python爬虫小项目:爬取百度贴吧图片
前一段时间,通过对爬虫的学习,完成了爬取百度贴吧帖子和爬取糗事百科段子。看着自己爬取下来的文字,心里也是满满的自豪感!
再次打开贴吧,在浏览时发现贴吧也是包含着大量图片,既然爬取下了贴吧文字,那么为何不将百度贴吧的图片爬取下来呢?
说干就干!(代码为python3.x版)
本篇目标
1.对百度贴吧的任意帖子的图片部分进行抓取
2.指定是否只抓取楼主发帖内容图片
3.将抓取到的图片保存到程序目录下
要完成目标,我们先从小方面做起
一.先完成对指定页面图片的爬取
先爬取一个某个页面的图片,链接如下:
http://tieba.baidu.com/p/3223379048?see_lz=1(1)获取页面代码
import urllib.request
import re
def getPage():
url='http://tieba.baidu.com/p/3223379048?see_lz=1'
request=urllib.request.Request(url) #构建请求的request
response=urllib.request.urlopen(request) #利用urlopen获取页面代码
return response.read().decode('utf-8') #以utf-8编码对字符串进行解码,获得字符串类型对象
print(getPage())爬取下来的url页面源码过长就不放上来了。
(2)获取页面中想要的图片位置
把鼠标放在谷歌浏览器中想要爬取的内容上,点击右键,选择"检查",打开源码。大家也可以用其他方式查看。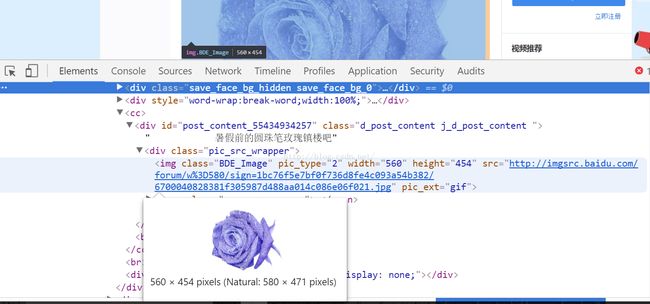
可以写出正则表达式如下:(不明白的可以学习一下正则表达式)
'![]()
注:
发现存在一些帖子的源码不一样(加了一些前缀什么的),大家可以视情况自行更改正则表达式。
说明:
(1).*? 是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是会尽可能短地做匹配。
(2)(.*?)代表一个分组,是我们需要的内容。
承接上面,代码如下:
def getIMG():
page=getPage()
pattern=re.compile('![]() print(getIMG())
print(getIMG())
结果举例如下(并非全部匹配结果,结果太长);
['http://imgsrc.baidu.com/forum/w%3D580/sign=1bc76f5e7bf0f736d8fe4c093a54b382/6700040828381f305987d488aa014c086e06f021.jpg', 'http://imgsrc.baidu.com/forum/w%3D580/sign=6f730e3661d0f703e6b295d438fa5148/a820daf9d72a6059c04db93b2b34349b033bba66.jpg', 'http://imgsrc.baidu.com/forum/w%3D580/sign=e586e6c5b01c8701d6b6b2ee177e9e6e/a0c13e6d55fbb2fb88e300334c4a20a44723dcf3.jpg', 'http://imgsrc.baidu.com/forum/w%3D580/sign=f15bb4a549ed2e73fce98624b701a16d/f1d5523d269759eefa4c3beab1fb43166d22dfa7.jpg'](3).将获取的数据下载到本地:
def getIMG(x):
page=getPage()
pattern=re.compile('![]()
(1)使用了urlretrieve方法
urlretrieve表示:直接将远程数据下载到本地。
和urlopen不同的是
urllib.urlopen(url[, data[, proxies]]) 表示:创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。
(2)通过一个for循环对获取的图片链接进行遍历,因为图片数量较多,x变量是我们在下载图片时的计数变量,同时也是命名变量,命名规则通过x变量加1。保存的位置默认为程序的存放目录
完整代码如下:
import urllib.request
import re
def getPage():
url='http://tieba.baidu.com/p/3223379048?see_lz=1'
request=urllib.request.Request(url)
response=urllib.request.urlopen(request)
return response.read().decode('utf-8')
#以utf-8编码对字符串进行解码,获得字符串类型对象
def getIMG(x):
page=getPage()
pattern=re.compile('![]()
完成结果如下: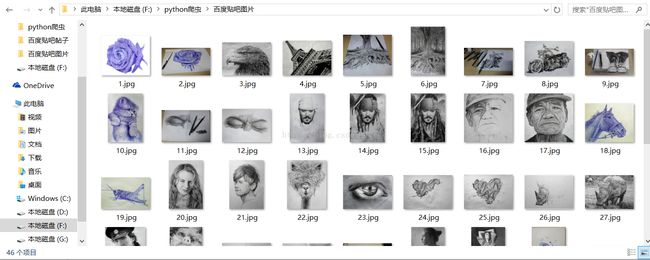
完成到这里,看着这么多图片被爬取成功,是不是很高兴?
