griffin0.4.0安装
griffin0.4.0安装
- 安装步骤
- 安装依赖
- 解压griffin压缩包
- 在mysql中建立griffin用户
- griffin依赖表创建
- Hadoop和Hive
- Livy配置
- Elasticsearch配置
- griffin配置文件修改
- application.properties配置
- quartz.properties配置
- sparkProperties.json配置
- env_batch.json配置
- service/pom.xml文件配置(特别重要)
- 使用maven命令进行编译打包
- 拷贝jar包
- 更改spark master web ui的默认端口
- 启动hive源数据服务
- 启动griffin
- 启动成功验证
安装步骤
Apache Griffin是大数据的开源数据质量解决方案,支持批处理和流模式。它提供了一个统一的流程,可以从不同角度衡量您的数据质量,帮助您构建可信赖的数据资产,从而提高您对业务的信心。
安装依赖
依赖准备(参考官网http://griffin.apache.org/docs/quickstart-cn.html)
JDK (1.8 or later versions)
MySQL(version 5.6及以上)
Hadoop (2.6.0 or later)
Hive (version 2.x)
Spark (version 2.2.1)
Livy(livy-0.5.0-incubating)
ElasticSearch (5.0 or later versions)
组件介绍
Apache Hadoop:批量数据源,存储指标数据
Apache Hive: Hive Metastore
Apache Spark: 计算批量、实时指标
Apache Livy: 为服务提供 RESTful API 调用 Apache Spark
MySQL: 服务元数据
ElasticSearch:存储指标数据
Maven:项目管理工具软件,用于将griffin项目打包,后续执行griffin会用jar包运行,如果是生产库,则在本地安装maven打包后将jar包放到平台中运行griffin,因为maven运行时会安装好多组件,所以会需要外网。
相关链接:
hadoop安装:https://blog.csdn.net/genus_yang/article/details/87917853
hive安装:https://blog.csdn.net/genus_yang/article/details/87938796
spark安装:https://blog.csdn.net/genus_yang/article/details/88018392
livy安装:https://blog.csdn.net/genus_yang/article/details/88027799
mysql安装:https://blog.csdn.net/genus_yang/article/details/87939556
ElasticSearch安装:https://blog.csdn.net/genus_yang/article/details/88051980
maven下载链接:
http://maven.apache.org/download.cgi
虚拟机nat连接外网链接:https://blog.csdn.net/qq_40612124/article/details/79084276
解压griffin压缩包
[hadoop@master ~]$ unzip griffin-0.4.0-source-release.zip
在mysql中建立griffin用户
[root@master ~]# mysql -u root -p123
mysql> create user ‘griffin’ identified by ‘123’;
mysql> grant all privileges on . to ‘griffin’@’%’ with grant option;
mysql> grant all privileges on . to griffin@master identified by ‘123’;
mysql> flush privileges;
griffin依赖表创建
Griffin 使用了 Quartz 调度器调度任务,需要在mysql中创建 Quartz 调度器依赖的表
[root@master ~]# mysql -h master -u griffin -p123 -e "create database quartz "
[root@master ~]# mysql -h master -u griffin -p123 quartz < /home/hadoop/griffin-0.4.0/service/src/main/resources/Init_quartz_mysql_innodb.sql
Hadoop和Hive
#创建/home/spark_conf目录
[hadoop@master ~]$ hadoop fs -mkdir -p /home/spark_conf
#上传hive的配置文件hive-site.xml
[hadoop@master ~]$ hadoop fs -put /home/hadoop/hive-3.1.1/conf/hive-site.xml /home/spark_conf/
Livy配置
更新livy/conf下的livy.conf配置文件
[hadoop@master ~]$ cd livy-0.5.0/conf/
[hadoop@master conf]$ vi livy.conf
livy.server.host = 169.254.1.100
livy.server.port = 8998
livy.spark.master = yarn
#livy.spark.deploy-mode = client
livy.spark.deployMode = cluster
livy.repl.enable-hive-context = true
附yarn-cluster和yarn-client模式的区别链接:https://blog.csdn.net/zxr717110454/article/details/80636569
启动livy:
[hadoop@master ~]$ livy-server start # start启动 stop停止 status状态
Elasticsearch配置
启动es(可能有点慢)
[hadoop@master ~]$ ./elasticsearch-6.6.1/bin/elasticsearch
[hadoop@slave01 ~]$ ./elasticsearch-6.6.1/bin/elasticsearch
[hadoop@slave02 ~]$ ./elasticsearch-6.6.1/bin/elasticsearch
在ES里创建griffin索引
[hadoop@master ~]$ curl -H “Content-Type: application/json” -XPUT http://master:9200/griffin -d ’
