(十)循环神经网络RNN
1、介绍
给定时间步 t t 的小批量输入 Xt∈Rn×x X t ∈ R n × x (样本数为n,输入个数为x),设该时间步隐藏状态为 Ht∈Rn×h H t ∈ R n × h (隐藏单元个数为 h h ),输出层变量为 Ot∈Rn×y O t ∈ R n × y (输出个数为y),隐藏层的激活函数为ϕ。循环神经网络的矢量计算表达式为
其中隐藏层的权重 Wxh∈Rx×h,Whh∈Rh×h W x h ∈ R x × h , W h h ∈ R h × h 和偏差 bh∈R1×h b h ∈ R 1 × h ,以及输出层的权重 Why∈Rh×y W h y ∈ R h × y 和偏差 by∈R1×y b y ∈ R 1 × y 为循环神经网络的模型参数。输入个数 x x 为任意词的特征向量长度,输出个数 y y 为语料库中所有可能的词的个数;对循环神经网络的输出做softmax运算,我们可以得到时间步t输出所有可能的词的概率分布 Y^t∈Rn×y: Y ^ t ∈ R n × y :
2、图示(字符级循环神经网络)
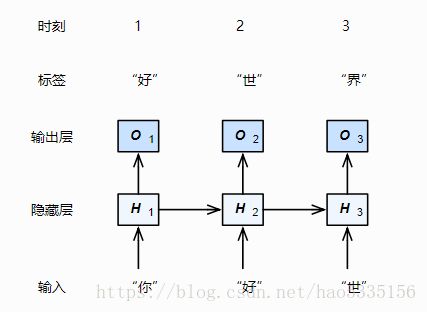
这里的时间步 t t 为3,输入个数 x x 为”你”或者”好”或者”世”的one-hot词向量表示,即 x=[0001000] x = [ 0001000 ] 之类
3、时序数据的采样:
我们需要每次随机读取小批量样本和标签。不同的是,时序数据的一个样本通常包含连续的字符。假设时间步数为5,样本序列为5个字符:“想”、“要”、“有”、“直”、“升”。那么该样本的标签序列为这些字符分别在训练集中的下一个字符:“要”、“有”、“直”、“升”、“机”。
以时间t=3,批量大小为2说明如下:
(1)随机采样
在随机采样中,每个样本是原始序列上任意截取的一段序列。相邻的两个随机小批量在原始序列上的位置不一定相毗邻。因此,我们无法用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态。在训练模型时,每次随机采样前都需要重新初始化隐藏状态。

(2)相邻采样
用一个小批量最终时间步的隐藏状态来初始化下一个小批量的隐藏状态,从而使下一个小批量的输出也取决于当前小批量输入,并如此循环下去。这对实现循环神经网络造成了两方面影响。一方面, 在训练模型时,我们只需在每一个迭代周期开始时初始化隐藏状态。 另一方面,当多个相邻小批量通过传递隐藏状态串联起来时,模型参数的梯度计算将依赖所有串联起来的小批量序列。同一迭代周期中,随着迭代次数的增加,梯度的计算开销会越来越大。 为了使模型参数的梯度计算只依赖一次迭代读取的小批量序列,我们可以在每次读取小批量前将隐藏状态从计算图分离出来。

4、RNN和参数代码
def get_params():
# 隐藏层参数。
W_xh = nd.random.normal(scale=0.01, shape=(num_inputs, num_hiddens),
ctx=ctx)
W_hh = nd.random.normal(scale=0.01, shape=(num_hiddens, num_hiddens),
ctx=ctx)
b_h = nd.zeros(num_hiddens, ctx=ctx)
# 输出层参数。
W_hy = nd.random.normal(scale=0.01, shape=(num_hiddens, num_outputs),
ctx=ctx)
b_y = nd.zeros(num_outputs, ctx=ctx)
params = [W_xh, W_hh, b_h, W_hy, b_y]
for param in params:
param.attach_grad()
return params
def rnn(inputs, state, *params):
H = state
W_xh, W_hh, b_h, W_hy, b_y = params
outputs = []
for X in inputs:
H = nd.tanh(nd.dot(X, W_xh) + nd.dot(H, W_hh) + b_h)
Y = nd.dot(H, W_hy) + b_y
outputs.append(Y)
return outputs, H5、裁剪梯度
循环神经网络中较容易出现梯度衰减或爆炸。为了应对梯度爆炸,我们可以裁剪梯度(clipping gradient)。假设我们把所有模型参数梯度的元素拼接成一个向量 g,并设裁剪的阈值是θ。裁剪后梯度
的L2范数不超过θ。
6、使用困惑度(perplexity)评价模型
困惑度:是对交叉熵损失函数做指数运算后得到的值,即exp(loss),如果loss=0,则exp(loss)=1
最佳情况下,模型总是把标签类别的概率预测为1。此时困惑度为1。
最坏情况下,模型总是把标签类别的概率预测为0。此时困惑度为正无穷。
基线情况下,模型总是预测所有类别的概率都相同。此时困惑度为类别数。