【Python机器学习】之 Boosting算法
Boosting
1、Boosting
1.1、Boosting算法
Boosting算法核心思想:

1.2、Boosting实例
使用Boosting进行年龄预测:
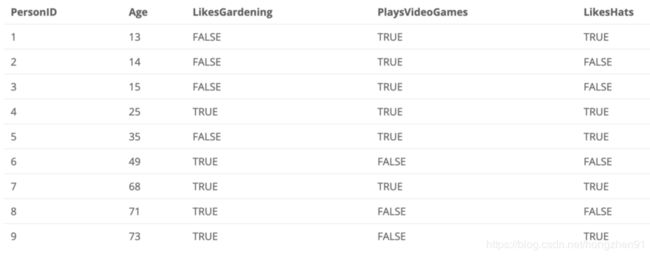

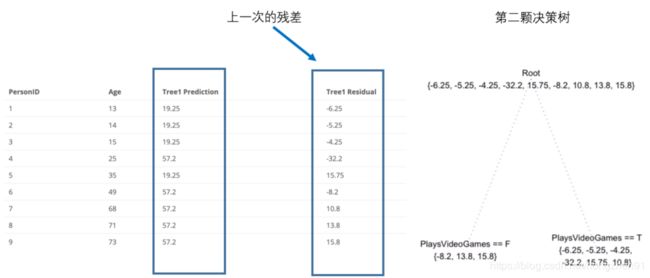

2、XGBoosting
XGBoost 是 GBDT 的一种改进形式,具有很好的性能。

2.1、XGBoosting 推导
经过 k 轮迭代后,GBDT/GBRT 的损失函数可以写成 L ( y , f k ( x ) ) L(y, f_k(x)) L(y,fk(x)),将 f k ( x ) f_k(x) fk(x)视为遍历(是一个复合型变量),对 L ( y , f k ( x ) ) L(y, f_k(x)) L(y,fk(x)) 在 f k − 1 ( x ) f_{k-1}(x) fk−1(x) 处进行二阶泰勒展开,可得:
L ( y , f k ( x ) ) ≈ L ( y , f k − 1 ( x ) ) + ∂ L ( y , f k − 1 ( x ) ) ∂ f k ( x ) [ f k ( x ) − f k − 1 ( x ) ] + 1 2 × ∂ 2 L ( y , f k − 1 ( x ) ) ∂ 2 f k − 1 ( x ) [ f k ( x ) − f k − 1 ( x ) ] 2 L(y, f_k(x)) \\ ≈ L(y, f_{k-1}(x) ) + \frac{\partial L(y, f_{k-1}(x) )}{\partial f_{k}(x)}[f_k(x) \ - f_{k-1}(x) ] \ + \ \frac{1}{2} × \frac{\partial ^2 L(y, f_{k-1}(x) )}{\partial ^2 f_{k-1}(x)}[f_k(x) \ - f_{k-1}(x) ]^2 L(y,fk(x))≈L(y,fk−1(x))+∂fk(x)∂L(y,fk−1(x))[fk(x) −fk−1(x)] + 21×∂2fk−1(x)∂2L(y,fk−1(x))[fk(x) −fk−1(x)]2
然后取 g = ∂ L ( y , f k − 1 ( x ) ) ∂ f k ( x ) g = \frac{\partial L(y, f_{k-1}(x) )}{\partial f_{k}(x)} g=∂fk(x)∂L(y,fk−1(x)) , h = ∂ 2 L ( y , f k − 1 ( x ) ) ∂ 2 f k ( x ) h = \frac{\partial ^2L(y, f_{k-1}(x) )}{\partial ^2f_{k}(x)} h=∂2fk(x)∂2L(y,fk−1(x)) ,即 g g g 和 h h h 分别代表一阶导数和二阶导数,所以,展开式可以变形得:
L ( y , f k ( x ) ) ≈ L ( y , f k − 1 ( x ) ) + g [ f k ( x ) − f k − 1 ( x ) ] + 1 2 h [ f k ( x ) − f k − 1 ( x ) ] 2 L(y, f_k(x)) ≈ L(y, f_{k-1}(x) ) + g[f_k(x) \ - f_{k-1}(x) ] \ + \ \frac{1}{2}h[f_k(x) \ - f_{k-1}(x) ]^2 L(y,fk(x))≈L(y,fk−1(x))+g[fk(x) −fk−1(x)] + 21h[fk(x) −fk−1(x)]2
又因为在 GBDT 中,利用前向分布算法,有 f k ( x ) = f k − 1 ( x ) + T k ( x ) f_k(x) \ = f_{k-1}(x) + T_k(x) fk(x) =fk−1(x)+Tk(x),即:
f k ( x ) − f k − 1 ( x ) = T k ( x ) f_k(x) \ - f_{k-1}(x) \ = T_k(x) fk(x) −fk−1(x) =Tk(x)
代入上式,可得:
L ( y , f k ( x ) ) ≈ L ( y , f k − 1 ( x ) ) + g ⋅ T k ( x ) + 1 2 h ⋅ T k 2 ( x ) L(y, f_k(x)) ≈ L(y, f_{k-1}(x) ) + g \cdot T_k(x) \ + \ \frac{1}{2}h \cdot T^2_k(x) L(y,fk(x))≈L(y,fk−1(x))+g⋅Tk(x) + 21h⋅Tk2(x)
上面的损失函数还是对于一个样本数据而言,对于整体样本数据,损失函数可得:
