TensorFlow张量
TensorFlow简介:
官网上对TensorFlow的介绍是,一个使用数据流图(data flow graphs)技术来进行数值计算的开源软件库。数据流图中的节点,代表数值运算;节点节点之间的边,代表多维数据(tensors)之间的某种联系。我们可以在多种设备(含有CPU或GPU)上通过简单的API调用来使用该系统的功能。
TensorFlow包含构建数据流图与计算数据流图等基本步骤,图中的节点表示数学操作,图中连结各节点的边表示多维数组,即:tensors(张量)。 张量是TensorFlow最核心的组件,所有运算和优化都是基于张量进行的。张量是基于向量和矩阵的推广,可以将标量看为零阶张量,矢量看做一阶张量,矩阵看做二阶张量(后面详细介绍)。
数据流图是描述有向图中的数值计算过程。有向图中的节点通常代表数学运算,但也可以表示数据的输入、输出和读写等操作;有向图中的边表示节点之间的某种联系,它负责传输多维数据(Tensors)。图中这些tensors的flow也就是TensorFlow的命名来源。
基本使用:
-
将计算流程表示成图;
-
通过Sessions来执行图计算;
-
将数据表示为tensors;
-
使用Variables来保持状态信息;
-
分别使用feeds和fetches来填充数据和抓取任意的操作结果;
TensorFlow初识,简单实例
import tensorflow as tf
a =tf.placeholder("float")
b =tf.placeholder("float")
y = tf.multiply(a,b)
sess = tf.Session()
print(sess.run(y, feed_dict={a: 3, b: 3}))上面代码中,首先导入TensorFlow,然后tf.placeholder("float")定义a和b两个浮点类型的变量,tf.multiply(a,b)表示两个变量相乘操作,常用的算术还有:
| Operation | Description |
| tf.add | sum |
| tf.subtract | substraction |
| tf.multiply | multiplication |
| tf.div | division |
| tf.mod | module |
| tf.abs | return the absolute value |
| tf.neg | return negative value |
| tf.sign | return the sign |
| tf.inv | returns the inverse |
| tf.square | calculates the square |
| tf.round | returns the nearest integer |
| tf.sqrt | calculates the square root |
| tf.pow | calculates the power |
| tf.exp | calculates the exponential |
| tf.log | calculates the logarithm |
| tf.maximum | returns the maximum |
| tf.minimum | returns the minimum |
| tf.cos | calculates the cosine |
| tf.sin | calculates the sine |
如果两种不同类型计算时会报错,需要tf.cast()转换类型,例如:
tf.subtract(tf.constant(3.0),tf.constant(1))
"""
TypeError: Input 'y' of 'Sub' Op has type int32 that does not
match type float32 of argument 'x'.
"""
上面代码需改为:
tf.subtract(tf.cast(tf.constant(3.0), tf.int32), tf.constant(1))另外,还会用到的矩阵计算方法:
| Operation | Description |
| tf.diag | returns a diagonal tensor with a given diagonal values |
| tf.transpose | returns the transposes of the argument |
| tf.matmul | returns a tensor product of multiplying two tensors listed as arguments |
| tf.matrix_determinant | returns the determinant of the square matrix specified as an argument |
| tf.matrix_inverse | returns the inverse of the square matrix specified as an argument |
