基于Tensorflow的MNIST机器学习经典案例的翻译
说实话,对于学习,很久没有体会到对这种陷进去的感受了。现在是周六下午,我独自一人在空荡荡的办公室,而且昨天在办公室弄到快23:00,今早还是起来顶着高温到办公司10:00多,我做这些不是说加班,目的请看标题。
学习一门语言一种数据库一种框架或许我不会这么激进,但是对AI却充满着幻想,可能就是因为好奇。自从去年独自接了人生第一个外包项目“文本无关的声纹识别”后,就一直对AI有着羁绊,恰逢现在工作上有个不紧不慢的项目“人工智能聊天机器人”,我也稍微可以名正言顺的利用工作时间来研究研究。
昨天开始一直在跑着一个chat bot网上开源的demo,需要训练30多个小时,希望能跑成功。废话不扯了,讲下我今天学到的一个基于Tensorflow的MNIST机器学习入门demo,这个demo虽然是Tensorflow官网入门案例,而且网上也有中文翻译版,但觉得都不好理解,我想把我自己的理解到的记下来。
一共就两个python文件,只有main.py需要自己写,另一个input_data.py自己拷贝下来,放在跟main.py在同一目录下,main.py如下:
# !/usr/bin/env python3.5
# -*- coding:utf-8 -*-
# @Author : sven
# @Time : 18-4-10 下午3:48
# @Project : MNIST
# @File : main.py
# @Software : PyCharm
import tensorflow as tf
import input_data
import datetime
# 定义输入数据集,加载数据
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
print("mnist data loaded")
# 定义输入图像x(784表示一张展平的MNIST图像的维度)
# 和目标输出类别Y(10表示一个10维的one-hot向量,对应10种类别)
# None表示值不确定,用以指代batch的大小
x = tf.placeholder("float", [None, 784])
Y = tf.placeholder("float", [None, 10])
# w对应784维输入和10维输出,b对应10个类别,都用zeros初始化为0
w = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
# Softmax回归模型(仅1行)
# 把向量化的图片x和权重w相乘(matmul为矩阵乘法),加上偏置b,然后计算每个分类的softmax概率值
y = tf.nn.softmax(tf.matmul(x, w) + b)
# 损失函数,定义为目标类别和预测类别之间的交叉熵
# 这里计算的是batch里所有张图的交叉熵的和
crossEntropy = -tf.reduce_sum(Y*tf.log(y))
# 最速下降法最小化交叉熵,学习率为0.01
trainStep = tf.train.GradientDescentOptimizer(0.01).minimize(crossEntropy)
# 初始化,训练前的准备工作
# init = tf.initialize_all_variables()
# 初始化的新方法,原法会报warning
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
beginTime = datetime.datetime.now()
# 迭代1000次,每次选取100个训练样本,然后执行一次trainStep
# feed_dict用训练数据来替代x和Y的占位符
# argmax返回这一维数据上最大值的索引值,本例中即类别标签为1的位置
# equal可用来判断预测值y和真实值Y是否相等,返回boolen数组
# 用均值mean来表示准确率
for i in range(1000):
batch_x, batch_Y = mnist.train.next_batch(100)
sess.run(trainStep, feed_dict={x: batch_x, Y: batch_Y})
correctPrediction = tf.equal(tf.argmax(y, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correctPrediction, "float"))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, Y: mnist.test.labels}))
endTime = datetime.datetime.now()
# 训练完成时间-训练开始时间=训练时长
print("totally used: {}".format(endTime - beginTime))
sess.close()
程序其实不难,这篇文章我主要基于这个demo本身进行讲解,先不扯Tensorflow这个工具,也不讲这个demo对机器学习怎么怎么入门。很多人包括我一开始,对这个简单的demo本身都还没理解,谈什么机器学习和Tensorflow。
我分以下3部分讲:
一、demo要做什么,此处用到的数据源是什么样的以及怎样获取
二、模型分析
三、运用Tensorflow处理该模型
一、demo要做什么,此处用到的数据源是什么样的以及怎样获取
我们要做的是训练一个数字图片识别模型,有点像破解验证码的程序:给定含有0–9的数字手写图片(目前不能上传自己的图片,只能用数据源提供的图片,因为训练样本有限,是28*28像素的图片集),然后能够用这个模型去识别图片中的数字是什么,比如能识别下图数字为5,0,4,1

