HIVE 窗口及分析函数 应用场景
窗口函数应用场景:
(1)用于分区排序
(2)动态Group By
(3)Top N
(4)累计计算
(5)层次查询
hive中一般取top n时,row_number(),rank,dense_rank()这三个函数就派上用场了,
先简单说下这三函数都是排名的,不过呢还有点细微的区别。
通过代码运行结果一看就明白了。
ROW_NUMBER() OVER函数的基本用法
语法:ROW_NUMBER() OVER(PARTITION BY COLUMNORDER BY COLUMN)
详解:
row_number() OVER (PARTITION BY COL1 ORDERBY COL2)表示根据COL1分组,在分组内部根据COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(该编号在组内是连续并且唯一的)。
场景描述:
在Hive中employee表包括empid、depid、salary三个字段,根据部门分组,显示每个部门的工资等级
SELECT empid、depid、salary, Row_Number() OVER (partition by deptid ORDER BY salary desc) rank FROM employee
参考:https://blog.csdn.net/wiborgite/article/details/80521593
一、分析函数
用于等级、百分点、n分片等。
新增加序号列NTILE, ROW_NUMBER(), RANK(), DENSE_RANK()
| 函数 | 说明 |
| RANK() | 返回数据项在分组中的排名,排名相等会在名次中留下空位 |
| DENSE_RANK() | 返回数据项在分组中的排名,排名相等会在名次中不会留下空位 |
| NTILE() | 返回n分片后的值 |
| ROW_NUMBER() | 为每条记录返回一个数字 |
- Rank、DENSE_RANK
RANK()在出现等级相同的元素时预留为空,DENSE_RANK()不会。
Eg:某产品类型有两个并列第一
RANK():第一二为1,第三位3
DENSE_RANK():第一二为1,第三位2
select *,rank() over (order by deptid desc) as rank, dense_rank() over (order by deptid desc) as dense_rank from employee;
OVER 需要,括号内为编号顺序。
结果如下:
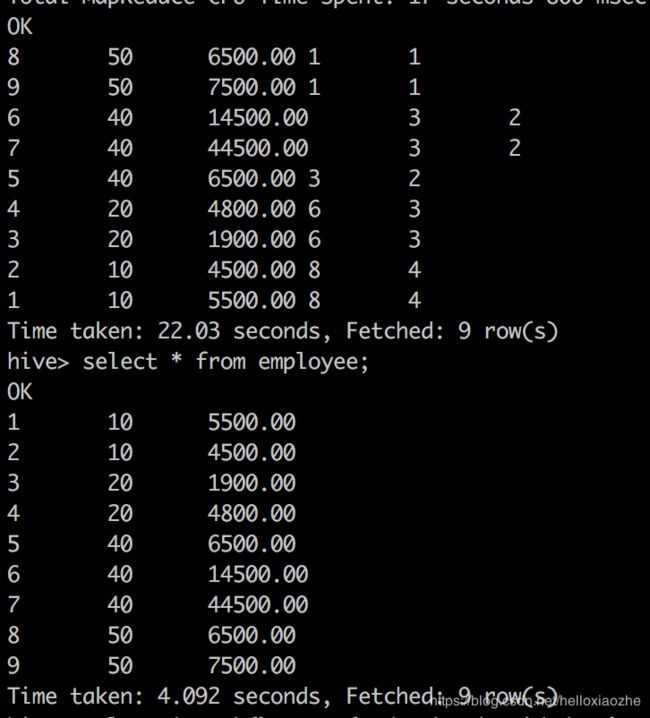
注意:order by 时,desc NULL 值排在首位,ASC时NULL值排在末尾
可以通过NULLS LAST、NULLS FIRST 控制
RANK() OVER (ORDER BY column_name DESC NULLS LAST)
PARTITION BY 分组排列顺序
RANK() OVER(PARTITION BY month ORDER BY column_name DESC)
这样,就会按照month 来分,即所需要排列的信息先以month 的值来分组,在分组中排序,各个分组间不干涉
- NTILE
按层次查询,如一年中,统计出工资前1/4之的部门信息,使用NTILE分析函数,把所有工资分为4份,为1的哪一份就是我们想要的结果:
select deptid,sum(salary),ntile(4) over (order by sum(salary) desc nulls last) til_col from employee group by deptid;
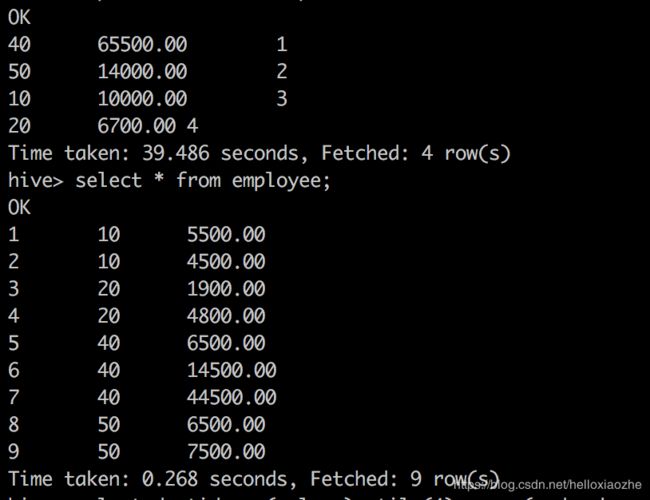
按层次查询,如一年中,统计出工资前1/2之的部门信息,使用NTILE分析函数,把所有工资分为2份,为1的哪一份就是我们想要的结果:
select deptid,sum(salary),ntile(2) over (order by sum(salary) desc nulls last) til_col from employee group by deptid;

