MaskRCNN源码解读
https://blog.csdn.net/horizonheart/article/details/81188161
源码地址:https://github.com/matterport/Mask_RCNN
这个是一个基于Keras写的maskrcnn的源码,作者写的非常nice。没有多余的问文件,源码都放在mrcnn中,readme里

为了了解maskrcnn的运行流程,最好的办法就是将代码边运行边调试。从samples下面的coco文件开始运行:

前面首先会加载一些配置文件的数据,暂时用不到没必要去具体看这些配置文件,等到用到的时候,再回头去看这些细节。
MaskRCNN的整体流程图为:

首先要看的就是模型的搭建,也就是maskrcnn的基础网络结构。
1--模型搭建

跳转到对应的方法中

1.1--在build方法中,首先要创建一些模型的输入变量。
由于此时我们并不知道输入变量的具体大小,因此我们可以使用Keras的变量进行占位操作,等到具体训练的时候根据传入的参数确定变量的大小。train和inference的时候,都是先build的模型,因此他们共有一个模型,inference的时候,需要的输入变量比较少。gt_boxes使用了归一化的操作,也就是所有的边框的坐标都是0到1之间,这样做的好处是避免数值大小带来的预测误差。
1.2 --搭建backbone网络
搭建特征提取网络用于图片的特征的提取,maskrcnn使用了金字塔(FPN)的网络方式进行特征的提取,使用的网络是resnet101 ,具体的网络的可视化可以参考:http://ethereon.github.io/netscope/#/gist/b21e2aae116dc1ac7b50
然后利用不同的特征去做不同的事情,代码中的使用方式如下,P2,P3,P4,P5,P6用于rpn网络提取信息。由于上面都进行了3*3的卷积操作,保证了不同层的特征的channel数目一样。
 有了这些特征图,就可以用这些特征图生成anchor。
有了这些特征图,就可以用这些特征图生成anchor。

1.3--RPN网络
搭建rpn网络,将1.2步得到的金字塔特征分别输入到rpn网络中,得到网络的分类和回归值。
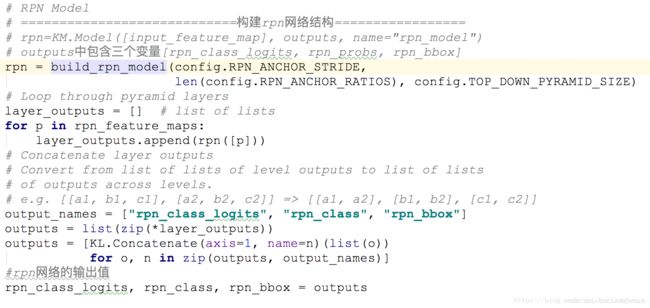
rpn_logits: [batch, H, W, 2] Anchor classifier logits (before softmax)
rpn_probs: [batch, W, W, 2] Anchor classifier probabilities.
rpn_bbox: [batch, H, W, (dy, dx, log(dh), log(dw))] Deltas to be
applied to anchors.
1.4--ProposalLayer
将rpn网路的输出应用到1.2步得到的anchors,首先对输出的概率进行排序,保留其中预测为前景色概率大的一部分(具体值可以在配置文件中进行配置),然后选取想对应的anchor,利用rpn的输出回归值对anchor进行第一次修正。修正完利用极大抑制方法,删除其中的一部分anchor。获的最后的anchor。
#ProposalLayer的作用主要
# 1. 根据rpn网络,获取score靠前的前6000个anchor
# 2. 利用rpn_bbox对anchors进行修正
# 3. 舍弃掉修正后边框超过图片大小的anchor,由于我们的anchor的坐标的大小是归一化的,只要坐标不超过0 1区间即可
# 4. 利用非极大抑制的方法获得最后的anchor
1.5--DetectionTargetLayer
DetectionTargetLayer的输入包含了,target_rois, input_gt_class_ids, gt_boxes, input_gt_masks。其中target_rois是ProposalLayer输出的结果。首先,计算target_rois中的每一个rois和哪一个真实的框gt_boxes iou值,如果最大的iou大于0.5,则被认为是正样本,负样本是是iou小于0.5并且和crowd box相交不大的anchor,选择出了正负样本,还要保证样本的均衡性,具体可以才配置文件中进行配置。最后计算了正样本中的anchor和哪一个真实的框最接近,用真实的框和anchor计算出偏移值,并且将mask的大小resize成28*28的(我猜测利用的是双线性差值的方式,因为mask的值不是0就是1,0是背景,一是前景)这些都是后面的分类和mask网络要用到的真实的值。下面是该层的主要代码:
获取的就是每个rois和哪个真实的框最接近,计算出和真实框的距离,以及要预测的mask,这些信息都会在网络的头的classify和mask网络
#所使用
def detection_targets_graph(proposals, gt_class_ids, gt_boxes, gt_masks, config):
"""Generates detection targets for one image. Subsamples proposals and
generates target class IDs, bounding box deltas, and masks for each.