这4张图片都来自于一个叫MNIST的数据集,不要在意MNIST是什么,只要知道可以通过input_data.py下载我们要的数据就好,在主程序中是这么引入它的:
import input_data
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)这样可以把图片数据读到mnist变量中,该数据包含60000行的训练数据(train*)和10000行的测试数据(t10k*),如下图所示:

训练数据和测试数据又各自分为一一对应的图片数据和标签数据,图片是28*28的象素点,标签是0–9的数字,图片和标签相互对应着,这就是别人采集好的MNIST数据集,如上图所示。可以看到,标签数据文件大小明显比图片文件要小很多,而且(train*)文件也明显比(t10k*)大得多,因为测试数据只有10000行,而训练数据60000行。测试数据是当模型训练好之后,供测试模型训准确率之用,这也是为啥不要我们自己再提供图片来测试,因为它们模型都是基于28*28像素的图片训练出来的,如果要支持第三方图片识别,需做额外复杂的处理,不在本文讨论范畴。
另外有人用代理上网,或者公司网络设置了安全级别的,不管什么原因导致下载MNST失败,都可以在CSDN下载这4个文件,并放在上图文件夹里就可以。我今天遇到的就是这个坑,公司用了代理,没研究出哪里可以设代理!
二、模型分析
模型主要还是围绕象素点来进行研究,把训练数据集的图片数据和标签数据分开,每张图片是28*28的象素点,可以用784长度的数组来存,于是训练数据的图片可以用60000*784的二维数组表示,60000代表图片的张数。因为每张代表一个数字,所以标签数据集可以用长度为10的数组表示,例如数字0表示为[1,0,0,0,0,0,0,0,0],5表示为[0,0,0,0,1,0,0,0,0],专业术语叫one-hot向量,于是标签数据集可以用60000*10的二维数组表示。
784个像素点构成一张图片,每张图片表示0–9的数字,我们要建立的模型就是从最小单元像素为出发点,印射到0–9的数字,有点高中所学的点动成线线动成面的意思。所以如果不考虑象素点之间的干扰,可以粗糙的建立一个模型:0–9每个数字,对应784个权值,分别代表该数字印射到各个象素点的权重,比如6这张图片对应的784个权重,分别对应着该数字到各个象素点的映射,可以理解为数字是由象素点构成的,此处印射只是对”构成“这个动作的量化,于是权W可以写成10*784的二维数组。也可以对”构成“这个动作进一步抽取,得到某种函数对应关系,如下:

其中evidence(i)代表该图片是数字i的可能性,0<=i<=9,或者说是证据,j从1到784的象素点进行求和,0< j<784,Wi,j代表数字i对应象素点j的权值,考虑到某些数字图片输入的偏差,b(i)代表数字i对应的偏置量,我个人理解b(i)是针对诸如数字0和8,数字6和9等等这些个别数字有自己的一个特性,所以需要加入一个偏置量。接着用如下公式对上述证据值做一个概率拟合。

其中的softmax函数如下,不懂该函数的网上自行了解下,一言以蔽之,该函数是max函数的中庸应用,避免让一个样本集的某些个体因为值小而永远处于不可能出现状态:

于是反映一张图片对应0–9的概率分布Y值如下:
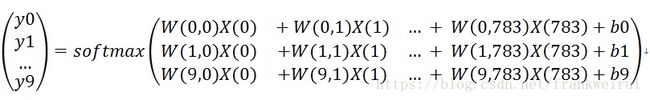
进一步可以写成如下公式(满足向量相乘规则):

