Python语言工程实践期中作业
用python分析《三国演义》
完成日期:2019.05.18
文章目录
- 用python分析《三国演义》
- 1. 摘要
- 2. 算法分析
- 1) 出场人物频率分析
- 2) 词频分析
- 3) 字频分析
- 4) 基于共现关系的人物关系分析
- 5) 命名实体识别以及实体关系抽取
- 3.详例描述
- 1. 出场人物频率分析
- 2. 词频分析
- 3. 字频分析
- 4. 基于共现关系的人物关系分析
- 5. 命名实体识别以及实体关系抽取
- 4.软件演示
- 1. 出场人物频率分析
- 2. 词频分析
- 3. 字频分析
- 4. 基于共现关系的人物关系分析
- 5. 命名实体识别以及实体关系抽取
- 5.总结和体会
- 6.具体代码
1. 摘要
本次作业利用python相关技术对《三国演义》进行断句、分词、词性标注、命名实体识别等,通过制定相关规则或词频统计等方式初步找出有意义的模式,并通过数据、图表等加以分析和阐述。
本小组对《三国演义》的文本主要做了五方面的分析,分别是对主要人物的出场次序进行统计和排序,高频字的统计和排序,高频词的统计和排序,基于共现的人物关系分析以及命名实体识别和实体关系抽取。
2. 算法分析
1) 出场人物频率分析
a) 构建一个非人名集合,用于下面统计词频时排除不是人名的单词;
b) 对《三国演义》文本利用jieba包进行分词;
c) 定义一个字典去存储分词结果和出现的次数;
d) 在统计词频时,由于长度为1的单词大概率不是人名,因此忽略长度为1的词;
e) 同时,某些人物会具有多个名字,因此对这些人物的不同名字需要分开判断;
f) 把字典中一些不是人名的词语排除掉;
g) 根据字典的键值进行排序;
h) 最后格式化输出结果并通过matplotlib将结果可视化。
2) 词频分析
a) 打开《三国演义》文本并读取文本内容;
b) 使用jieba分词对文本进行分词;
c) 定义一个字典去存储分词结果和出现的次数;
d) 由于会进行字频分析,本实验将忽略长度为1的词;
e) 根据字典的键值进行排序;
f) 将结果进行格式化输出并通过matplotlib将结果进行格式化;
g) 最后再通过WorldCloud进行词云制作。
3) 字频分析
a) 打开《三国演义》文本并读取文本内容;
b) 构建一个标点符号集合,用于下面统计字频时忽略标点符号;
c) 定义一个字典去存储每个字符和出现的次数;
d) 遍历文本中的每一个字符并进行出现次数的统计;
e) 根据字典的键值进行排序;
f) 将结果进行格式化输出并通过matplotlib将结果进行格式化。
4) 基于共现关系的人物关系分析
a) 从网上获取《三国演义》的人物表;
b) 定义一个字典a保存人物,key为人物名称,valve为该人物在全文中出现的次数;
c) 定义另一个字典b来保存人物关系的有向边,key为有向边的起点,valve为一个字典edge,edge的key为有向边的终点,valve为有向边的权重;
d) 打开人物表文本和《三国演义》内容文本并读取文本内容;
e) 使用jieba对文本进行分词并返回词性;
f) 对每一段在b中增加一个人物列表,当分词长度小于2或者该词的词性不为nr(人名)时认为该词不为人名;
g) 对人物列表中的人物出现次数进行统计;
h) 之后再对a中的每一项,为该项中出现的所有人物两两相连,如果两个人物之间尚未有边建立,则将新建的边权值设为1,否则将已存在的边的权值加1;
i) 由于分词的不准确会出现很多不是人名的“人名”,从而导致出现很多冗余边,为此可设置阈值为100,即当该边出现100次以上则认为不是冗余。
j) 之后再通过人物表来筛选人物节点表中非人名的词;
k) 最后再Gephi软件来输出人物关系表。
5) 命名实体识别以及实体关系抽取
a) 打开《三国演义》文本并读取文本内容;
b) 利用LTP中的分词、词性标注、命名实体识别以及依存句法分析等等对文本进行处理;
c) 本实验结合中文语法的关系表述,总结出了几种表述关系;
d) 在进行依存句法分析后的文本,我们根据总结出的几种表述关系,抽取以谓词为中心的事实三元组以及抽取命名实体有关的三元组
3.详例描述
1. 出场人物频率分析
a) 打开文件并读取文本内容;
b) 使用jieba分词对文本进行分词
c) 构建非人名集合,用于下面统计词频时排除不是人名的单词:

