HBase中的所有数据从底层来说一般都是保存在HDFS中的,用户通过一系列HRegionServer获取这些数据。集群一个节点上一般只运行一个HRegionServer,且每一个区段的HRegion只会被一个HRegionServer维护。HRegionServer主要负责响应用户I/O请求,向HDFS文件系统读写数据,是HBase中最核心的模块。HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了逻辑表中的一个连续数据段。HRegion由多个HStore组成,每个HStore对应了逻辑表中的一个列族的存储,可以看出每个列族其实就是一个集中的存储单元。因此,为了提高操作效率,最好将具备共同I/O特性的列放在一个列族中。
HStore:它是HBase存储的核心,由MemStore和StoreFiles两部分组成。MemStore是内存缓冲区,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile的文件数量增长到一定阈值后,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除操作。因此,可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的Compact过程中进行的,这样使得用户的写操作只要进入内存就可以立即返回,保证了HBaseI/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前的HRegion Split成2个HRegion,父HRegion会下线,新分出的2个子HRegion会被HMaster分配到相应的HRegionServer,使得原先1个HRegion的负载压力分流到2个HRegion上。
HLog:每个HRegionServer中都有一个HLog对象,它是一个实现了Write Ahead Log的预写日志类。在每次用户操作将数据写入MemStore的时候,也会写一份数据到HLog文件中,HLog文件会定期滚动刷新,并删除旧的文件(已持久化到StoreFile中的数据)。当HMaster通过Zookeeper感知到某个HRegionServer意外终止时,HMaster首先会处理遗留的 HLog文件,将其中不同HRegion的HLog数据进行拆分,分别放到相应HRegion的目录下,然后再将失效的HRegion重新分配,领取到这些HRegion的HRegionServer在加载 HRegion的过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后Flush到StoreFiles,完成数据恢复。
2.3 ROOT表和META表
HBase的所有HRegion元数据被存储在.META.表中,随着HRegion的增多,.META.表中的数据也会增大,并分裂成多个新的HRegion。为了定位.META.表中各个HRegion的位置,把.META.表中所有HRegion的元数据保存在-ROOT-表中,最后由Zookeeper记录-ROOT-表的位置信息。所有客户端访问用户数据前,需要首先访问Zookeeper获得-ROOT-的位置,然后访问-ROOT-表获得.META.表的位置,最后根据.META.表中的信息确定用户数据存放的位置,如下图所示。

-ROOT-表永远不会被分割,它只有一个HRegion,这样可以保证最多只需要三次跳转就可以定位任意一个HRegion。为了加快访问速度,.META.表的所有HRegion全部保存在内存中。客户端会将查询过的位置信息缓存起来,且缓存不会主动失效。如果客户端根据缓存信息还访问不到数据,则询问相关.META.表的Region服务器,试图获取数据的位置,如果还是失败,则询问-ROOT-表相关的.META.表在哪里。最后,如果前面的信息全部失效,则通过ZooKeeper重新定位HRegion的信息。所以如果客户端上的缓存全部是失效,则需要进行6次网络来回,才能定位到正确的HRegion。
3 HBase数据模型
HBase是一个类似于BigTable的分布式数据库,它是一个稀疏的长期存储的(存在HDFS上)、多维度的、排序的映射表。这张表的索引是行关键字、列关键字和时间戳。HBase的数据都是字符串,没有类型。
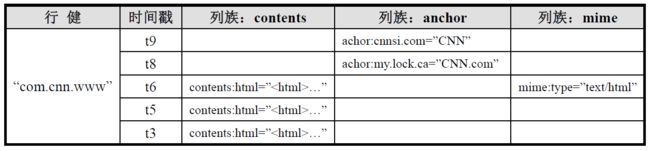
可以将一个表想象成一个大的映射关系,通过行键、行键+时间戳或行键+列(列族:列修饰符),就可以定位特定数据。由于HBase是稀疏存储数据的,所以某些列可以是空白的。上表给出了com.cnn.www网站的数据存放逻辑视图,表中仅有一行数据,行的唯一标识为“com.cnn.www”,对这行数据的每一次逻辑修改都有一个时间戳关联对应。表中共有四列:contents:html、anchor:cnnsi.com、anchor:my.look.ca、mime:type,每一列以前缀的方式给出其所属的列族。