L = ∑ i = 1 N L ( y , f k ( x ) ) ≈ ∑ i = 1 N [ L ( y , f k − 1 ( x ) ) + g ⋅ T k ( x ) + 1 2 h ⋅ T k 2 ( x ) ] L = \sum\limits^N_{i=1} L(y, f_k(x)) ≈ \sum\limits^N_{i=1} [ L(y, f_{k-1}(x) ) + g \cdot T_k(x) \ + \ \frac{1}{2}h \cdot T^2_k(x) ] L=i=1∑NL(y,fk(x))≈i=1∑N[L(y,fk−1(x))+g⋅Tk(x) + 21h⋅Tk2(x)]
等式右边中的第一项 L ( y , f k − 1 ( x ) ) L(y, f_{k-1}(x) ) L(y,fk−1(x)) 只与前 k-1 轮有关,第 k 轮优化中可将该项视为常数。在 GBDT 中的损失函数上再加上一项与第 k 轮的基学习器 CART 决策树相关的正则化项 Ω ( T k ( x ) ) \Omega (T_k(x)) Ω(Tk(x)) 防止过拟合,可得到新的第 k 轮迭代时的等价损失函数:
L k = ∑ i = 1 N [ g i ⋅ T k ( x i ) + 1 2 h i ⋅ T k 2 ( x i ) ] + Ω ( T k ( x ) ) L_k = \sum\limits^N_{i=1} [ \ g_i \cdot T_k(x_i) \ + \ \frac{1}{2}h_i \cdot T^2_k(x_i) \ ] \ + \Omega (T_k(x)) Lk=i=1∑N[ gi⋅Tk(xi) + 21hi⋅Tk2(xi) ] +Ω(Tk(x))
所以, L k L_k Lk 就是 XGBoost 模型的损失函数。
假设第 k 棵 CART 回归树其对一个的叶子区域样本子集为 D k 1 , D k 2 , . . . , D k T D_{k1}, D_{k2}, ... ,D_{kT} Dk1,Dk2,...,DkT,且第 j j j 个小单元 D k j D_{kj} Dkj 中仍然包含 N k j N_{kj} Nkj 个样本数据,则计算每个小单元里面的样本的输出均值为:
c ‾ k j = 1 N k j ∑ x i ∈ D k j y i \overline c_{kj} = \frac{1}{N_{kj}}\sum\limits_{x_i \in D_{kj}} y_i ckj=Nkj1xi∈Dkj∑yi
得到:
T k ( x ) = ∑ j = 1 T c ‾ k j ⋅ I ( x i ∈ D k j ) T_k(x) = \sum\limits_{j=1}^T \overline c_{kj} \cdot I( x_i \in D_{kj} ) Tk(x)=j=1∑Tckj⋅I(xi∈Dkj)
正则化项 Ω ( T k ( x ) ) \Omega (T_k(x)) Ω(Tk(x)) 的构造如下:
Ω ( T k ( x ) ) = γ T + 1 2 γ ∑ j = 1 T c ‾ k j 2 \Omega (T_k(x)) = \gamma \ T + \frac{1}{2}\gamma \sum\limits_{j=1}^T \overline c_{kj}^2 Ω(Tk(x))=γ T+21γj=1∑Tckj2
其中, 参数 T T T 为 T k ( x ) T_k(x) Tk(x) 决策树的叶子节点的个数,参数 c ‾ k j , j = 1 , 2 , . . . , T \overline c_{kj} ,j=1,2,...,T ckj,j=1,2,...,T,是第 j j j 个叶子节点的输出均值; γ \gamma γ 和 λ \lambda λ 是两个权衡因子。叶子节点的数量及权重因子一起用来控制决策树模型的复杂度。
将 T k ( x ) T_k(x) Tk(x) 和 Ω ( T k ( x ) ) \Omega (T_k(x)) Ω(Tk(x)) 一起带入 L k L_{k} Lk ,可得:
L k = ∑ i = 1 N [ g i ⋅ T k ( x i ) + 1 2 h i ⋅ T k 2 ( x i ) ] + Ω ( T k ( x ) ) = ∑ i = 1 N [ g i ⋅ T k ( x i ) + 1 2 h i ⋅ T k 2 ( x i ) ] + γ T + 1 2 γ ∑ j = 1 T c ‾ k j 2 = ∑ i = 1 N [ ( ∑ x i ∈ D k j g i ) ⋅ c ‾ k j + 1 2 ( ∑ x i ∈ D k j h i + λ ) ( c ‾ k j ) 2 ] + γ T L_k = \sum\limits^N_{i=1} [ \ g_i \cdot T_k(x_i) \ + \ \frac{1}{2}h_i \cdot T^2_k(x_i) \ ] \ + \Omega (T_k(x)) \\ = \sum\limits^N_{i=1} [ \ g_i \cdot T_k(x_i) \ + \ \frac{1}{2}h_i \cdot T^2_k(x_i) \ ] \ +\gamma \ T + \frac{1}{2}\gamma \sum\limits_{j=1}^T \overline c_{kj}^2 \\ = \sum\limits^N_{i=1}[ (\sum\limits_{x_i \in D_{kj}}g_i)\cdot \overline c_{kj} + \frac{1}{2}(\sum\limits_{x_i \in D_{kj}} h_i + \lambda) (\overline c_{kj})^2] + \gamma \ T Lk=i=1∑N[ gi⋅Tk(xi) + 21hi⋅Tk2(xi) ] +Ω(Tk(x))=i=1∑N[ gi⋅Tk(xi) + 21hi⋅Tk2(xi) ] +γ T+21γj=1∑Tckj2=i=1∑N[(xi∈Dkj∑gi)⋅ckj+21(xi∈Dkj∑hi+λ)(ckj)2]+γ T
