实体关系发现框架Limes
1. 软件安装
1.1 获取Limes
git clone https://github.com/dice-group/LIMES1.2 编译源码
进入 limes-core 目录编译:
cd limes-core
mvn clean install
创建可运行Jar文件:
mvn clean package shade:shade -Dcheckstyle.skip=true -Dmaven.test.skip=trueJar文件目录:limes-core/target/limes-core-VERSION-SNAPSHOT.jar
1.3 运行Jar文件
cd target
java -jar limes-core-1.0.0-SNAPSHOT.jar config.xmlconfig.xml是自定义的配置文件。
2. 数据准备
Limes输入文件格式包括SPARQL端点,以及CSV, NT, TURTLE等格式的本地文件。 所有信息都需要用三元组的形式记录,NT格 式文件如下:
"民族"@zh .
"戏居"@zh .
"电影"@zh .
3. 配置文件
使用Limes进行实体关系融合的关键步骤是写好配置文件,包括数据源,融合算法,融合条件等信息。
3.1 Prefixes
将命令空间Namespace缩写为前缀标签Prefix Label,便于后文书写。例如:
http://www.w3.org/1999/02/22-rdf-syntax-ns#
可根据需要配置多个Prefixes。
3.2 数据源 Data Sources
Data Sources包括Source 和 Target, 配置格式都一样。
mesh
http://mesh.bio2rdf.org/sparql
?y
5000
?y rdf:type meshr:Concept
dc:title
sparql
- ID: 自定义数据源名称。
- ENDPOINT: 数据源地址,可以是SPARQL端点,也可以是本地文件(需要绝对路径)。
- VAR: 参与实体相似度计算的变量,这个变量在Metric表达式中会使用。 PAGESIZE: SPARQL端点每次查询返回的最大Triple数量,本地文件设置为-1。 RESTRICTION: 参与实体相似度计算的Triple限制条件。
- 可对数据进行预处理,例如: lowercase(rdfs:label) ,表示将 rdfs:label 的宾语全部改为小写字母。
3.3 度量表达式 Metric Expression
trigram(x.label, y.title) | 0.8
- 使用Data Sources中配置的变量进行计算。
- 多个Mertic Expression可以使用MIN, MAX, ADD操作符结合使用,例如:
MAX(trigrams(x.rdfs:label,y.dc:title)|0.3,euclidean(x.lat|long, y.latitude|longitude)|0.5).- MAX的第一个子表达式:x的rdfs:label与y的dc:title之间的Trigram相似度大于或等于0.3。
- MAX的第二个子表达式:x中的点(x.lat, x.long)与y中的点(y.latitude, y.longitude)之间的欧几里得距离大于或等于0.5。
- MAX操作符取两个子表达式中的最大值最为相似度。
- 目前所有操作符只支持两个Expression结合,但可以嵌套使用。
- 还可以使用Bool表达式AND, OR, DIFF对计算结果进行过滤, 例如:
AND(trigrams(x.rdfs:label,y.dc:title)|0.9, euclidean(x.lat|x.long, y.latitude|y.longitude)|0.7)该表达式将返回两个子表达式融合结果的并集。
- METRIC 支持的原子表达式有:Cosine、ExactMatch、Jaccard、Jaro、JaroWinkler、Levenshtein、MongeElkan、Overlap、Qgrams、RatcliffObershelp、Soundex、Trigram,更多信息可参考链接。
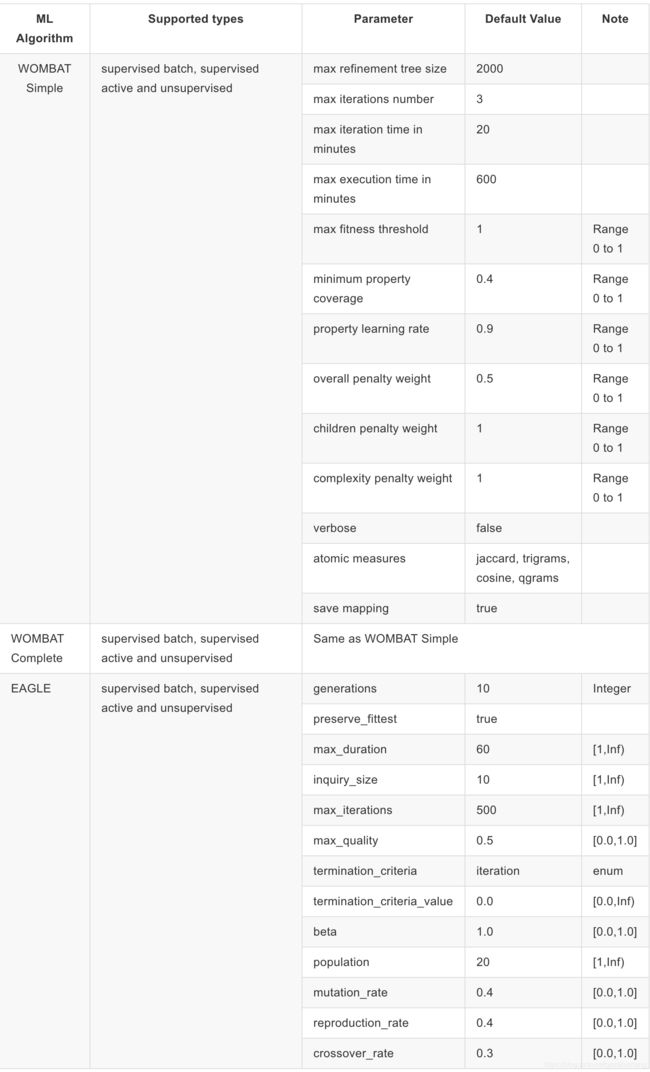
3.4 机器学习
融合计算可以选择Metric Expression指定相似性度量表达式,也可以选择机器学习自动计算。故
wombat simple
supervised batch
trainingData.nt
max execution time in minutes