行键(RowKey)是数据行在表中的唯一标识,并作为检索记录的主键。在HBase中访问表中的行只有三种方式:通过某个行键访问、给定行键的范围访问、全表扫描。行键可以是任意字符串(最大长度64KB)并按照字典序进行存储。对于那些经常一起读取的行,需要对键值精心设计,以便它们能放在一起存储。
4 HBase读写流程
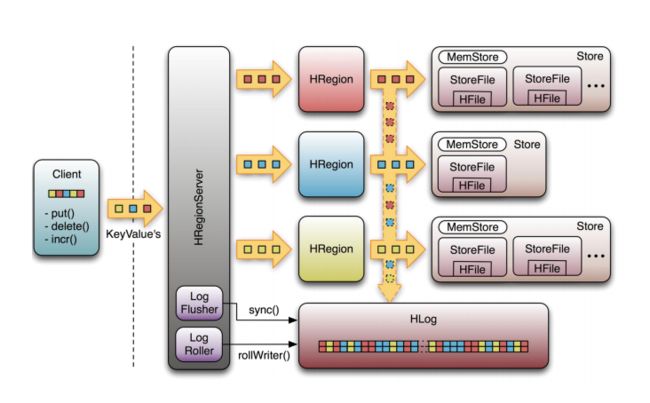
上图是HRegionServer数据存储关系图。上文提到,HBase使用MemStore和StoreFile存储对表的更新。数据在更新时首先写入HLog和MemStore。MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore添加到Flush队列,由单独的线程Flush到磁盘上,成为一个StoreFile。与此同时,系统会在Zookeeper中记录一个CheckPoint,表示这个时刻之前的数据变更已经持久化了。当系统出现意外时,可能导致MemStore中的数据丢失,此时使用HLog来恢复CheckPoint之后的数据。
StoreFile是只读的,一旦创建后就不可以再修改。因此Hbase的更新其实是不断追加的操作。当一个Store中的StoreFile达到一定阈值后,就会进行一次合并操作,将对同一个key的修改合并到一起,形成一个大的StoreFile。当StoreFile的大小达到一定阈值后,又会对 StoreFile进行切分操作,等分为两个StoreFile。
4.1 写操作流程
步骤1:Client通过Zookeeper的调度,向HRegionServer发出写数据请求,在HRegion中写数据。
步骤2:数据被写入HRegion的MemStore,直到MemStore达到预设阈值。
步骤3:MemStore中的数据被Flush成一个StoreFile。
步骤4:随着StoreFile文件的不断增多,当其数量增长到一定阈值后,触发Compact合并操作,将多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除。
步骤5:StoreFiles通过不断的Compact合并操作,逐步形成越来越大的StoreFile。
步骤6:单个StoreFile大小超过一定阈值后,触发Split操作,把当前HRegion Split成2个新的HRegion。父HRegion会下线,新Split出的2个子HRegion会被HMaster分配到相应的HRegionServer 上,使得原先1个HRegion的压力得以分流到2个HRegion上。
4.2 读操作流程
步骤1:client访问Zookeeper,查找-ROOT-表,获取.META.表信息。
步骤2:从.META.表查找,获取存放目标数据的HRegion信息,从而找到对应的HRegionServer。
步骤3:通过HRegionServer获取需要查找的数据。
步骤4:HRegionserver的内存分为MemStore和BlockCache两部分,MemStore主要用于写数据,BlockCache主要用于读数据。读请求先到MemStore中查数据,查不到就到BlockCache中查,再查不到就会到StoreFile上读,并把读的结果放入BlockCache。
5 HBase使用场景
半结构化或非结构化数据:对于数据结构字段不够确定或杂乱无章,很难按一个概念去进行抽取的数据适合用HBase。如随着业务发展需要存储更多的字段时,RDBMS需要停机维护更改表结构,而HBase支持动态增加。
记录非常稀疏:RDBMS的行有多少列是固定的,为空的列浪费了存储空间。而HBase为空的列不会被存储,这样既节省了空间又提高了读性能。
多版本数据:根据RowKey和列标识符定位到的Value可以有任意数量的版本值(时间戳不同),因此对于需要存储变动历史记录的数据,用HBase将非常方便。
超大数据量:当数据量越来越大,RDBMS数据库撑不住了,就出现了读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。随着压力增加,Master撑不住了,这时就要分库了,把关联不大的数据分开部署,一些join查询不能用了,需要借助中间层。随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比如按ID取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。采用HBase就简单了,只需要在集群中加入新的节点即可,HBase会自动水平切分扩展,跟Hadoop的无缝集成保障了数据的可靠性(HDFS)和海量数据分析的高性能(MapReduce)。
6 HBase的MapReduce
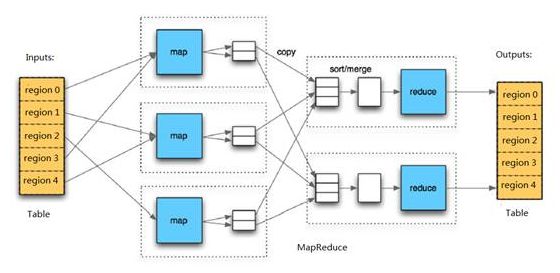
HBase中Table和Region的关系,有些类似HDFS中File和Block的关系。由于HBase提供了配套的与MapReduce进行交互的API如TableInputFormat和TableOutputFormat,可以将HBase的数据表直接作为Hadoop MapReduce的输入和输出,从而方便了MapReduce应用程序的开发,基本不需要关注HBase系统自身的处理细节。