Inputs:
proposals: [N, (y1, x1, y2, x2)] in normalized coordinates. Might
be zero padded if there are not enough proposals.
gt_class_ids: [MAX_GT_INSTANCES] int class IDs
gt_boxes: [MAX_GT_INSTANCES, (y1, x1, y2, x2)] in normalized coordinates.
gt_masks: [height, width, MAX_GT_INSTANCES] of boolean type.
Returns: Target ROIs and corresponding class IDs, bounding box shifts,
and masks.
rois: [TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized coordinates
class_ids: [TRAIN_ROIS_PER_IMAGE]. Integer class IDs. Zero padded.
deltas: [TRAIN_ROIS_PER_IMAGE, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
Class-specific bbox refinements.
masks: [TRAIN_ROIS_PER_IMAGE, height, width). Masks cropped to bbox
boundaries and resized to neural network output size.
Note: Returned arrays might be zero padded if not enough target ROIs.
"""
# Assertions
asserts = [
tf.Assert(tf.greater(tf.shape(proposals)[0], 0), [proposals],
name="roi_assertion"),
]
with tf.control_dependencies(asserts):
proposals = tf.identity(proposals)
# Remove zero padding
proposals, _ = trim_zeros_graph(proposals, name="trim_proposals")
#去除非零的真实的框,也就是只留下真实存在的有意义的框
gt_boxes, non_zeros = trim_zeros_graph(gt_boxes, name="trim_gt_boxes")
gt_class_ids = tf.boolean_mask(gt_class_ids, non_zeros,
name="trim_gt_class_ids")
gt_masks = tf.gather(gt_masks, tf.where(non_zeros)[:, 0], axis=2,
name="trim_gt_masks")
# Handle COCO crowds
# A crowd box in COCO is a bounding box around several instances. Exclude
# them from training. A crowd box is given a negative class ID.
#在coco数据集中,有的框会标注很多的物体,在训练中,去掉这些框
crowd_ix = tf.where(gt_class_ids < 0)[:, 0]
non_crowd_ix = tf.where(gt_class_ids > 0)[:, 0]
crowd_boxes = tf.gather(gt_boxes, crowd_ix)
crowd_masks = tf.gather(gt_masks, crowd_ix, axis=2)
#下面就是一张图片中真实存在的物体用于训练
gt_class_ids = tf.gather(gt_class_ids, non_crowd_ix)
gt_boxes = tf.gather(gt_boxes, non_crowd_ix)
gt_masks = tf.gather(gt_masks, non_crowd_ix, axis=2)
# Compute overlaps matrix [proposals, gt_boxes]
#计算iou的值
overlaps = overlaps_graph(proposals, gt_boxes)
# Compute overlaps with crowd boxes [anchors, crowds]
crowd_overlaps = overlaps_graph(proposals, crowd_boxes)
crowd_iou_max = tf.reduce_max(crowd_overlaps, axis=1)
no_crowd_bool = (crowd_iou_max < 0.001)
# Determine positive and negative ROIs
roi_iou_max = tf.reduce_max(overlaps, axis=1)
# 1. Positive ROIs are those with >= 0.5 IoU with a GT box
#和真实的框的iou值大于0.5时,被认为是正样本
positive_roi_bool = (roi_iou_max >= 0.5)
positive_indices = tf.where(positive_roi_bool)[:, 0]