- ROW_NUMBER
ROW_NUMBER()从1开始,为每条记录返回一个数字
SELECT ROW_NUMBER() OVER(ORDER BY column_name DESC) AS row_name FROM table_name;
二、窗口函数
可以计算一定范围内、一定值域内、或者一段时间内的累积和以及移动平均值等。
可以结合聚集函数SUM() 、AVG() 等使用。
可以结合FIRST_VALUE() 和LAST_VALUE(),返回窗口的第一个和最后一个值
1)计算累计和
eg:统计1-12月的累积销量,即1月为1月份的值,2月为1.2月份值的和,3月为123月份的和,12月为1-12月份值的和
SELECT
month,SUM(amount) month_amount,
SUM( SUM(amount)) OVER (ORDER BY month ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_amount
FROM table_name
GROUP BY month
ORDER BY month;
其中:
SUM( SUM(amount)) 内部的SUM(amount)为需要累加的值,在上述可以换为 month_amount
ORDER BY month 按月份对查询读取的记录进行排序,就是窗口范围内的排序
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 定义起点和终点,UNBOUNDED PRECEDING 为起点,表明从第一行开始, CURRENT ROW为默认值,就是这一句等价于:
ROWS UNBOUNDED PRECEDING
PRECEDING:在前 N 行的意思。
FOLLOWING:在后 N 行的意思。
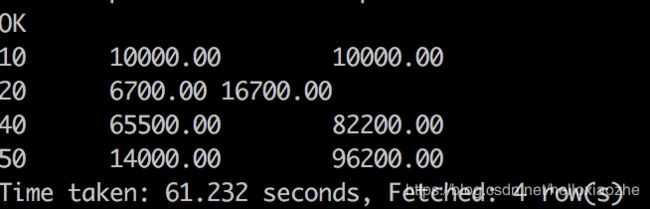
例如,按照部门ID大小排升序,依次统计所有工资部门的累计工资支出。
SELECT deptid,SUM(salary) salary_amount,SUM(SUM(salary)) OVER( ORDER BY deptid ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_amount FROM employee GROUP BY deptid ORDER BY deptid;
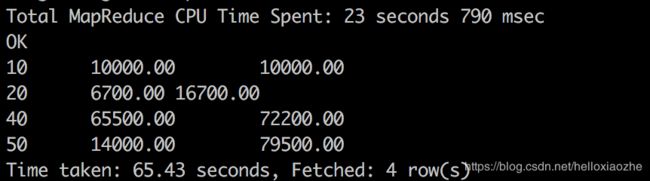
例如,按照部门ID大小排升序,依次统计当前部门和之前1个部门的工资部门的累计工资支出。
SELECT deptid,SUM(salary) salary_amount,SUM(SUM(salary)) OVER( ORDER BY deptid ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS cumulative_amount FROM employee GROUP BY deptid ORDER BY deptid;
计算前3个月之间的和
SUM( SUM(amount)) OVER (ORDER BY month ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS cumulative_amount
也可以
SUM( SUM(amount)) OVER (ORDER BY month 3 PRECENDING) AS cumulative_amount
前后一个月之间的和
SUM( SUM(amount)) OVER (ORDER BY month ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS cumulative_amount
窗体第一条和最后一条的值
FIRST_VALUE(SUM(amount)) OVER (ORDER BY month ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS xxxx;