接下来 tf.Session()语句表示创建一个session,这是最重要的一步,它用来计算生成的符号表达式。到这一步TensorFlow代码还没有真正被执行, 而调用run()方法后算法才真正被执行。可以看出,TensorFlow既是一个表示机器学习算法的接口,又是对机器学习算法的实现。
为了抓取输出结果,在执行session的run函数后,通过print函数打印状态信息。
填充(Feeds):
TensorFlow提供的机制:先创建特定数据类型的占位符(placeholder),之后再进行数据的填充("feed_dict= ");如果不对placeholder()的变量进行数据填充,将会引发错误。
基本数据类型:
| 数据类型 | Python 类型 | 描述 |
|---|---|---|
DT_FLOAT |
tf.float32 |
32 位浮点数. |
DT_DOUBLE |
tf.float64 |
64 位浮点数. |
DT_INT64 |
tf.int64 |
64 位有符号整型. |
DT_INT32 |
tf.int32 |
32 位有符号整型. |
DT_INT16 |
tf.int16 |
16 位有符号整型. |
DT_INT8 |
tf.int8 |
8 位有符号整型. |
DT_UINT8 |
tf.uint8 |
8 位无符号整型. |
DT_STRING |
tf.string |
可变长度的字节数组.每一个张量元素都是一个字节数组. |
DT_BOOL |
tf.bool |
布尔型. |
DT_COMPLEX64 |
tf.complex64 |
由两个32位浮点数组成的复数:实数和虚数. |
DT_QINT32 |
tf.qint32 |
用于量化Ops的32位有符号整型. |
DT_QINT8 |
tf.qint8 |
用于量化Ops的8位有符号整型. |
DT_QUINT8 |
tf.quint8 |
用于量化Ops的8位无符号整型. |
张量的阶
TensorFlow用张量表示所有的数据,张量可看成一个n维的数组或列表,在图中的节点之间流通。张量的维数称为阶,注:张量的阶和矩阵的阶不是同一个概念。下面的张量(使用Python的list定义)是2阶:
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]| 阶 | 数学实例 | Python 例子 |
|---|---|---|
| 0 | 纯量 (只有大小) | s = 1 |
| 1 | 向量(大小和方向) | v = [1, 2, 3] |
| 2 | 矩阵(数据表) | m = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] |
| 3 | 3阶张量 (数据立体) | t = [[[2], [4], [6]], [[8], [10], [12]], [[14], [16], [18]]] |
| n | n阶 | .... |
张量的形状
TensorFlow使用三种记号描述张量的维度:阶,形状及维数,它们之间的关系:
| 阶 | 形状 | 维数 | 实例 |
|---|---|---|---|
| 0 | [ ] | 0-D | 一个 0维张量. 一个纯量. |
| 1 | [D0] | 1-D | 一个1维张量的形式[5]. |
| 2 | [D0, D1] | 2-D | 一个2维张量的形式[3, 4]. |
| 3 | [D0, D1, D2] | 3-D | 一个3维张量的形式 [1, 4, 3]. |
| n | [D0, D1, ... Dn] | n-D | 一个n维张量的形式 [D0, D1, ... Dn]. |
张量的一些常用操作:
| Operation | Description |
| tf.shape | To find a shape of a tensor |
| tf.size | To find the size of a tensor |
| tf.rank | To find a rank of a tensor |
| tf.reshape | To change the shape of a tensor keeping the same elements contained |
| tf.squeeze | To delete in a tensor dimensions of size 1 |
| tf.expand_dims | To insert a dimension to a tensor |
| tf.slice | To remove a portions of a tensor |
| tf.split | To divide a tensor into several tensors along one dimension |
| tf.tile | To create a new tensor replicating a tensor multiple times |