d) 忽略长度为1的单词,同时对具有多个名字的人物进行另外的处理:
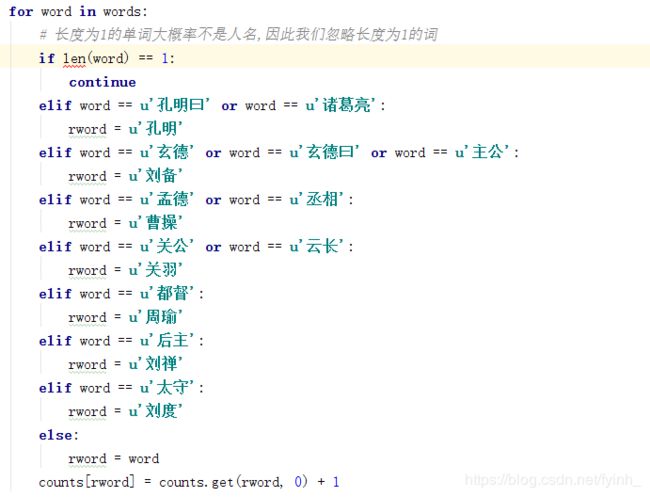
e) 此时可以看到以下统计的结果,有很多非人名的词语都统计进去了:
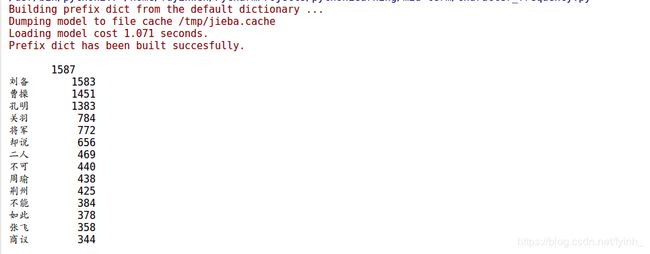
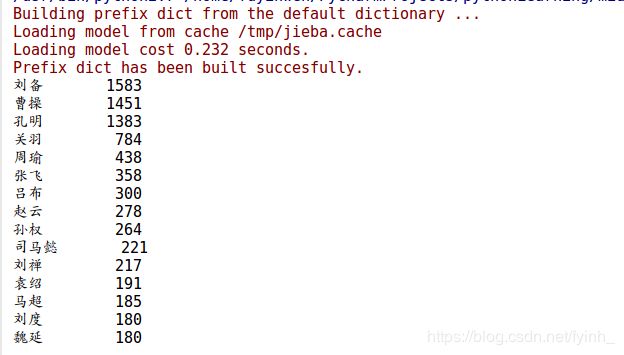
f) 因此要把不是人名的词语排除掉,可以得到以下出场人物出场频次的结果:
2. 词频分析
a) 打开文件并读取文本内容;
b) 使用jieba分词对文本进行分词;
c) 忽略长度为1的单词:

d) 可以看到统计结果为:
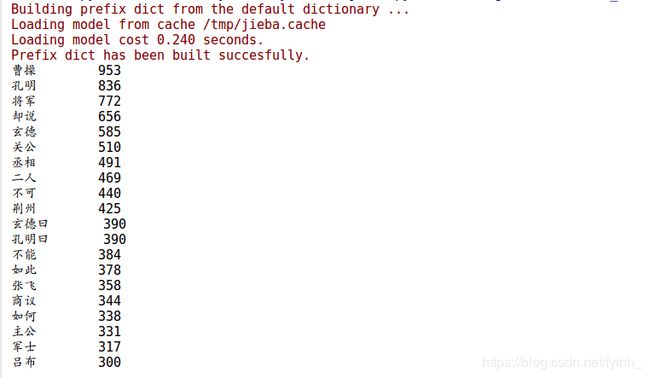
e) 之后对切分结果进行词云制作:
可以看到, 词云的宽度为800,长度为600,最大词数为100,字的最大的尺寸为80。
3. 字频分析
a) 打开文件并读取文本内容;
b) 使用jieba分词对文本进行分词;
c) 构建的标点符号集合,用于下面统计字频时忽略标点符号:

d) 此时可以看到以下统计的结果,有很多标点符号都统计进去了:

e) 因此要把标点符号排除掉,可以得到以下字频结果:

4. 基于共现关系的人物关系分析
a) 从网上获取的《三国演义》人物表(示例):
b) 对人物列表中的人物出现的次数进行统计,得到以下结果(示例):

c) 然后在对人物之间的边进行统计,得到以下结果(示例):

e) 再利用Gephi软件来输出人物关系图。
5. 命名实体识别以及实体关系抽取
a) 对文本进行分词、词性标注、命名实体识别以及依存句法分析等等处理之后可以得到以下的结果:

b) 总结出的表述关系:
(1) 动词。例如:“小明出生广东”,很容易看出“出生”作为谓语动词;
(2) 动词 + 补语。例如:“小明做完了作业”,可以看出后补短语“做完了”作为谓语动词;
(3) 状语 + 动词。例如:“小明非常喜欢做作业”,由于“喜欢”是修饰“做”的,可以看出偏正短语“非常喜欢”作为谓语动词;
(4) 动词 + 介词。例如:“小明就读于广东外语外贸大学”,如果直接将这个三元组抽取为(小明,就读,广东外语外贸大学),明显是不正确的,“于”和“广东外语外贸大学“是介宾关系,因此谓语动词就应该为“就读于”;
(5) 宾语前置句型,需自行判断。例如“海洋由水组成”,“海洋”是“组成”的前置宾语,由“是”组成的状语,“水”和“由”是介宾关系,所以该句子没有明确的主谓关系,需要我们自己去判断,该句的谓语动词为“组成”。
根据总结可以看出,动词谓语句的常见形式,动词出现在状语的后面以及出现在补语的前面,也可能是这几个成分同时出现,也就是说,谓语动词依赖于它前后的成分,因此关系表述公式为:状语 * 动词 + 补语 ?,其中,*表现出现0次或者任意多次,+表示出现1次或者任意多次,?表示出现0次或者1次。
c) 抽取的以谓词为中心的事实三元组以及抽取命名实体有关的三元组(示例):

4.软件演示
1. 出场人物频率分析
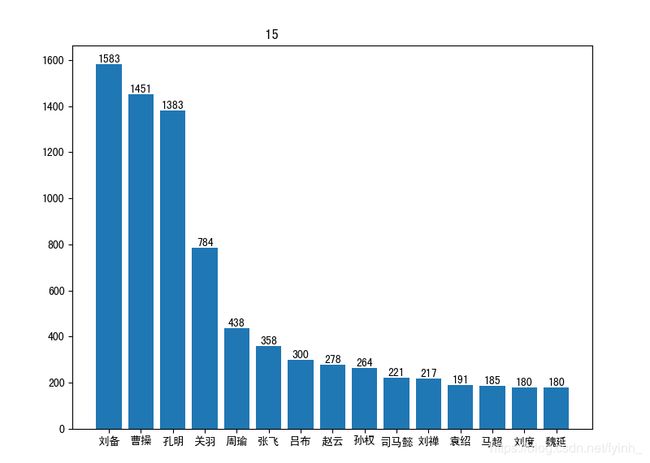
出场人物频率直方图:
出场人物频率饼图:
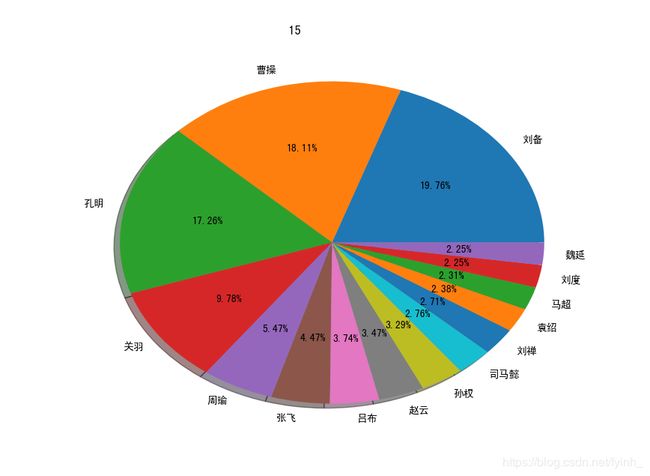
以上是选取前15个出场频数最高的人物进行分析。可以看到,《三国演义》中主要的三大男主角分别为刘备、曹操和孔明,他们拥有极其复杂的人物关系,于整套书中出场次数最多。重要配角有很多,如关羽、周瑜、张飞、吕布、赵云、孙权、司马懿等人物,他们出场次数也相当多,配合三大男主角推进故事发展,为小说增添故事性和艺术性。而广为人知的三国有“三绝”:智绝——孔明、义绝——关羽、奸绝——曹操,均属于人物出场频数排行前四名,这也在一定程度上说明了读者对小说人物的评价与人物在小说情节中的出场次数以及活跃度有一定的关联性。同时也能看出,《三国演义》主要讲述了男人之间的故事。
2. 词频分析
词频直方图:
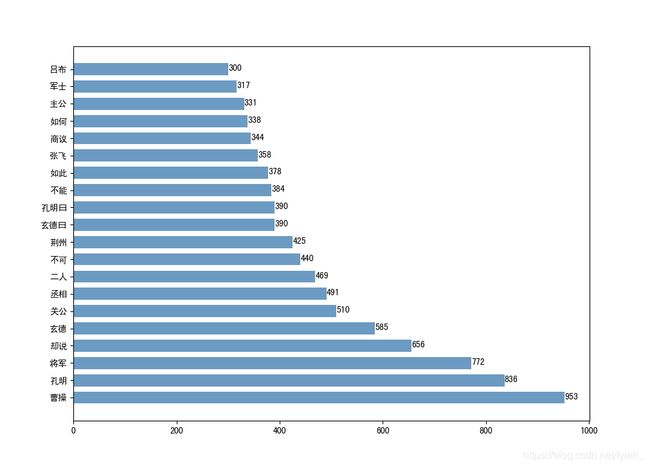
词云图:

可以看到,词频统计中频数比较高的词当中包含了不少人名,而这些人名中频数最高的有曹操、孔明、玄德,这说明了《三国演义》的故事情节围绕着曹操、刘备、孔明三人展开。其中频数较高的非人名词有“将军”、“丞相”、“荆州”、“主公”、“军士”等,这说明了《三国演义》是一部关于古代领土争夺的军事历史题材类的小说。
3. 字频分析
字频直方图:
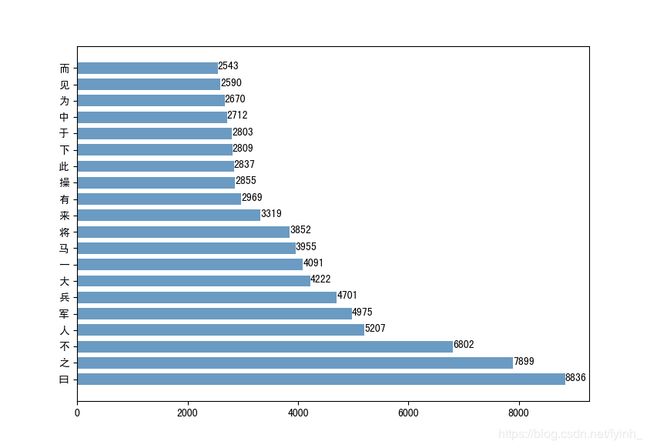
可以看到,字频最高的字为“曰”,说明小说中的对话情节较多,通过人物间的对话交流推动故事情节的发展是这部小说的一大写作艺术手法。除去一些常见的无意义停用字如“之”、“而”、“为”、“于”等,字频较高有意义的字还有“人”、“军”、“兵”、“马”等,这再一次说明了《三国演义》是一部属于军事历史题材的小说。
4. 基于共现关系的人物关系分析
人物关系如下表和图:
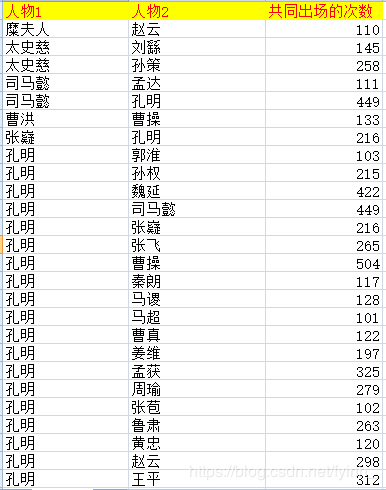