{
“aliases”: {},
“mappings”: {
“accuracy”: {
“properties”: {
“name”: {
“fields”: {
“keyword”: {
“ignore_above”: 256,
“type”: “keyword”
}
},
“type”: “text”
},
“tmst”: {
“type”: “date”
}
}
}
},
“settings”: {
“index”: {
“number_of_replicas”: “2”,
“number_of_shards”: “5”
}
}
}
’
正确显示结果是:
{“acknowledged”:true,“shards_acknowledged”:true,“index”:“griffin”}
如果不加参数 -H “Content-Type: application/json”,则显示错误结果是:
{“error”:“Content-Type header [application/x-www-form-urlencoded] is not supported”,“status”:406}
griffin配置文件修改
griffin目录下包括griffin-doc、measure、service和ui四个模块,其中griffin-doc负责存放Griffin的文档,measure负责与spark交互,执行统计任务,service使用spring boot作为服务实现,负责给ui模块提供交互所需的restful api,保存统计任务,展示统计结果。
源码导入构建完毕后,需要修改配置文件。
进入配置文件所在目录
[hadoop@master resources]$ cd /home/hadoop/griffin-0.4.0/service/src/main/resources
由于参数较多,对于要修改的参数,我会加粗显示,自行修改。
application.properties配置
[hadoop@master resources]$ vi application.properties
#Apache Griffin应用名称
spring.application.name=griffin_service
#MySQL数据库配置信息
spring.datasource.url=jdbc:mysql://169.254.1.100:3306quartz?useSSL=false
spring.datasource.username=griffin
spring.datasource.password=123
spring.jpa.generate-ddl=true
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.show-sql=true
#Hive metastore配置信息
hive.metastore.uris=thrift://master:9083
hive.metastore.dbname=default
hive.hmshandler.retry.attempts=15
hive.hmshandler.retry.interval=2000ms
#Hive cache time
cache.evict.hive.fixedRate.in.milliseconds=900000
#Kafka schema registry,按需配置
kafka.schema.registry.url=http://master:8081
#Update job instance state at regular intervals
jobInstance.fixedDelay.in.milliseconds=60000
#Expired time of job instance which is 7 days that is 604800000 milliseconds.Time unit only supports milliseconds
jobInstance.expired.milliseconds=604800000
#schedule predicate job every 5 minutes and repeat 12 times at most
#interval time unit s:second m:minute h:hour d:day,only support these four units
predicate.job.interval=5m
predicate.job.repeat.count=12
#external properties directory location
external.config.location=
#external BATCH or STREAMING env
external.env.location=
#login strategy (“default” or “ldap”)
login.strategy=default
#ldap,登录策略为ldap时配置
ldap.url=ldap://hostname:port
[email protected]
ldap.searchBase=DC=org,DC=example
ldap.searchPattern=(sAMAccountName={0})
#hdfs default name
fs.defaultFS=
#elasticsearch配置
elasticsearch.host=master
elasticsearch.port=9200
elasticsearch.scheme=http
#elasticsearch.user = user
#elasticsearch.password = password
#livy配置
livy.uri=http://master:8998/batches
#yarn url配置
yarn.uri=http://master:8088
#griffin event listener
internal.event.listeners=GriffinJobEventHook
quartz.properties配置
[hadoop@master resources]$ vi quartz.properties
org.quartz.scheduler.instanceName=spring-boot-quartz
org.quartz.scheduler.instanceId=AUTO
org.quartz.threadPool.threadCount=5
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
#If you use postgresql as your database,set this property value to org.quartz.impl.jdbcjobstore.PostgreSQLDelegate