| tf.concat | To concatenate tensors in one dimension |
| tf.reverse | To reverse a specific dimension of a tensor |
| tf.transpose | To transpose dimensions in a tensor |
| tf.gather | To collect portions according to an index |
例如,将一个2维张量扩展为3维:
vectors = tf.constant(conjunto_puntos)
extended_vectors = tf.expand_dims(vectors, 0)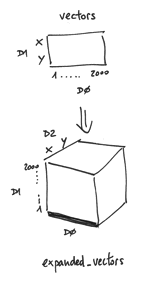
print (expanded_vectors.get_shape())执行上面这句,可以得到扩展后张量的维度。
TensorFlow计算图:
有了张量和基于张量的各种操作,之后需要将各种操作整合起来,输出结果。但不幸的是,随着操作种类和数量的增多,有可能引发各种意想不到的问题,包括多个操作之间应该并行还是顺次执行,如何协同各种不同的底层设备,以及如何避免各种类型的冗余操作等等。这些问题有可能拉低整个深度学习网络的运行效率或者引入不必要的Bug,计算图正是为解决这一问题产生的。
论文《Learning Deep Architectures for AI》作者用不同的占位符(*,+,sin)构成操作结点,以字母x、a、b构成变量结点,以有向线段将这些结点连接起来,组成一个表征运算逻辑关系的清晰明了的“图”型数据结构,这就是最初的计算图。
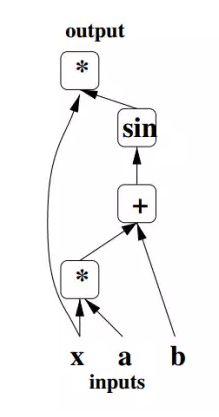
计算图的引入可以让开发者从宏观上俯瞰整个神经网络的内部结构,就好像编译器可以从整个代码的角度决定如何分配寄存器那样,计算图也可以从宏观上决定代码运行时的GPU内存分配,以及分布式环境中不同底层设备间的相互协作方式。除此之外,现在也有许多深度学习框架将计算图应用于模型调试,可以实时输出当前某一操作类型的文本描述。
实例1:
node1 = tf.constant(3.0, dtype=tf.float32)
node2 = tf.constant(4.0) # also tf.float32 implicitly
print(node1, node2)node1和node2是constant,常量不可改变,其输出结果:
Tensor("Const_2:0", shape=(), dtype=float32) Tensor("Const_3:0", shape=(), dtype=float32)上面并没有直接输出3.0和4.0,而是输出可以生成3.0和4.0的两个张量,如果想要得到3.0和4.0,需要上面介绍的session和run操作:
sess = tf.Session()
print(sess.run([node1, node2]))计算图是将节点列到一个图中的一系列操作,其输入是节点(nodes),输出也是node。或者更复杂一点,操作也是node:
实例2:
node3 = tf.add(node1, node2)
print("node3:", node3)
print("sess.run(node3):", sess.run(node3))
输出结果为:
node3: Tensor("Add_1:0", shape=(), dtype=float32)
sess.run(node3): 7.0为了使算法容易理解,TensorFlow中的可视化工具Tensorboard包含了一些debug函数与优化程序,可以察看不同类型的参数统计结果与图中的计算细节(这部分以后参照实例学习一下)。
实例3:
输入可以是任意量,例如构建模型:y=w*x+b,w和b一定时,x是可变量:
W = tf.Variable([.3], dtype=tf.float32)
b = tf.Variable([-.3], dtype=tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W*x + bW和b是Variable,执行上面的语句,W和b并没有被初始化,如果执行程序,需要下面的初始化语句:
init = tf.global_variables_initializer()
完整实例如下:
import tensorflow as tf
W = tf.Variable([.5], dtype=tf.float32)
b = tf.Variable([-.5], dtype=tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W*x + b
#print("linear_model:",linear_model)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