可是我们只是完成了对指定页面的图片爬取,离我们的目标还差一些步骤。继续进行吧!
二.对百度贴吧的任意帖子的图片部分进行抓取,指定是否只抓取楼主发帖内容图片
我们想先将以上代码优化一下,创建一个百度贴吧图片类,调用功能:
import urllib.request
import re
class bdtbpicture:
def getPage(self,url):
request=urllib.request.Request(url)
response=urllib.request.urlopen(request)
return response.read().decode('utf-8')
#以utf-8编码对字符串进行解码,获得字符串类型对象
def getIMG(self,page,x):
pattern=re.compile('![]()
观察贴吧URL,我们可以把URL分为两部分,一部分为基础部分,一部分为参数部分。
例如,上面的URL我们划分基础部分是 http://tieba.baidu.com/p/3223379048,参数部分为?see_lz=1 (&pn=1表示的是页数,可改变数字从而改变页数)
为了完成目标,我们要让用户输入帖子代号,自动获取获取帖子页数,改变?see_lz=1的值,来确定是否只爬取楼主发言图片。改变&pn=1的值,遍历帖子,而不是只爬取帖子的其中一页。
知道了方向,我们就可以动手了。
(1).建立初始化函数,改变getPage函数(获取页码参数,更改url形式)
def __init__(self,baseurl,seeLZ):
self.baseURL=baseurl
self.seeLZ='?see_lz='+str(seeLZ)def getPage(self,pageNum):
url=self.baseURL+self.seeLZ+'&pn='+str(pageNum)
request=urllib.request.Request(url)
response=urllib.request.urlopen(request)
(2).获取帖子页数(更改正则表达式):
def getPageNum(self,page):
pattern = re.compile('def start(self):
indexPage = self.getPage(1)
pageNum = self.getPageNum(indexPage)
if pageNum == None:
print("URL已失效,请重试")
return
print("该帖子共有" + str(pageNum) + "页")
x=1
for i in range(1,int(pageNum)+1):
print("正在写入第" + str(i) + "页数据")
page = self.getPage(i)
x=self.getIMG(page,x)
print(u"写入任务完成") import urllib.request
import re
class bdtbpicture:
def __init__(self,baseurl,seeLZ):
self.baseURL=baseurl
self.seeLZ='?see_lz='+str(seeLZ)
def getPage(self,pageNum):
url=self.baseURL+self.seeLZ+'&pn='+str(pageNum)
request=urllib.request.Request(url)
response=urllib.request.urlopen(request)
return response.read().decode('utf-8','ignore')
def getPageNum(self,page):
pattern = re.compile('注意:
第12行getPage函数的return response.read().decode('utf-8','ignore')如果不加参数‘ignore’,可能会报如下错误,(初次运行还好,后面报错)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xca in position 139369: invalid continuation byte其中decode("utf-8", "ignore")表示:忽略其中有异常的编码,仅显示有效的编码
参考菜鸟教程
解释如下:
Python decode() 方法以 encoding 指定的编码格式解码字符串。默认编码为字符串编码。
decode()方法语法:
str.decode(encoding='UTF-8',errors='strict')
参考豆瓣:对于可能存在中英文混合的字符串,在使用python的.decode('utf-8')时有时会出错,但是不decode的话,那么纯中文的字符串就会转码错误,因此就需要对纯中文的字符串进行.decode('utf-8').encode('gbk','ignore'),而对中英文混合的字符串由于在decode会引起异常且无需对其进行decode就能正常显示,那么保持原格式就好。
参考轻峰
成果如下: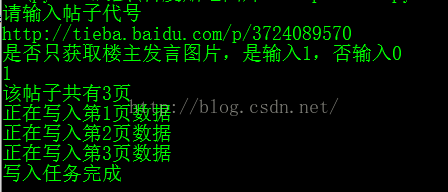
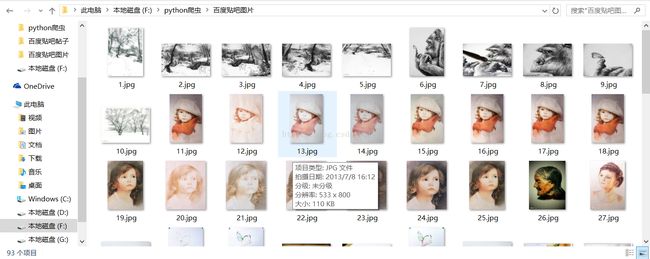
好了,现在我们就可以完成对百度贴吧的任意帖子的图片部分进行抓取,指定是否只抓取楼主发帖内容图片,将抓取到的图片保存到程序目录下等功能了。
心动了吗?大家快点动手吧!