#If you use mysql as your database,set this property value to org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#If you use h2 as your database, it’s ok to set this property value to StdJDBCDelegate, PostgreSQLDelegate or others
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.useProperties=true
org.quartz.jobStore.misfireThreshold=60000
org.quartz.jobStore.tablePrefix=QRTZ_
org.quartz.jobStore.isClustered=true
org.quartz.jobStore.clusterCheckinInterval=20000
sparkProperties.json配置
[hadoop@master resources]$ vi sparkProperties.json
{
“file”: “hdfs:///griffin/griffin-measure.jar”,
“className”: “org.apache.griffin.measure.Application”,
“name”: “griffin”,
“queue”: “default”,
“numExecutors”: 2,
“executorCores”: 1,
“driverMemory”: “1g”,
“executorMemory”: “1g”,
“conf”: {
“spark.yarn.dist.files”: “hdfs:///home/spark_conf/hive-site.xml”
},
“files”: [
]
}
默认不用修改,
hdfs:///griffin/griffin-measure.jar:measure jar包上传的位置
hdfs:///home/spark_conf/hive-site.xml:上面hive配置文件上传的位置
env_batch.json配置
[hadoop@master resources]$ vi env/env_batch.json
{
“spark”: {
“log.level”: “WARN”
},
“sinks”: [
{
“type”: “CONSOLE”,
“config”: {
“max.log.lines”: 10
}
},
{
“type”: “HDFS”,
“config”: {
“path”: “hdfs:///griffin/persist”,
“max.persist.lines”: 10000,
“max.lines.per.file”: 10000
}
},
{
“type”: “ELASTICSEARCH”,
“config”: {
“method”: “post”,
“api”: “http://master:9200/griffin/accuracy”,
“connection.timeout”: “1m”,
“retry”: 10
}
}
],
“griffin.checkpoint”: []
}
service/pom.xml文件配置(特别重要)
编辑 service/pom.xml 文件第113行,移除 MySQL JDBC 依赖注释:
否则启动griffin会报错:
nested exception is java.lang.Illeg
alStateException: Cannot load driver class: com.mysql.jdbc.Driver
使用maven命令进行编译打包
[hadoop@master ~]$ cd griffin-0.4.0/
[hadoop@master griffin-0.4.0]$ mvn -Dmaven.test.skip=true clean install
命令执行完成后,会在service和measure模块的target目录下分别看到service-0.4.0.jar和measure-0.4.0.jar两个jar
拷贝jar包
measure-0.4.0.jar改名,和sparkProperties.json中的名字一样
[hadoop@master ~]$ cd griffin-0.4.0/measure/target/
[hadoop@master target]$ mv measure-0.4.0.jar griffin-measure.jar
创建HDFS的/griffin目录
[hadoop@master target]$ hadoop fs -mkdir /griffin/
将改名后的griffin-measure.jar上传到HDFS的/griffin文件目录里
[hadoop@master target]$ hadoop fs -put griffin-measure.jar /griffin/
将service-0.4.0.jar拷贝到主目录
[hadoop@master ~]$ cp /home/hadoop/griffin-0.4.0/service/target/service-0.4.0.jar .
更改spark master web ui的默认端口
因为griffin的sprint root默认启动端口是8080,与spark的默认端口冲突,所以可以更改spark的端口避免冲突。
[hadoop@master ~]$ cd spark-2.4.0/sbin/
[hadoop@master sbin]$ vi start-master.sh
定位到61行
if [ “$SPARK_MASTER_WEBUI_PORT” = “” ]; then
SPARK_MASTER_WEBUI_PORT=8087
fi
修改成其他的端口号即可
启动hive源数据服务
[hadoop@master ~]$ cd hive-3.1.1/
[hadoop@master hive-3.1.1]$ bin/hive --service metastore &
否则在创建Measure时会找不到hive数据库,报错为:
Caused by: MetaException(message:Could not connect to meta store using any of the URIs provided. Most recent failure: org.apache.thrift.transport.TTransportException: java.net.ConnectException: 拒绝连接 (Connection refused)
启动griffin
运行service-0.4.0.jar,启动Griffin管理后台
[hadoop@master ~]$ nohup java -jar service-0.4.0.jar>service.out 2>&1 &
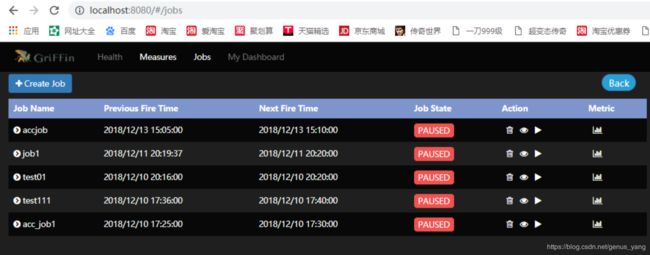
启动成功验证
访问UI界面 169.254.1.100:8080,出现下图表示安装成功!