print(sess.run(linear_model, {x: [1, 2, 3, 4]}))
输出结果为:[ 0. 0.5 1. 1.5]
实例4:
import tensorflow as tf
W = tf.Variable(1)
assign_W = W.assign(10)#修改变量方法,assign
with tf.Session() as sess:
sess.run(W.initializer)
print(W.eval())
sess.run(assign_W)
print(W.eval())assign只是一个函数,并且不需要初始化,但是assign_add()和assign_sub()需要初始化。
import tensorflow as tf
W = tf.Variable(10)
sess1 = tf.Session()
sess2 = tf.Session()
sess1.run(W.initializer)
sess2.run(W.initializer)
print('W add 1=',sess1.run(W.assign_add(1)))
print('W sun 2=',sess2.run(W.assign_sub(2)))
sess1.close()
sess2.close()张量的维度(秩):Rank/Order 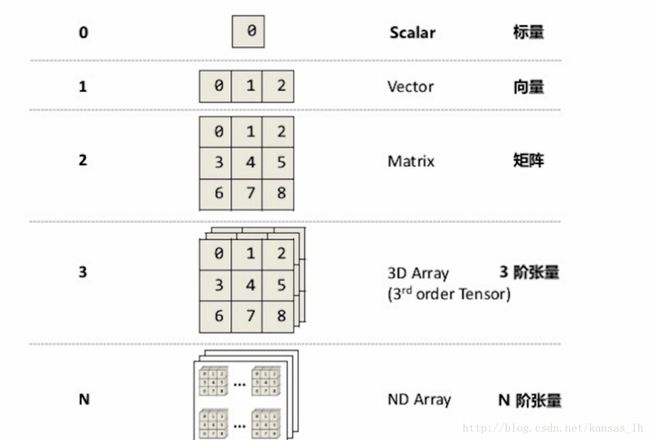
Rank为0、1、2时分别称为标量、向量和矩阵,Rank为3时是3阶张量,Rank大于3时是N阶张量。这些标量、向量、矩阵和张量里每一个元素被称为tensor element(张量的元素),且同一个张量里元素的类型是保持一样的。
Tensor的属性
1.数据类型dtype d是data的首字母,type是类型的意思。tensor里每一个元素的数据类型是一样的。类似于Numpy中ndarray.dtype,tensorflow里的数据类型可以有很多种,比方说tf.float32就是32位的浮点数,tf.int8就是8位的整型,tf.unit8就是8位的无符号整型,tf.string为字符串等等。
2.形状Shape 类似于Numpy中ndarray.shape,比方说一个2行3列的二维矩阵,他的形状就是2行3列。
3.其他属性 device是tensor在哪个设备上被计算出来的,graph是tensor所属的图,name是tensor的名字
,op是operation的缩写是产生这个tensor的操作运算,对应图上的结点,这些结点接收一些tensor作为输入并输出一些tensor。还有等等属性,可以查阅官网。
tensor和Numpy有很多共同的性质,tensorflow的作者应该参考了numpy(个人臆测)
几种Tensor
1.Constant(常量)是值不能改变的一种tensor,定义在tf.constant这个类里。
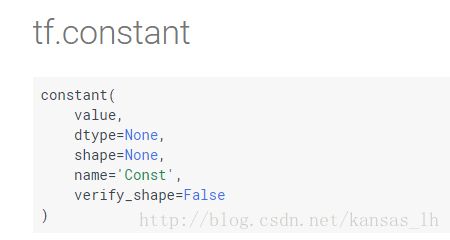
constant中有几个属性,value就是constant的数值,我们可以给他赋值,比方说0维的scalar,1维的Vector,2维的matrix或者是3维的张量。dtype、shape、name刚都有写过,verify_shape是布尔值,用于验证值的形状。除了value外都不一定要指定,可以有默认的值但是必须要有一个value。
2.Variable(变量)是值可以改变的一种tensor,定义在tf.Variable这个类中。构造函数如下图,我也看不懂其实。 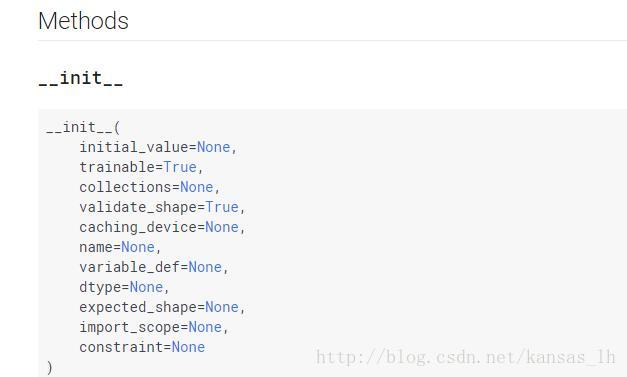
3.Placeholder(占位符)先占住一个固定的位置,之后在往里面添加值的一种Tensor。定义在tf.placeholder中。这里只有三个属性如下图。并没有value,因为赋值后就不是占位符了。只有dtype,shape,name三个属性。赋值的机制用到了python中字典,即feed_dict。 
x = tf.palceholder(tf.float32, shape=(1024, 1024))
y = tf.matmul(x, x)
with if.Session() as sess:
print(sess.run(y))
rand_array = np.random.rand(1024, 1024)
print(sess.run(y, feed_dict = {x: rand_array}))- 1
- 2
- 3
- 4
- 5
- 6
比刚说官网的例子定义了x占位符,数值类型是tf.float32,形状是1024*1024的二维矩阵。在用会话正式运行图的时候用feed_dict,首先给一个键后加真实的值。
4.SparseTensor(稀疏张量)是一种稀疏的Tensor,类似线代中稀疏矩阵。定义时只需要定义非0的数,其他的数会自动填充。 
Tensor表示法 
tf.Tensor就是名字,’Const’是名字。0是索引,表示张量是这个计算中产生的第几个。shape=()是形状,这个是标量所以是空,dtype为数据类型。