由上公式可知,XGBoost 模型对应的损失函数 L k L_k Lk 主要与原损失函数的一阶、二阶梯度在当前模型的值 g i 、 h i g_i 、h_i gi、hi 及第 k k k 棵 CART 树的叶子节点参数值 c ‾ k j \overline c_{kj} ckj 有关,而 g i 、 h i g_i 、h_i gi、hi 与第 k k k 轮迭代无关,所以将其当做常数,在要训练第 k k k 棵 CART 树,只需要考虑 c ‾ k j \overline c_{kj} ckj 参数。
对 c k j c_{kj} ckj 求导并令其导数等于 0 ,可得:
∂ L k ∂ c ‾ k j = ∑ j = 1 T [ ( ∑ x i ∈ D k j g i ) + ( ∑ x i ∈ D k j h i + λ ) ⋅ c ‾ k j ] = 0 \frac{\partial L_k}{\partial \overline c_{kj}} = \sum\limits^T_{j=1}[ (\sum\limits_{x_i \in D_{kj}}g_i) + (\sum\limits_{x_i \in D_{kj}} h_i + \lambda) \cdot \overline c_{kj}] = 0 \\ ∂ckj∂Lk=j=1∑T[(xi∈Dkj∑gi)+(xi∈Dkj∑hi+λ)⋅ckj]=0
c ‾ k j = − ∑ x i ∈ D k j g i ∑ x i ∈ D k j h i + λ \overline c_{kj} = -\frac{\sum\limits_{x_i \in D_{kj}}g_i}{\sum\limits_{x_i \in D_{kj}} h_i + \lambda} ckj=−xi∈Dkj∑hi+λxi∈Dkj∑gi
将其带入上式可得第 k k k 轮迭代时等价的损失函数为:
L k = − 1 2 ∑ j = 1 T [ ( ∑ x i ∈ D k j g i ) 2 ( ∑ x i ∈ D k j h i + λ ) ] + λ T L_k = - \frac{1}{2}\sum\limits^T_{j=1}[ \frac{(\sum\limits_{x_i \in D_{kj}}g_i)^2}{(\sum\limits_{x_i \in D_{kj}} h_i + \lambda)} ] + \lambda T Lk=−21j=1∑T[(xi∈Dkj∑hi+λ)(xi∈Dkj∑gi)2]+λT
实际上,第 k k k 轮迭代的损失函数的优化过程对应的就是第 k k k 棵树的分裂过程:每次分裂对应于将属于某个叶子结点下的训练样本分配到两个新的叶子节点上;而损失函数满足样本之间的累积性,所以可以通过将分裂前叶子节点上所有样本的损失函数与分裂之后两个新叶子节点上的样本的损失函数进行比较,以此作为各个特征分裂点的打分标准;最后选择一个生成该树的最佳分裂方案。
在实践中,当训练数据量较大时,不可能穷举出每一棵树进行打分来选择最好的,因为这个过程计算量太大。所以,通常采用贪心算法的方式来进行逐层选择最佳分裂点。假设一个叶子节点 I I I 分裂成两个新的叶子节点 I L I_L IL 和 I R I_R IR ,则该节点分裂产生的增益为:
G s p l i t = 1 2 [ ( ∑ x i ∈ I L g i ) 2 ( ∑ x i ∈ I L h i + λ ) + ( ∑ x i ∈ I R g i ) 2 ( ∑ x i ∈ I R h i + λ ) − ( ∑ x i ∈ I g i ) 2 ( ∑ x i ∈ I h i + λ ) ] − γ G_{split} = \frac{1}{2}[ \frac{(\sum\limits_{x_i \in I_{L}}g_i)^2}{(\sum\limits_{x_i \in I_{L}} h_i + \lambda)} + \frac{(\sum\limits_{x_i \in I_{R}}g_i)^2}{(\sum\limits_{x_i \in I_{R}} h_i + \lambda)} - \frac{(\sum\limits_{x_i \in I}g_i)^2}{(\sum\limits_{x_i \in I} h_i + \lambda)} ] - \gamma Gsplit=21[(xi∈IL∑hi+λ)(xi∈IL∑gi)2+(xi∈IR∑hi+λ)(xi∈IR∑gi)2−(xi∈I∑hi+λ)(xi∈I∑gi)2]−γ