# 2. Negative ROIs are those with < 0.5 with every GT box. Skip crowds.
#负样本是是iou小于0.5并且和crowd box相交不大的anchor
negative_indices = tf.where(tf.logical_and(roi_iou_max < 0.5, no_crowd_bool))[:, 0]
# Subsample ROIs. Aim for 33% positive
# Positive ROIs
positive_count = int(config.TRAIN_ROIS_PER_IMAGE *
config.ROI_POSITIVE_RATIO)
positive_indices = tf.random_shuffle(positive_indices)[:positive_count]
positive_count = tf.shape(positive_indices)[0]
# Negative ROIs. Add enough to maintain positive:negative ratio.
r = 1.0 / config.ROI_POSITIVE_RATIO
negative_count = tf.cast(r * tf.cast(positive_count, tf.float32), tf.int32) - positive_count
negative_indices = tf.random_shuffle(negative_indices)[:negative_count]
# Gather selected ROIs
#选择出正负样本
positive_rois = tf.gather(proposals, positive_indices)
negative_rois = tf.gather(proposals, negative_indices)
# Assign positive ROIs to GT boxes.
#计算正样本和哪个真实的框最接近
positive_overlaps = tf.gather(overlaps, positive_indices)
roi_gt_box_assignment = tf.cond(
tf.greater(tf.shape(positive_overlaps)[1], 0),
true_fn = lambda: tf.argmax(positive_overlaps, axis=1),
false_fn = lambda: tf.cast(tf.constant([]),tf.int64)
)
roi_gt_boxes = tf.gather(gt_boxes, roi_gt_box_assignment)
roi_gt_class_ids = tf.gather(gt_class_ids, roi_gt_box_assignment)
# Compute bbox refinement for positive ROIs
#用最接近的真实框修正rpn网络预测的框
deltas = utils.box_refinement_graph(positive_rois, roi_gt_boxes)
deltas /= config.BBOX_STD_DEV
# Assign positive ROIs to GT masks
# Permute masks to [N, height, width, 1]
transposed_masks = tf.expand_dims(tf.transpose(gt_masks, [2, 0, 1]), -1)
# Pick the right mask for each ROI
# 计算和每一个rois最接近的框的mask
roi_masks = tf.gather(transposed_masks, roi_gt_box_assignment)
# Compute mask targets
boxes = positive_rois
if config.USE_MINI_MASK:
# Transform ROI coordinates from normalized image space
# to normalized mini-mask space.
y1, x1, y2, x2 = tf.split(positive_rois, 4, axis=1)
gt_y1, gt_x1, gt_y2, gt_x2 = tf.split(roi_gt_boxes, 4, axis=1)
gt_h = gt_y2 - gt_y1
gt_w = gt_x2 - gt_x1
y1 = (y1 - gt_y1) / gt_h
x1 = (x1 - gt_x1) / gt_w
y2 = (y2 - gt_y1) / gt_h
x2 = (x2 - gt_x1) / gt_w
boxes = tf.concat([y1, x1, y2, x2], 1)
box_ids = tf.range(0, tf.shape(roi_masks)[0])
# crop_and_resize相当于roipolling的操作
masks = tf.image.crop_and_resize(tf.cast(roi_masks, tf.float32), boxes,
box_ids,
config.MASK_SHAPE)
# Remove the extra dimension from masks.
masks = tf.squeeze(masks, axis=3)
# Threshold mask pixels at 0.5 to have GT masks be 0 or 1 to use with
# binary cross entropy loss.
masks = tf.round(masks)
# Append negative ROIs and pad bbox deltas and masks that
# are not used for negative ROIs with zeros.
rois = tf.concat([positive_rois, negative_rois], axis=0)
N = tf.shape(negative_rois)[0]
P = tf.maximum(config.TRAIN_ROIS_PER_IMAGE - tf.shape(rois)[0], 0)
rois = tf.pad(rois, [(0, P), (0, 0)])
roi_gt_boxes = tf.pad(roi_gt_boxes, [(0, N + P), (0, 0)])
roi_gt_class_ids = tf.pad(roi_gt_class_ids, [(0, N + P)])
deltas = tf.pad(deltas, [(0, N + P), (0, 0)])
masks = tf.pad(masks, [[0, N + P], (0, 0), (0, 0)])
return rois, roi_gt_class_ids, deltas, masks
最后返回的是:
rois: [TRAIN_ROIS_PER_IMAGE, (y1, x1, y2, x2)] in normalized coordinates
class_ids: [TRAIN_ROIS_PER_IMAGE]. Integer class IDs. Zero padded.
deltas: [TRAIN_ROIS_PER_IMAGE, NUM_CLASSES, (dy, dx, log(dh), log(dw))]
Class-specific bbox refinements.
masks: [TRAIN_ROIS_PER_IMAGE, height, width). Masks cropped to bbox
boundaries and resized to neural network output size.