LAST_VALUE(SUM(amount)) OVER (ORDER BY month ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS xxxx;
SUM(), MIN(),MAX(),AVG()等聚合函数
对一定窗口期内的数据进行聚合
SELECT *,
SUM(a.pv) OVER (PARTITION BY cookieid ORDER BY create_time ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) AS pv1,
SUM(a.pv) OVER (PARTITION BY cookieid ORDER BY create_time ROWS BETWEEN 2 PRECEDING AND 1 FOLLOWING) AS pv2
FROM lxy AS a;
在这里根据cookieid进行分组,然后按照create_time进行分组,选择不同的窗口进行一定函数的聚合运算。
基本的语法是ROWS BETWEEN 一个时间点 AND 一个时间点
时间点分别可以是以当前行作为参考系,前面几行n PRECEDING或者是后面几行n FOLLOWING,也可以是当前行CURRENT ROW。总之可以想象有一个滑动窗口,我们可以规定一个滑动窗口的中心位置和大小,然后每次画过一个步长,计算一次窗口内的值。
例子如下:
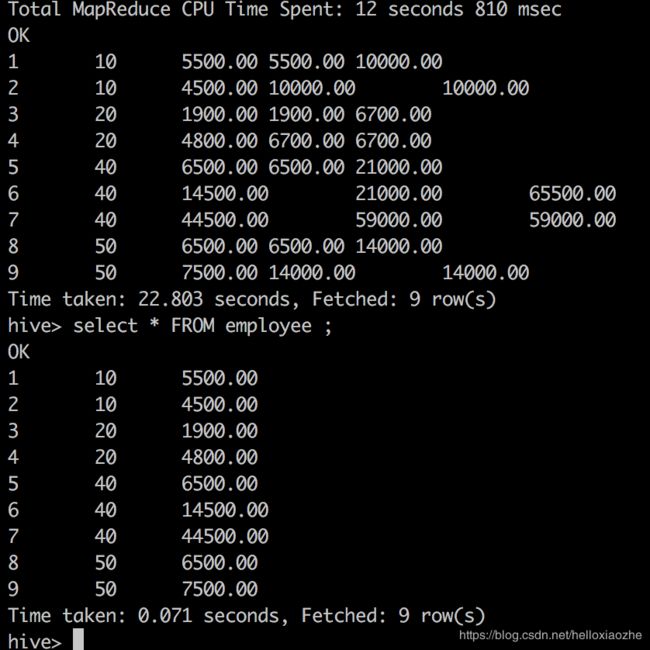
SELECT *,
SUM(a.salary) OVER (PARTITION BY deptid ORDER BY empid ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS total_salary1,
SUM(a.salary) OVER (PARTITION BY deptid ORDER BY empid ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS total_salary2
FROM employee AS a;
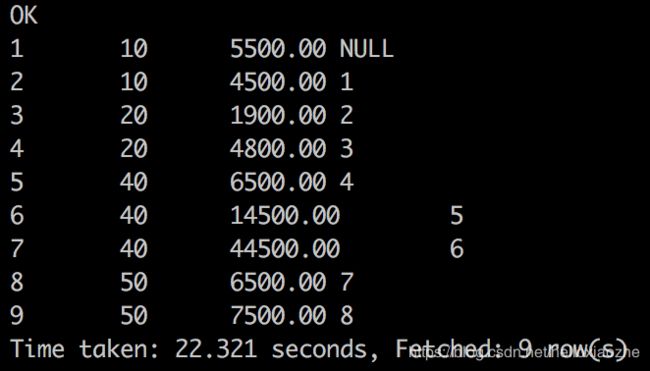
三、LAG、LEAD
获得相对于当前记录指定距离的那条记录的数据
LAG()为向前、LEAD()为向后
LAG(column_name1,1) OVER(ORDER BY column_name2)
LEAD(column_name1,1) OVER(ORDER BY column_name2)
这样就获得前一条、后一条的数据
select *,LAG(empid,1) over (order by empid asc) from employee;
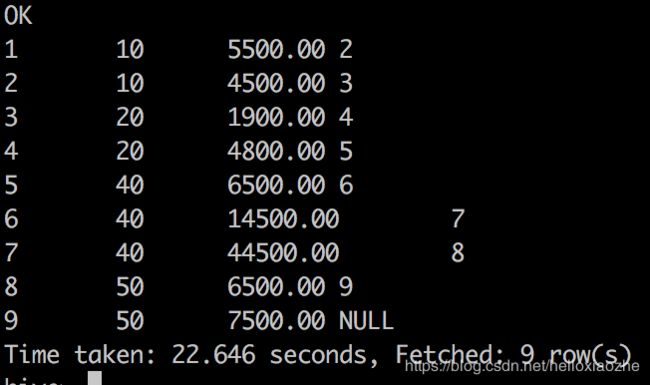
select *,LEAD(empid,1) over (order by empid asc) from employee;
四、FIRST、LAST
获得一个排序分组中的第一个值和组后一个值。可以与分组函数结合
SELECT
MIN(month) KEEP(DENSE_RANK FIRST ORDER BY SUM(amount)) AS highest_sales_month,
MIN(month) KEEP(DENSE_RANK LAST ORDER BY SUM(amount)) AS lows_sales_month
FROM table_name
GROUP BY month
ORDER BY month;
这样就可以求得一年中销量最高和最低的月份。
输出的是月份,但是用SUM(amount)来判断。
参考:https://yugouai.iteye.com/blog/1908121
https://www.jianshu.com/p/9fda829b1ef1
https://www.jianshu.com/p/9fda829b1ef1?from=timeline
https://blog.csdn.net/scgaliguodong123_/article/details/60135385