上面的 G s p l i t G_{split} Gsplit 表示的就是一个叶子节点 I I I 按照某特征下的某分裂点分成两个新的叶子节点 I L I_L IL 和 I R I_R IR 后可以得到的“增益”,该增益值与模型的损失函数值成负相关关系(因为在损失函数的基础上取了负号),即该值越大,就表示按照该分裂方式分裂可以使模型的整体损失减小得越多。
所以,XGBoost 采用的是解析解思维,即对损失函数进行二阶泰勒展开,求得解析解,然后用这个解析解作为“增益”来辅助简历 CART 回归树,最终使得整体损失达到最优。
3、XGBoosting 实践
- 读取数据
import os
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import xgboost as xgb
df = pd.read_csv('LoanStats3a 2.csv',low_memory=False,skiprows=1)
print(df.shape)
df.head()
(42538, 144)
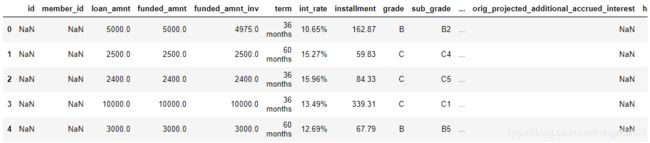
- 数据预处理
df = df.iloc[:,2:111] # 删掉很多空的列
empty_cols = [i for i in range(45,72)] # 删除更多的列
df = df.drop(df.columns[empty_cols],axis=1)
df.shapedf = df[(df['loan_status']=="Fully Paid") | (df['loan_status']=="Charged Off")]
df['loan_status'] = df['loan_status'].map({'Fully Paid':0, 'Charged Off':1})
df=df.dropna(axis=1) #340000 is minimum number of non-NA values
df
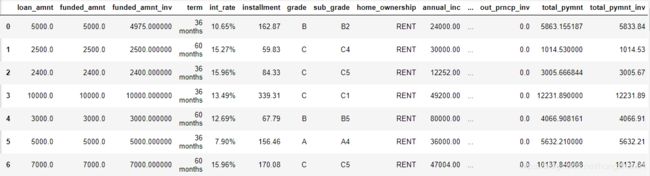
- 数据独热编码
df_grade = df['grade'].str.get_dummies().add_prefix('grade: ')
# 把类型独热编码
df_subgrad = df['sub_grade'].apply(str).str.get_dummies().add_prefix('sub_grade: ')
df_home = df['home_ownership'].apply(str).str.get_dummies().add_prefix('home_ownership: ')
df_addr = df['addr_state'].apply(str).str.get_dummies().add_prefix('addr_state: ')
df_term = df['term'].apply(str).str.get_dummies().add_prefix('term: ')
# 添加独热编码数据列
df = pd.concat([df, df_grade, df_subgrad, df_home, df_addr, df_term], axis=1)
# 去除独热编码对应的原始列
df = df.drop(['grade', 'sub_grade', 'home_ownership', 'addr_state', 'int_rate', 'term', 'zip_code','purpose','initial_list_status','initial_list_status','pymnt_plan','issue_d','earliest_cr_line','verification_status'], axis=1)
- 准备数据
# 准备数据
X = df.drop('loan_status', axis=1)
y = df['loan_status']
print (X.shape, y.shape)
(39786, 122) (39786,)
- 预测的实现
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
xg_classifier = xgb.XGBClassifier(objective ='binary:logistic', colsample_bytree = 0.3, learning_rate = 0.1,
max_depth = 5, alpha = 10, n_estimators = 10)
xg_classifier.fit(X_train,y_train)
xg_classifier.score(X_test, y_test)
0.9889419452123649
文中实例及参考:
- 《机器学习基础》
- 贪心学院,https://www.greedyai.com