通过rpn网络得到的anchor,选择出来正负样本,并计算出正样本和真实框的差距,以及要预测的mask的值,这些都是在后面的网络中计算损失函数需要的真实值。
1.6--Feature Pyramid Network Heads(fpn_classifier_graph)
该网络是maskrcnn的最后一层,与之并行的还有一个mask分支,在这里先介绍一下这个分类网络。
由1.5得到的roi的大小并不一样,因此,需要一个网络类似于fasterrcnn中的roipooling,将rois转换成大小一样的特征图。maskrcnn中使用的是PyramidROIAlign。PyramidROIAlign首先根据下面的公司计算每一个roi来自于金字塔特征的P2到P5的哪一层的特征:

# Assign each ROI to a level in the pyramid based on the ROI area.
y1, x1, y2, x2 = tf.split(boxes, 4, axis=2)
h = y2 - y1
w = x2 - x1
# Use shape of first image. Images in a batch must have the same size.
image_shape = parse_image_meta_graph(image_meta)['image_shape'][0]
# Equation 1 in the Feature Pyramid Networks paper. Account for
# the fact that our coordinates are normalized here.
# e.g. a 224x224 ROI (in pixels) maps to P4
#计算每个roi映射到哪一层的金字塔特征的输出上
image_area = tf.cast(image_shape[0] * image_shape[1], tf.float32)
roi_level = log2_graph(tf.sqrt(h * w) / (224.0 / tf.sqrt(image_area)))
roi_level = tf.minimum(5, tf.maximum(
2, 4 + tf.cast(tf.round(roi_level), tf.int32)))
roi_level = tf.squeeze(roi_level, 2)
然后从对应的特征图中取出坐标对应的区域,利用双线性插值的方式进行pooling操作。PyramidROIAlign会返回resize成相同大小的rois。
将得到的特征块输入到fpn_classifier_graph网络中,得到分类和回归值。
下面是fpn_classifier_graph网络的定义,
def fpn_classifier_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True,
fc_layers_size=1024):
"""Builds the computation graph of the feature pyramid network classifier
and regressor heads.
rois: [batch, num_rois, (y1, x1, y2, x2)] Proposal boxes in normalized
coordinates.
feature_maps: List of feature maps from different layers of the pyramid,
[P2, P3, P4, P5]. Each has a different resolution.
- image_meta: [batch, (meta data)] Image details. See compose_image_meta()
pool_size: The width of the square feature map generated from ROI Pooling.
num_classes: number of classes, which determines the depth of the results
train_bn: Boolean. Train or freeze Batch Norm layers
fc_layers_size: Size of the 2 FC layers
Returns:
logits: [N, NUM_CLASSES] classifier logits (before softmax)
probs: [N, NUM_CLASSES] classifier probabilities
bbox_deltas: [N, (dy, dx, log(dh), log(dw))] Deltas to apply to
proposal boxes
"""
# ROI Pooling
# Shape: [batch, num_boxes, pool_height, pool_width, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_classifier")([rois, image_meta] + feature_maps)
# Two 1024 FC layers (implemented with Conv2D for consistency)
x = KL.TimeDistributed(KL.Conv2D(fc_layers_size, (pool_size, pool_size), padding="valid"),
name="mrcnn_class_conv1")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn1')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(fc_layers_size, (1, 1)),
name="mrcnn_class_conv2")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn2')(x, training=train_bn)
x = KL.Activation('relu')(x)
shared = KL.Lambda(lambda x: K.squeeze(K.squeeze(x, 3), 2),
name="pool_squeeze")(x)
# Classifier head
mrcnn_class_logits = KL.TimeDistributed(KL.Dense(num_classes),
name='mrcnn_class_logits')(shared)
mrcnn_probs = KL.TimeDistributed(KL.Activation("softmax"),
name="mrcnn_class")(mrcnn_class_logits)
# BBox head
# [batch, boxes, num_classes * (dy, dx, log(dh), log(dw))]
x = KL.TimeDistributed(KL.Dense(num_classes * 4, activation='linear'),
name='mrcnn_bbox_fc')(shared)
# Reshape to [batch, boxes, num_classes, (dy, dx, log(dh), log(dw))]
s = K.int_shape(x)
mrcnn_bbox = KL.Reshape((s[1], num_classes, 4), name="mrcnn_bbox")(x)
return mrcnn_class_logits, mrcnn_probs, mrcnn_bbox
返回值为:
Returns:
logits: [N, NUM_CLASSES] classifier logits (before softmax)
probs: [N, NUM_CLASSES] classifier probabilities
bbox_deltas: [N, (dy, dx, log(dh), log(dw))] Deltas to apply to
proposal boxes
1.7--build_fpn_mask_graph
mask网络的输入和1.6网络的输入值是一样的,也会经过PyramidROIAlign(这个地方可以进行一个提取,放在最后的网络之前)
#创建mask的分类头
def build_fpn_mask_graph(rois, feature_maps, image_meta,
pool_size, num_classes, train_bn=True):
"""Builds the computation graph of the mask head of Feature Pyramid Network.