60
NAME: 算法名, 支持womabt simple,wombat complete,eagle。
TYPE: 训练方式,支持supervised batch,supervised active,unsupervised。
TRAINING: 训练集文件地址,该文件只能包括以
PARAMETER:训练参数配置,可参考下表:
3.5 接受条件 Acceptance Condition
0.98
accepted.nt
owl:sameAs
- THRESHOLD: 萄值。
- FILE: 输出文件路径,只支持nt格式。
- RELATION: 实体关系名称。
3.6 复审条件 Review Condition
与Acceptance Condition类似,一般萄值比前者小,某些不满足Acceptance Condition的实体对,可根据Review Condition输出到另一 个文件进行复审。
0.95
review.nt
owl:sameAs
3.7 配置文件样例 可按照下面的完整例子进行配置
http://www.w3.org/2002/07/owl#
http://geovocab.org/geometry#
http://www.opengis.net/ont/geosparql#
http://linkedgeodata.org/ontology/
linkedgeodata
http://linkedgeodata.org/sparql
?x
2000
?x a lgdo:RelayBox
geom:geometry/geos:asWKT RENAME polygon
linkedgeodata
http://linkedgeodata.org/sparql
?y
2000
?y a lgdo:RelayBox
geom:geometry/geos:asWKT RENAME polygon
geo_hausdorff(x.polygon, y.polygon)
0.9
lgd_relaybox_verynear.nt
owl:sameAs
0.5
lgd_relaybox_near.nt
owl:sameAs
default
default
default
其中EXECUTION和OUTPUT按默认配置4. Metric使用实例
4.1 余弦(Cosine)相似度比较
4.1.1 数据
Source和Target数据集格式都为nt,均为百科数据的Label信息。 Source数据例子:
Target数据例子:
"历史"@zh . Source和Target文件均上传至OpenKG.CN:链接
| 文件名 | 实体数 | 三元组数量 | |
| Source | cndbpediaDump_26.nt | 358986 | 927503 |
| Target | zhwiki_labels_zh.nt | 575770 | 575770 |
4.1.2 配置文件
http://www.w3.org/2002/07/owl#
http://zhishi.me/ontology/
http://cndbpedia/resource/
http://cndbpedia/ontology/
http://www.w3.org/2000/01/rdf-schema#
cndbpedia
cndbpediaDump_26.nt
?x
-1
?x cndbo:实体名称 ?z1
cndbo:实体名称 RENAME label
NT
zhwiki
zhwiki_labels_zh.nt
?y
-1
?y rdfs:label ?z2
rdfs:label AS nolang
NT
Cosine(x.label, y.rdfs:label) | 0.8
0.9
accept_result.nt
owl:sameAs
0.5
review_result.nt
owl:sameAs
default
default
default
4.1.3 输出文件样例
1.0
1.0
1.0 每一列的数字为度量表达式的计算结果,即相似度。
| Acceptance | Review | |
| 融合结果数 | 9517 | 420041 |
执行时间:63s 选取Review的10条结果如下:
0.6
0.6324555320336759
0.5163977794943222
0.7071067811865475
0.7071067811865475
0.5
0.5
0.5
0.5 可以看到cosine的review匹配效果是比较粗糙的。
4.2 完全匹配(ExactMatch)相似度比较