网络中的节点代表三国人物,边的粗细正比于两个人物共同出场的段落数。某节点的度即网络上与该节点相连接的节点数量,因此,某人物的度就是和他一起出场过的人物数。为了可视化方便,上图仅展示了《三国演义》全文人物关系网络中度大于100的人物及其相互关系。
可以看到,该网络人物关系错综复杂。其他的重要主角如孔明以及许多重要的配角如张飞、黄忠、马超、吕布和赵云等都与曹操这一主角有着相当强的人物关系。
经典故事和相关人物:青梅煮酒论英雄(曹操、刘备),白帝城托孤(刘备、诸葛亮),鞭打督邮(刘备、张飞),火烧新野(赵云、诸葛亮),千里走单骑(关羽、刘备),赤壁之战(曹操、诸葛亮)等。
5. 命名实体识别以及实体关系抽取
实体关系抽取的内容(示例):
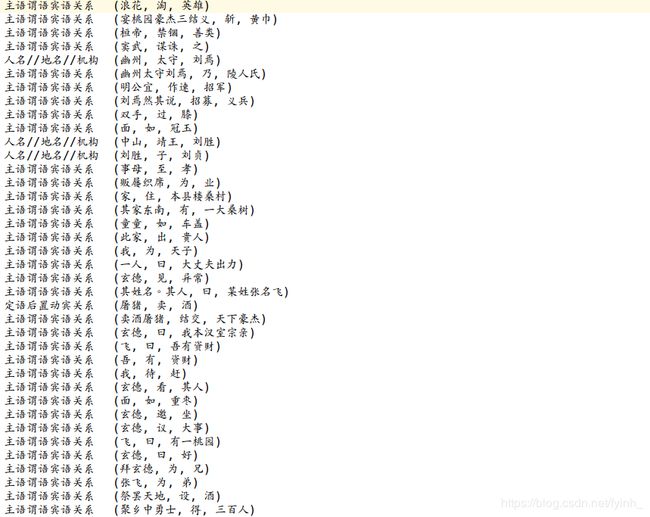
可以看到本实验抽取的实体关系主要有主语谓语宾语关系、定语后置动宾关系、介宾关系主谓动补以及人名//地名//机构,由于《三国演义》是半文言文形式,所以抽取的效果并不是很好,后续会继续完善该代码。
5.总结和体会
在做这个作业的过程中,我们小组一直在想对小说可以有什么样的分析,由于学习了分词、词性标注以及命名实体识别等等,同时对《三国演义》的分析主要就是对人物和事件进行分析,因为对事件的分析没想到有什么特别好的思路,因此就选择了着重对人物进行分析,因此就做了出场人物的频率分析以及人物关系的分析。除此之后,我们还对文本进行了一些常规的分析比如说词和字频的分析等等,然后为了挖掘文本中的一些浅层的语法信息,因此我们进行了实体关系的抽取,以求能得到中文的一些语法的模式。在做这个作业的过程中,我们主要遇到了以下几个问题:
(1) 中文编码的问题
不得不说,中文的编码确实是一个很大的问题,因为作业大部分都是在Ubuntu完成的,因此很多编码都要求是utf8编码,因此一开始遇到了多处无法编码的情况,后来我们探索到了一个很好用的方法,可以解决大多数的编码问题,就是在代码文件头加上:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
之后,基本的编码问题都能解决了。
(2) Gephi画图问题
可能是第一次操作这个画图软件,所以对很多的操作都不太熟悉,然后弄了一早上都没办法把图画出来,有节点无法导入、中文无法显示等等问题,后来查了很多博客才发现,基本都是编码问题,只要把编码都改成utf8就没有问题了。
(3) 实体关系抽取效果不好
因为文本中有很多半文言文的表达,实体关系抽取是基于规则的方法来做的,所以在抽取的关系中有很多乱七八糟的东西,同时在命名实体识别中有很多名字都会把“曰”识别进去,例如“孔明”是一个实体,可是会识别“孔明曰”等等,其实在关于人物的分析中这个问题都会出现,我们小组想到的方法就是将文本中的“曰”全部换成“说”字或者直接删除“曰”,这样识别出来的效果会比较好,后续我们会继续研究怎么解决这些文言文中的表达,使得分词和命名实体识别的效果更好。
6.具体代码
这次作业包含了五部分代码,因为代码量较大,为了报告的简洁就不做一一复制。
具体请看Github:https://github.com/fyinh/Python_NLP_Mid-term_Homework/tree/master/code