rois: [batch, num_rois, (y1, x1, y2, x2)] Proposal boxes in normalized
coordinates.
feature_maps: List of feature maps from different layers of the pyramid,
[P2, P3, P4, P5]. Each has a different resolution.
image_meta: [batch, (meta data)] Image details. See compose_image_meta()
pool_size: The width of the square feature map generated from ROI Pooling.
num_classes: number of classes, which determines the depth of the results
train_bn: Boolean. Train or freeze Batch Norm layers
Returns: Masks [batch, roi_count, height, width, num_classes]
"""
# ROI Pooling
# Shape: [batch, boxes, pool_height, pool_width, channels]
x = PyramidROIAlign([pool_size, pool_size],
name="roi_align_mask")([rois, image_meta] + feature_maps)
# Conv layers
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv1")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn1')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv2")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn2')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv3")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn3')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"),
name="mrcnn_mask_conv4")(x)
x = KL.TimeDistributed(BatchNorm(),
name='mrcnn_mask_bn4')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2DTranspose(256, (2, 2), strides=2, activation="relu"),
name="mrcnn_mask_deconv")(x)
x = KL.TimeDistributed(KL.Conv2D(num_classes, (1, 1), strides=1, activation="sigmoid"),
name="mrcnn_mask")(x)
return x
有一个细节需要注意的就是1.6经过PyramidROIAlign得到的特征图是7*7大小的,二1.7经过PyramidROIAlign得到的特征图大小是14*14
最后的返回值是:
Returns: Masks [batch, roi_count, height, width, num_classes]
1.8 --损失函数
maskrcnn中总共有五个损失函数,分别是rpn网络的两个损失,分类的两个损失,以及mask分支的损失函数。前四个损失函数与fasterrcnn的损失函数一样,最后的mask损失函数的采用的是mask分支对于每个RoI有Km2 维度的输出。K个(类别数)分辨率为m*m的二值mask。
因此作者利用了a per-pixel sigmoid,并且定义 Lmask 为平均二值交叉熵损失(the average binary cross-entropy loss).
对于一个属于第k个类别的RoI, Lmask 仅仅考虑第k个mask(其他的掩模输入不会贡献到损失函数中)。这样的定义会允许对每个类别都会生成掩模,并且不会存在类间竞争
# Losses
rpn_class_loss = KL.Lambda(lambda x: rpn_class_loss_graph(*x), name="rpn_class_loss")(
[input_rpn_match, rpn_class_logits])
rpn_bbox_loss = KL.Lambda(lambda x: rpn_bbox_loss_graph(config, *x), name="rpn_bbox_loss")(
[input_rpn_bbox, input_rpn_match, rpn_bbox])
class_loss = KL.Lambda(lambda x: mrcnn_class_loss_graph(*x), name="mrcnn_class_loss")(
[target_class_ids, mrcnn_class_logits, active_class_ids])
bbox_loss = KL.Lambda(lambda x: mrcnn_bbox_loss_graph(*x), name="mrcnn_bbox_loss")(
[target_bbox, target_class_ids, mrcnn_bbox])
mask_loss = KL.Lambda(lambda x: mrcnn_mask_loss_graph(*x), name="mrcnn_mask_loss")(
[target_mask, target_class_ids, mrcnn_mask])
1.9--总的模型
上面只是介绍了模型的每一步,要把各个模型串联起来,才可以形成一个整体的网络,网络的整体定义如下:
# Model
inputs = [input_image, input_image_meta,
input_rpn_match, input_rpn_bbox, input_gt_class_ids, input_gt_boxes, input_gt_masks]
if not config.USE_RPN_ROIS:
inputs.append(input_rois)
outputs = [rpn_class_logits, rpn_class, rpn_bbox,
mrcnn_class_logits, mrcnn_class, mrcnn_bbox, mrcnn_mask,
rpn_rois, output_rois,
rpn_class_loss, rpn_bbox_loss, class_loss, bbox_loss, mask_loss]
model = KM.Model(inputs, outputs, name='mask_rcnn')
2--模型的训练
在模型训练的时候,会根据配置文件读取信息,将数据读取到一个dataset的对象中,会计算出图片真实的anchor和 mask在模型的rpn阶段计算loss值使用。这个代码可以设置每次训练的层数,甚至可以只训练某基层。训练的时候最重要的是data_generator的生成:
def data_generator(dataset, config, shuffle=True, augment=False, augmentation=None,
random_rois=0, batch_size=1, detection_targets=False,
no_augmentation_sources=None):
"""A generator that returns images and corresponding target class ids,
bounding box deltas, and masks.
