hadoop2.7.2编译成功的一个配置
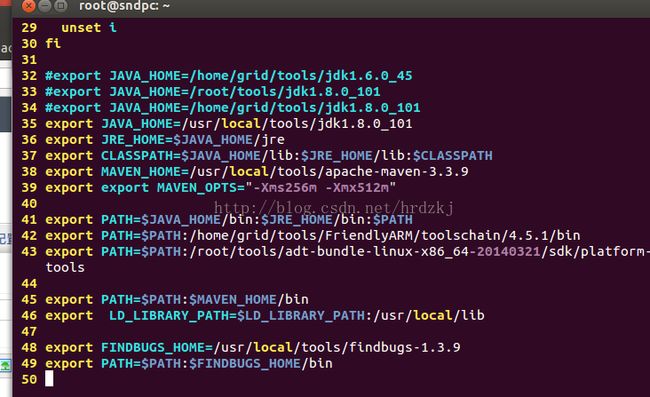
JDK1.8
protoc 2.5.0
findbugs1.3.9
mavent3.3.9
hadoop2.7.2源码
如下图:
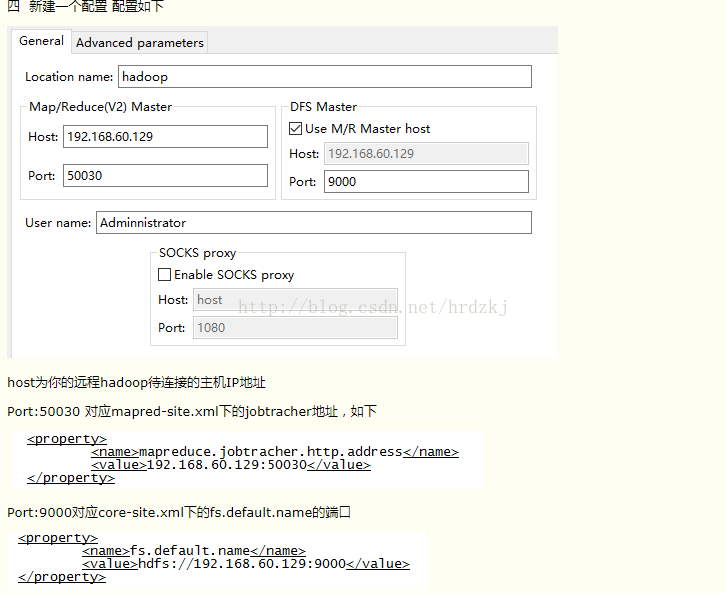
windows远程调试hadoop
--在hfds上执行ls
bin/hdfs dfs -ls /data/input
https://my.oschina.net/leejun2005/blog/122775
http://www.cnblogs.com/cstzhou/p/5495434.html
http://blog.csdn.net/skywalker_only/article/details/25539115
http://www.cnblogs.com/duking1991/p/6056923.html
加入文件:
http://blog.csdn.net/xiaoxiangzi222/article/details/52757168
hdfs 命令 http://blog.csdn.net/liuwenbo0920/article/details/43343983
8.向hadoop集群系统提交第一个mapreduce任务(wordcount)
进入本地hadoop目录(/usr/hadoop)
1、 bin/hdfs dfs -mkdir -p /data/input在虚拟分布式文件系统上创建一个测试目录/data/input
2、 hdfs dfs -put README.txt /data/input 将当前目录下的README.txt 文件复制到虚拟分布式文件系统中
3、 bin/hdfs dfs -ls /data/input 查看文件系统中是否存在我们所复制的文件
执行jar
bin/hadoop jar ~/code/wc.jar wordcount.WordCount /data/input ~/hadoopResult
yarn框架原理与运作机制 https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index.
index(index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置)
必备参数:输出,输入路径;类来自那个jar
setJarByClass---说明是设置的类是从那个jar过来的。
这里需要注意的是sequenceFile是二进制文件,cat more less 之类的命令都不能以文本形式显示顺序文件的内容,需要用到fs命令的-text选项,该选项可以查看文件的代码,检测出文件的类型并适当的转化成文本
http://lbingkuai.iteye.com/blog/1504130
job.setInputFormatClass(WholeFileInputFormat.class);----isSplitable,createRecordReader设置怎么样把splits分割成记录,同理
job.setOutputFormatClass(SequenceFileOutputFormat.class);---将用户提供的key/value对写入特定格式的文件中
**************************************************************************************************************************************
hdfs文件操作:http://blog.csdn.net/mmd0308/article/details/74276564
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//上传文件到hdfs上
fs.copyFromLocalFile(new Path("/home/hzq/jdk1.8.tar.gz"),new Path("/demo"));
//下载到本地
fs.copyToLocalFile(new Path("/java/jdk1.8.tar.gz"),new Path("/home/hzq/"));
// 删除hdfs上的文件
fs.delete(new Path("/demo/jdk1.8.tar.gz"),true);
//创建test1文件夹
fs.mkdirs(new Path("/test1"));
//列出hdfs上所有的文件或文件夹:
// “listFiles“列出的是hdfs上所有文件的路径,不包括文件夹。根据你的设置,支持递归查找。
//”listStatus“列出的是所有的文件和文件夹,不支持递归查找。如许递归,需要自己实现。
// true 表示递归查找 false 不进行递归查找
RemoteIterator
while (iterator.hasNext()){
LocatedFileStatus next = iterator.next();
System.out.println(next.getPath());
}
System.out.println("----------------------------------------------------------");
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (int i = 0; i < fileStatuses.length; i++) {
FileStatus fileStatus = fileStatuses[i];
System.out.println(fileStatus.getPath());
}