4.2.1 数据集和配置文件 数据集与上一节相同,配置文件更改METRIC为:
ExactMatch(x.label, y.rdfs:label) | 1.0
4.2.2 结果
| Acceptance | Review | |
| 融合结果数 | 9507 | 0 |
执行时间:60s
4.3 Cosine 与 ExactMatch比较
ExactMatch是非常严格的相似度比较算法,Review数量为0,准确度Precision很高,但是 召回率Recall就会很低。Cosine贝比较均 衡,准确度和ExactMatch相似,Review数目很大。
选取Cosine Accept比ExactMatch多的10条结果展示:
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0 5. MLALgorithm使用实例
5.1 领域数据集之间的匹配
5.1.1 数据准备
数据采用分别从PKUPie和Belief-Engine提取的电影领域的数据集。
| 数据集 | 实体数 | 三元组数 |
| pku-movie | 15529 | 33467 |
| belief-movie | 4695 | 35632 |
其中,belief-movie的4695个实体在pku-movie都有对应的等价实体。 数据下载链接
5.1.2 配置文件
http://www.w3.org/2002/07/owl#
http://www.w3.org/2000/01/rdf-schema#
http://pkubase/ontology/
http://www.belief-engine.org/baike_hudong/resource/
belief
interest_triple_actor_final_belief_label.nt
?x
-1
?x beliefr:label ?z1
beliefr:label RENAME label
NT
pku
interest_triple_actor_final_pku_label.nt
?y
-1
?y pkuo:label ?z2
pkuo:label RENAME label
NT
wombat simple
supervised batch
ml_train_data.nt
max execution time in minutes
60
0.9
accept_result.nt
owl:sameAs
0.5
review_result.nt
owl:sameAs
default
default
default
其中MLALgorithm算法采用wombat simple,训练样本文件格式如下:
保存为.nt文件,并且relation必须是
5.1.3 结果 融合结果如下:
| 训练集三元组 | Acceptance | Review |
| 500 | 4695 | 0 |
执行时间:10s
可以得出,采用机器学习算法匹配的结果准确率很高,但是Review为0,wombat simple 不太适合模糊匹配。
5.2 领域与百科数据集之间的匹配
5.2.1 数据准备
数据集分别采用pku-movie和zhishi.me的中文百科数据集(只包含label信息)
| 数据集 | 实体数 | 三元组数 |
| pku-movie | 15529 | 33467 |
| zhishime_wiki_zh | 559402 | 559402 |
数据下载链接
5.2.2 配置文件 与上一小结的文件类似,不再赘述。
5.2.3 结果 融合结果与ExactMactch(字符串完全匹配)方法做了对比:
| 训练集三元组 | Acceptance | Review | ExactMatch |
| 500 | 3834 | 0 | 3829 |
执行时间:94s
可以看到Machine Learning的结果跟ExactMatch非常类似,说明wombat simple的准确率是非常高的。 提取出Machine Learning比ExactMatch多匹配到的实体对名称:
| zhishi.me | pku-movie |
| .网络 | 网络 |
| Hey! Say! JUMP | Hey!Say!JUMP |
| S.H.E. | S.H.E |
| 巴不得爸爸... | 巴不得爸爸 |
| Sound.Horizon | Sound Horizon |
可以看到,单纯使用ExactMatch是无法提取出这些实体对的,但是Machine Learning找到了,并且经过人工判断,也是正确的。