dataset: The Dataset object to pick data from
config: The model config object
shuffle: If True, shuffles the samples before every epoch
augment: (deprecated. Use augmentation instead). If true, apply random
image augmentation. Currently, only horizontal flipping is offered.
augmentation: Optional. An imgaug (https://github.com/aleju/imgaug) augmentation.
For example, passing imgaug.augmenters.Fliplr(0.5) flips images
right/left 50% of the time.
random_rois: If > 0 then generate proposals to be used to train the
network classifier and mask heads. Useful if training
the Mask RCNN part without the RPN.
batch_size: How many images to return in each call
detection_targets: If True, generate detection targets (class IDs, bbox
deltas, and masks). Typically for debugging or visualizations because
in trainig detection targets are generated by DetectionTargetLayer.
no_augmentation_sources: Optional. List of sources to exclude for
augmentation. A source is string that identifies a dataset and is
defined in the Dataset class.
Returns a Python generator. Upon calling next() on it, the
generator returns two lists, inputs and outputs. The contents
of the lists differs depending on the received arguments:
inputs list:
- images: [batch, H, W, C]
- image_meta: [batch, (meta data)] Image details. See compose_image_meta()
- rpn_match: [batch, N] Integer (1=positive anchor, -1=negative, 0=neutral)
- rpn_bbox: [batch, N, (dy, dx, log(dh), log(dw))] Anchor bbox deltas.
- gt_class_ids: [batch, MAX_GT_INSTANCES] Integer class IDs
- gt_boxes: [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)]
- gt_masks: [batch, height, width, MAX_GT_INSTANCES]. The height and width
are those of the image unless use_mini_mask is True, in which
case they are defined in MINI_MASK_SHAPE.
outputs list: Usually empty in regular training. But if detection_targets
is True then the outputs list contains target class_ids, bbox deltas,
and masks.
"""
b = 0 # batch item index
image_index = -1
image_ids = np.copy(dataset.image_ids)
error_count = 0
no_augmentation_sources = no_augmentation_sources or []
# Anchors
# [anchor_count, (y1, x1, y2, x2)] [[256 256] [128 128][ 64 64][ 32 32][ 16 16]]
backbone_shapes = compute_backbone_shapes(config, config.IMAGE_SHAPE)
anchors = utils.generate_pyramid_anchors(config.RPN_ANCHOR_SCALES,
config.RPN_ANCHOR_RATIOS,
backbone_shapes,
config.BACKBONE_STRIDES,
config.RPN_ANCHOR_STRIDE)
# Keras requires a generator to run indefinitely.
while True:
try:
# Increment index to pick next image. Shuffle if at the start of an epoch.
image_index = (image_index + 1) % len(image_ids)
if shuffle and image_index == 0:
np.random.shuffle(image_ids)
# Get GT bounding boxes and masks for image.
image_id = image_ids[image_index]
# If the image source is not to be augmented pass None as augmentation
if dataset.image_info[image_id]['source'] in no_augmentation_sources:
image, image_meta, gt_class_ids, gt_boxes, gt_masks = \
load_image_gt(dataset, config, image_id, augment=augment,
augmentation=None,
use_mini_mask=config.USE_MINI_MASK)
else:
image, image_meta, gt_class_ids, gt_boxes, gt_masks = \
load_image_gt(dataset, config, image_id, augment=augment,
augmentation=augmentation,
use_mini_mask=config.USE_MINI_MASK)