简记如下:
这个经过softmax的向量Y,代表对该图片预测出来的数字分别落在0–9上的概率。该图片的真实分布为向量y,是一个已知的one-hot向量,那我们要做的是“尽可能让Y等于y”。利用上一篇文章介绍的交叉熵知识,我们可以把“尽可能让Y等于y”抽取出数学表达式,如下:

即“尽可能让Y等于y”就是要上述公式的值Hy(Y)尽可能的小。
总结如下:
我们训练的目的就是求W和B,W一共有10*784个值,B一共有10个值,使得交叉熵Hy(Y)的值越来越小。
做法如下:
我们把W和B的值都初始化为0,然后用训练数据集的图片去训练,对单张训练图片而言,转化为数学问题就是:已知该图片的象素点集合X,套用上述一系列公式,可以计算得到一个代表0–9数字的one-hot向量Y,再配合已知该图片实际代表的数字0–9的向量y(比如0表示为[1,0,0,0,0,0,0,0,0]),把Y和y代入上述交叉熵的公式,得到值Hy(Y),通过不断调整W和B的值,使得Hy(Y)最小化。这实际的做法涉及到梯度下降算法,属于高数微积分的范畴,具体算法,我估计会再写几篇文章研究,这里我们把它扔给Tensorflow去做,切忌不要去造轮子。
三、运用Tensorflow处理该模型
如果没听说过Tensorflow,建议去网上了解下,然后花5分钟快速阅读下基本用法…5分钟过去了…假设你终于知道Tensorflow是干啥的了,比如知道啥叫节点、预设定、Feed和session.run()。然后我们来建立上述模型。Tensorflow通俗的说就是先预设定好变量、公式和和要达到的目的,把这些统统程式化,等一切准备就绪后,输入参数启动整个训练程式。
1、x = tf.placeholder(“float”, [None, 784]) 理解为一个拥有N张图片,每张图片拥有784个象素点的的变量,等下模型跑起来,作为输入变量。
2、W = tf.Variable(tf.zeros([784,10])) 这是需要调整的权值W,它包含10*784个值,因为0–9每个数字到784个象素点之间都有一个权分量,该值在对多张训练图片进行训练后得到交叉熵Hy(Y),通过该值大小,反过来对W不断进行调整。
3、b = tf.Variable(tf.zeros([10])) 0–9每个数字都有一个偏置量,跟W一样,也需要不断反馈调整,该值容易理解,第一段已作过解释。
4、Y = tf.nn.softmax(tf.matmul(x,W) + b) 设定该公式,通过初始化的W和B,以及每次循环的训练图片集,预测数该图片属于0–9哪个数字。
5、y = tf.placeholder(“float”, [None,10]) 给定图片真实代表0–9哪个数字,等下模型跑起来,作为输入变量。
6、cross_entropy = -tf.reduce_sum(y*tf.log(Y)) 设定该公式,求交叉熵,代码和此处的Y和y反了,不要在意这些细节。
7、train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) 设定该公式,表示整个训练过程采用梯度下降算法来使上述交叉熵值最小。0.01为学习速率,个人认为可以理解为步长,即导数中的自变量移动大小。
8、init = tf.initialize_all_variables()和sess.run(init) 初始化设定好的程式。
接下来启动训练:
for i in range(1000):
batch_x, batch_Y = mnist.train.next_batch(100)
sess.run(trainStep, feed_dict={x: batch_x, Y: batch_Y})这里训练了1000次,每次从mnst库中拿取100张图片来训练,把这100张图片的象素点存在batch_xs变量,把图片代表的0–9数字存在batch_ys变量,然后作为输入启动程式。
最后运用下面3句,用测试数据集测试该模型的准确率:
correctPrediction = tf.equal(tf.argmax(y, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correctPrediction, "float"))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, Y: mnist.test.labels}))该经典案例深刻的展现了机器学习的过程和原理,但这不是深度学习,深度学习比机器学习还要更上一层楼…
原文链接:这里写链接内容
注: 原文在code和说明上有一些小错误,本文转载时已修改