# Skip images that have no instances. This can happen in cases
# where we train on a subset of classes and the image doesn't
# have any of the classes we care about.
if not np.any(gt_class_ids > 0):
continue
# RPN Targets rpn_match代表anchor是正样本还是负样本还是中性样本
rpn_match, rpn_bbox = build_rpn_targets(image.shape, anchors,
gt_class_ids, gt_boxes, config)
# Mask R-CNN Targets
if random_rois:
rpn_rois = generate_random_rois(
image.shape, random_rois, gt_class_ids, gt_boxes)
if detection_targets:
rois, mrcnn_class_ids, mrcnn_bbox, mrcnn_mask =\
build_detection_targets(
rpn_rois, gt_class_ids, gt_boxes, gt_masks, config)
# Init batch arrays
if b == 0:
batch_image_meta = np.zeros(
(batch_size,) + image_meta.shape, dtype=image_meta.dtype)
batch_rpn_match = np.zeros(
[batch_size, anchors.shape[0], 1], dtype=rpn_match.dtype)
batch_rpn_bbox = np.zeros(
[batch_size, config.RPN_TRAIN_ANCHORS_PER_IMAGE, 4], dtype=rpn_bbox.dtype)
batch_images = np.zeros(
(batch_size,) + image.shape, dtype=np.float32)
batch_gt_class_ids = np.zeros(
(batch_size, config.MAX_GT_INSTANCES), dtype=np.int32)
batch_gt_boxes = np.zeros(
(batch_size, config.MAX_GT_INSTANCES, 4), dtype=np.int32)
batch_gt_masks = np.zeros(
(batch_size, gt_masks.shape[0], gt_masks.shape[1],
config.MAX_GT_INSTANCES), dtype=gt_masks.dtype)
if random_rois:
batch_rpn_rois = np.zeros(
(batch_size, rpn_rois.shape[0], 4), dtype=rpn_rois.dtype)
if detection_targets:
batch_rois = np.zeros(
(batch_size,) + rois.shape, dtype=rois.dtype)
batch_mrcnn_class_ids = np.zeros(
(batch_size,) + mrcnn_class_ids.shape, dtype=mrcnn_class_ids.dtype)
batch_mrcnn_bbox = np.zeros(
(batch_size,) + mrcnn_bbox.shape, dtype=mrcnn_bbox.dtype)
batch_mrcnn_mask = np.zeros(
(batch_size,) + mrcnn_mask.shape, dtype=mrcnn_mask.dtype)
# If more instances than fits in the array, sub-sample from them.
if gt_boxes.shape[0] > config.MAX_GT_INSTANCES:
ids = np.random.choice(
np.arange(gt_boxes.shape[0]), config.MAX_GT_INSTANCES, replace=False)
gt_class_ids = gt_class_ids[ids]
gt_boxes = gt_boxes[ids]
gt_masks = gt_masks[:, :, ids]
# Add to batch
batch_image_meta[b] = image_meta
batch_rpn_match[b] = rpn_match[:, np.newaxis]
batch_rpn_bbox[b] = rpn_bbox
batch_images[b] = mold_image(image.astype(np.float32), config)
batch_gt_class_ids[b, :gt_class_ids.shape[0]] = gt_class_ids
batch_gt_boxes[b, :gt_boxes.shape[0]] = gt_boxes
batch_gt_masks[b, :, :, :gt_masks.shape[-1]] = gt_masks
if random_rois:
batch_rpn_rois[b] = rpn_rois
if detection_targets:
batch_rois[b] = rois
batch_mrcnn_class_ids[b] = mrcnn_class_ids
batch_mrcnn_bbox[b] = mrcnn_bbox
batch_mrcnn_mask[b] = mrcnn_mask
b += 1
# Batch full?
if b >= batch_size:
inputs = [batch_images, batch_image_meta, batch_rpn_match, batch_rpn_bbox,
batch_gt_class_ids, batch_gt_boxes, batch_gt_masks]
outputs = []
if random_rois:
inputs.extend([batch_rpn_rois])
if detection_targets:
inputs.extend([batch_rois])
# Keras requires that output and targets have the same number of dimensions
batch_mrcnn_class_ids = np.expand_dims(
batch_mrcnn_class_ids, -1)
outputs.extend(
[batch_mrcnn_class_ids, batch_mrcnn_bbox, batch_mrcnn_mask])
yield inputs, outputs
# start a new batch
b = 0
except (GeneratorExit, KeyboardInterrupt):
raise
except:
# Log it and skip the image
logging.exception("Error processing image {}".format(
dataset.image_info[image_id]))
error_count += 1
if error_count > 5:
raise
3--模型的inference
在模型的预测阶段,我们调用的是模型的detect方法,首先读取要预测的图片。然后调用predict方法
# Run object detection
detections, _, _, mrcnn_mask, _, _, _ =\
self.keras_model.predict([molded_images, image_metas, anchors], verbose=0)
得到的预测结果是归一化以后的结果,预测的mask也是在28*28的大小的结果,因此,要利用双线性插值的方式将mask的大小转换到和原始图片一样的大小上。
def unmold_detections(self, detections, mrcnn_mask, original_image_shape,
image_shape, window):
"""Reformats the detections of one image from the format of the neural
network output to a format suitable for use in the rest of the
application.
detections: [N, (y1, x1, y2, x2, class_id, score)] in normalized coordinates
mrcnn_mask: [N, height, width, num_classes]
original_image_shape: [H, W, C] Original image shape before resizing
image_shape: [H, W, C] Shape of the image after resizing and padding
window: [y1, x1, y2, x2] Pixel coordinates of box in the image where the real
image is excluding the padding.
Returns:
boxes: [N, (y1, x1, y2, x2)] Bounding boxes in pixels
class_ids: [N] Integer class IDs for each bounding box
scores: [N] Float probability scores of the class_id
masks: [height, width, num_instances] Instance masks
"""
# How many detections do we have?
# Detections array is padded with zeros. Find the first class_id == 0.
zero_ix = np.where(detections[:, 4] == 0)[0]
N = zero_ix[0] if zero_ix.shape[0] > 0 else detections.shape[0]
# Extract boxes, class_ids, scores, and class-specific masks
boxes = detections[:N, :4]
class_ids = detections[:N, 4].astype(np.int32)
scores = detections[:N, 5]
masks = mrcnn_mask[np.arange(N), :, :, class_ids]
# Translate normalized coordinates in the resized image to pixel
# coordinates in the original image before resizing
window = utils.norm_boxes(window, image_shape[:2])
wy1, wx1, wy2, wx2 = window
shift = np.array([wy1, wx1, wy1, wx1])
wh = wy2 - wy1 # window height
ww = wx2 - wx1 # window width
scale = np.array([wh, ww, wh, ww])
# Convert boxes to normalized coordinates on the window
boxes = np.divide(boxes - shift, scale)
# Convert boxes to pixel coordinates on the original image
boxes = utils.denorm_boxes(boxes, original_image_shape[:2])
# Filter out detections with zero area. Happens in early training when
# network weights are still random
exclude_ix = np.where(
(boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1]) <= 0)[0]
if exclude_ix.shape[0] > 0:
boxes = np.delete(boxes, exclude_ix, axis=0)
class_ids = np.delete(class_ids, exclude_ix, axis=0)
scores = np.delete(scores, exclude_ix, axis=0)
masks = np.delete(masks, exclude_ix, axis=0)
N = class_ids.shape[0]
# Resize masks to original image size and set boundary threshold.
full_masks = []
for i in range(N):
# Convert neural network mask to full size mask
full_mask = utils.unmold_mask(masks[i], boxes[i], original_image_shape)
full_masks.append(full_mask)
full_masks = np.stack(full_masks, axis=-1)\
if full_masks else np.empty(original_image_shape[:2] + (0,))
return boxes, class_ids, scores, full_masks
下面的代码是将神经网络预测得到的mask转换到原始的图片上:
def unmold_mask(mask, bbox, image_shape):
"""Converts a mask generated by the neural network to a format similar
to its original shape.
mask: [height, width] of type float. A small, typically 28x28 mask.
bbox: [y1, x1, y2, x2]. The box to fit the mask in.
Returns a binary mask with the same size as the original image.
"""
threshold = 0.5
y1, x1, y2, x2 = bbox
mask = skimage.transform.resize(mask, (y2 - y1, x2 - x1), order=1, mode="constant")
mask = np.where(mask >= threshold, 1, 0).astype(np.bool)
# Put the mask in the right location.
full_mask = np.zeros(image_shape[:2], dtype=np.bool)
full_mask[y1:y2, x1:x2] = mask
return full_mask